一、前期准备
1.获取headers
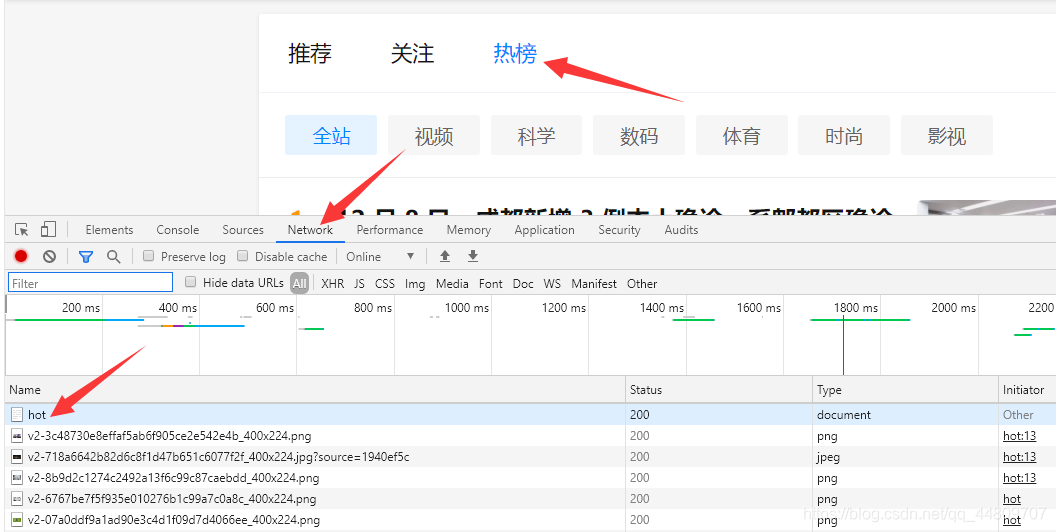
登录知乎官网知乎,点击热榜,按F12打开开发者工具。
点击Network,按ctrl+r重新加载,点击hot
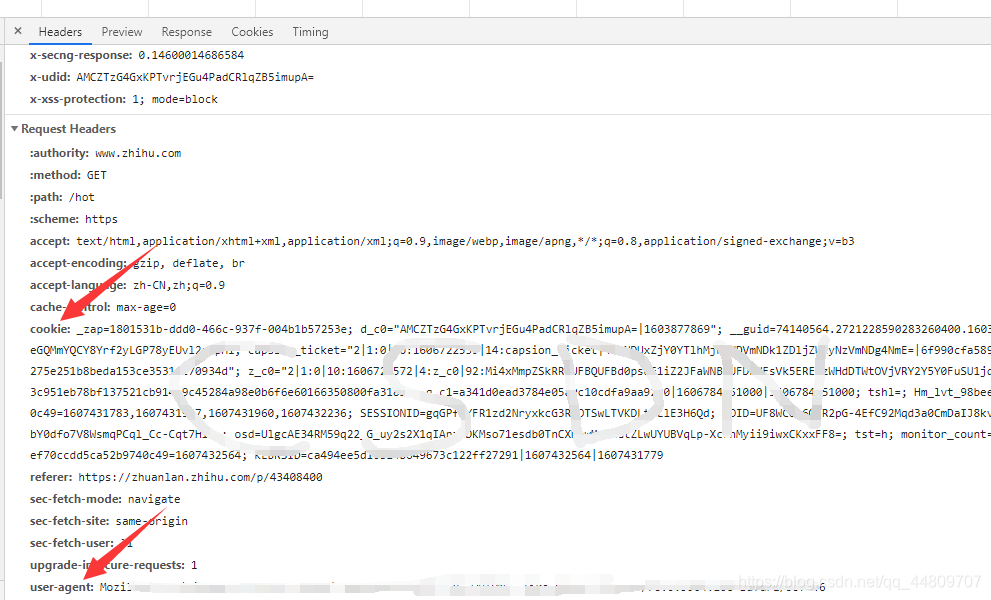
在Headers找到cookie和user-agent,把他们复制下来。
2.查看网页源代码
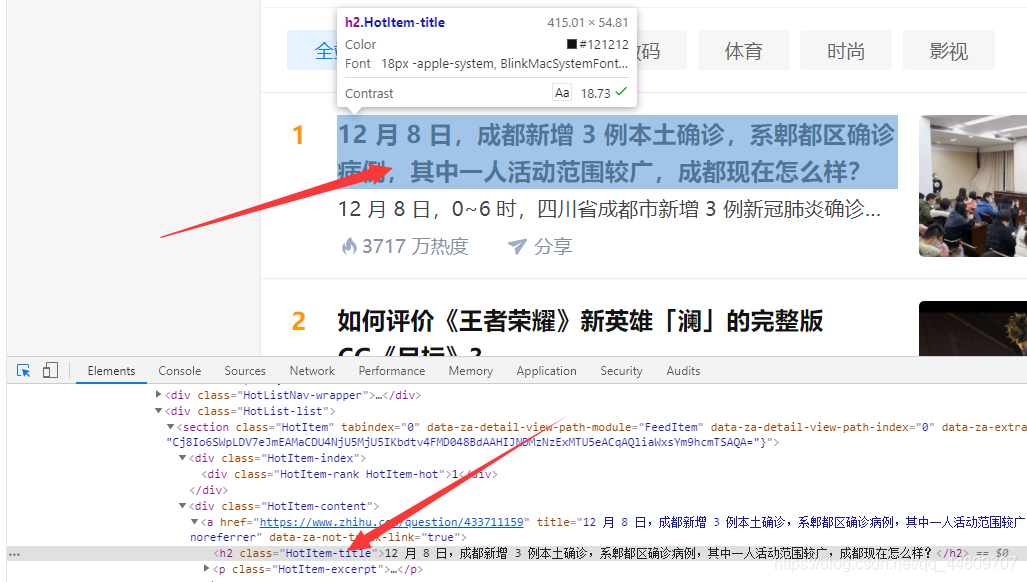
点击Elements,点击左边的箭头指向第一个热榜话题。
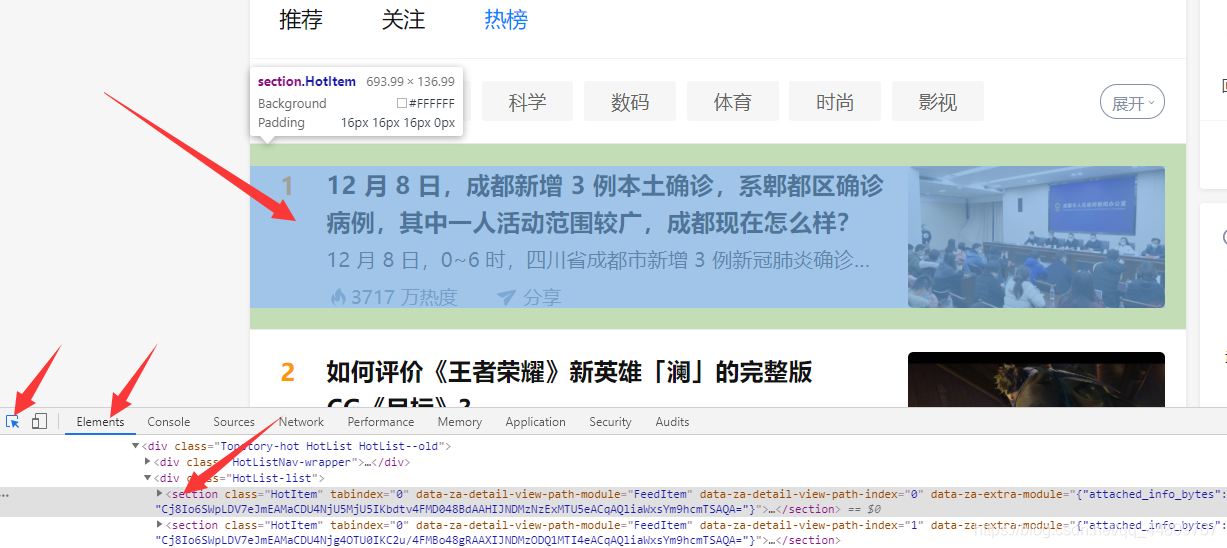
再分别看里面的元素标签(序号、标题、话题ID等)
这是序号:
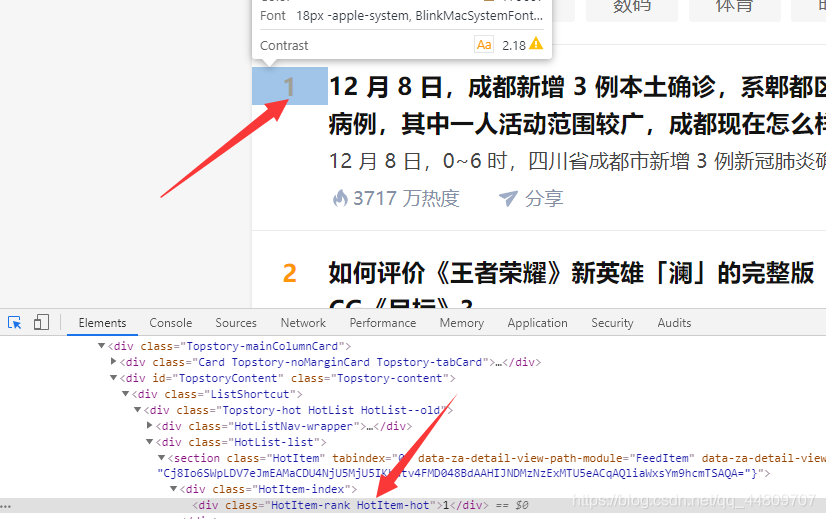
这是标题:
这是话题链接地址和话题ID:

二、python代码实现
1.解析网页
response = requests.get(url, headers=headers)
text = response.text
html = etree.HTML(text)#构造一个XPath解析对象并对HTML文本进行自动修正。
2.获取标签
number = question.xpath("./div[@class='HotItem-index']//text()")[0].strip()#问题Index
title = question.xpath(".//h2[@class='HotItem-title']/text()")[0].strip()#问题标题
href = question.xpath("./div[@class='HotItem-content']/a/@href")[0].strip()#问题链接
question_num = href.split('/')[-1]#取切割的最后一块,即问题ID
3.完整代码
import requests
from lxml import etree
headers={
'user-agent': '',
'cookie':'',
}
url = 'https://www.zhihu.com/hot'
def get_question_num(url,headers):
response = requests.get(url, headers=headers)
text = response.text
html = etree.HTML(text)#构造一个XPath解析对象并对HTML文本进行自动修正。
reslut = html.xpath("//section[@class='HotItem']")#选取所有section子元素,不管位置
question_list = []#问题列表(问题ID,问题标题)
for question in reslut[0:10]:#获取热榜前十
number = question.xpath("./div[@class='HotItem-index']//text()")[0].strip()#问题Index
title = question.xpath(".//h2[@class='HotItem-title']/text()")[0].strip()#问题标题
href = question.xpath("./div[@class='HotItem-content']/a/@href")[0].strip()#问题链接
question_num = href.split('/')[-1]#取切割的最后一块,即问题ID
question_list.append([question_num, title])
print(number,'\n',title,'\n',href)
return question_list
get_question_num(url,headers)
cookie和user-agent用自己的吧。
三、最终结果
