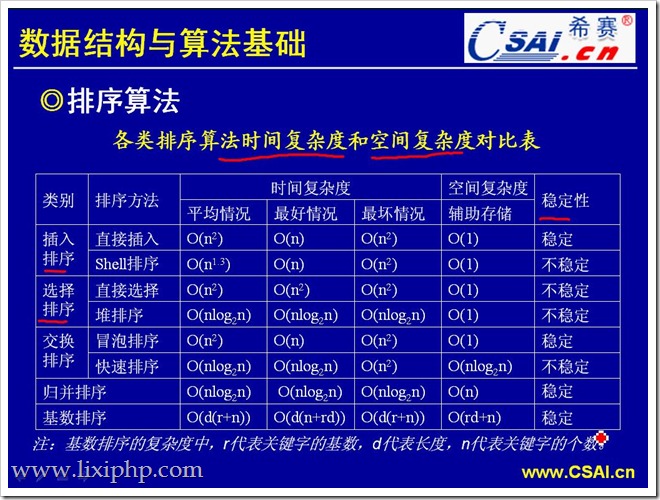
1. 说一下几种常见的排序算法和分别的复杂度。
排序大的分类可以分为两种:内排序和外排序。在排序过程中,全部记录存放在内存,则称为内排序,如果排序过程中需要使用外存,则称为外排序。下面讲的排序都是属于内排序。
内排序有可以分为以下几类:
(1)插入排序:直接插入排序、二分法插入排序、希尔排序。
(2)选择排序:简单选择排序、堆排序。
(3)交换排序:冒泡排序、快速排序。
(4)归并排序
(5)基数排序
图片:https://blog.csdn.net/Gane_Cheng/article/details/52652705
这些排序我刚好复习了一遍,代码都是测试过的☺
1)直接插入排序
基本思想:将数组中的所有元素依次跟前面已经排好的元素相比较,如果选择的元素比已排序的元素大,则后移一位,否则,将新元素插入到该位置上,直至全部元素都比较完成为止。因此该方法为稳定排序。
平均时间复杂度:O(n^2);
代码:
/**
* 插入排序
*
* 1. 从第一个元素开始,该元素可以认为已经被排序
* 2. 取出下一个元素,在已经排序的元素序列中从后向前扫描
* 3. 如果该元素(已排序)大于新元素,将该元素移到下一位置
* 4. 重复步骤3,直到找到已排序的元素小于或者等于新元素的位置
* 5. 将新元素插入到该位置后
* 6. 重复步骤2~5
* @param arr 待排序数组
*/
public static void insertSort(int[] array){
int i = 1;
while (i < array.length){
int temp = array[i];
int j;
for(j = i-1;j >= 0;j--){
if(array[j]>temp){
array[j+1] = array[j];
} else {
break;
}
}
array[j+1] = temp;
i++;
}
}
2)shell排序
基本思想:也称递减增量排序算法,1959年Shell发明。是插入排序的一种高速而稳定的改进版本。希尔排序是先将整个待排序的记录序列分割成为若干子序列分别进行直接插入排序,待整个序列中的记录“基本有序”时,再对全体记录进行依次直接插入排序。
希尔排序的作用就是使数据大体有序,然后再使用直接插入排序。这样会比直接插入排序快一些。
这里的分组是根据步长来的,比如步长为2,那么同一组的数据就是0,2,4,6......
平均时间复杂度:O(n^3/2);
为什么希尔排序是不稳定的呢?
- 虽然同一个分组内是稳定的,但不同分组之间顺序不能保证,因此是不稳定的。

代码:
/**
* 希尔排序(Wiki官方版)
*
* 1. 选择一个增量序列t1,t2,…,tk,其中ti>tj,tk=1;(注意此算法的gap取值)
* 2. 按增量序列个数k,对序列进行k 趟排序;
* 3. 每趟排序,根据对应的增量ti,将待排序列分割成若干长度为m 的子序列,分别对各子表进行直接插入排序。
* 仅增量因子为1 时,整个序列作为一个表来处理,表长度即为整个序列的长度。
* @param array 待排序数组
*/
public static void shell_sort(int[] array) {
int gap = 1, i, j, len = array.length;
int temp;
while (gap < len / 3) {
// <O(n^(3/2)) by Knuth,1973>: 1, 4, 13, 40, 121, ...
gap = gap * 3 + 1;
}
for (; gap > 0; gap /= 3) {
//直接插入排序
for (i = gap; i < len; i++) {
temp = array[i];
//从后向前依次进行比较,若值大于temp,则向后移位
for (j = i - gap; j >= 0 && array[j] > temp; j -= gap) {
array[j + gap] = array[j];
}
//找到小于等于temp的位置,插入temp()此处j+temp的原因是for中j-=gap
array[j + gap] = temp;
}
}
}3)简单选择排序
基本思想:在要排序的一组数中,选出最小的一个数与第一个位置的数交换;然后在剩下的数当中再找最小的与第二个位置的数交换,如此循环到倒数第二个数和最后一个数比较为止。
为什么选择排序是不稳定的呢?
平均时间复杂度:O(n^2);
- 因为选择排序的主要思想是交换元素,例如(7) 2 5 9 3 4 [7] 1排序时,(7)和1交换,此时(7)就跑到[7]后面了
/**
* 选择排序
*
* 1. 从待排序序列中,找到关键字最小的元素;
* 2. 如果最小元素不是待排序序列的第一个元素,将其和第一个元素互换;
* 3. 从余下的 N - 1 个元素中,找出关键字最小的元素,重复①、②步,直到排序结束。
*
* @param array 待排序数组
*/
public static void selectSort(int[] array) {
for (int i = 0; i < array.length; i++) {
int minIdx = i;
for (int j = i + 1; j < array.length; j++) {
//此处需要注意,array[minIdx]不要写成array[i]
if (array[j] < array[minIdx]) {
minIdx = j;
}
}
if (minIdx != i) {
int temp = array[minIdx];
array[minIdx] = array[i];
array[i] = temp;
}
}
}
4)堆排序
堆:堆是具有以下特性的完全二叉树:每个节点都大于或等于它的左右孩子
基本思想:以大顶堆为例,堆排序的过程就是将待排序的序列构造成一个堆,选出堆中最大的移走,再把剩余的元素调整成堆,找出最大的再移走,重复直至有序。
https://www.cnblogs.com/chengxiao/p/6129630.html
平均时间复杂度:O(nlogn);
代码:
从算法描述来看,堆排序需要两个过程,一是建立堆,二是堆顶与堆的最后一个元素交换位置。所以堆排序有两个函数组成。一是建堆函数,二是反复调用建堆函数以选择出剩余未排元素中最大的数来实现排序的函数。
/**
* 堆排序
*
* 1. 先将初始序列K[1..n]建成一个大顶堆, 那么此时第一个元素K1最大, 此堆为初始的无序区.
* 2. 再将关键字最大的记录K1 (即堆顶, 第一个元素)和无序区的最后一个记录 Kn 交换, 由此得到新的无序区K[1..n−1]和有序区K[n], 且满足K[1..n−1].keys⩽K[n].key
* 3. 交换K1 和 Kn 后, 堆顶可能违反堆性质, 因此需将K[1..n−1]调整为堆. 然后重复步骤②, 直到无序区只有一个元素时停止.
* @param arr 待排序数组
*/
public static void heapSort(int[] arr) {
//1.构建大顶堆
for (int i = arr.length / 2 - 1; i >= 0; i--) {
//从第一个非叶子结点从下至上,从右至左调整结构
adjustHeap(arr, i, arr.length);
}
//2.调整堆结构+交换堆顶元素与末尾元素
for (int j = arr.length - 1; j > 0; j--) {
//将堆顶元素与末尾元素进行交换
swap(arr, 0, j);
//重新对堆进行调整
adjustHeap(arr, 0, j);
}
}
/**
* 调整大顶堆(仅是调整过程,建立在大顶堆已构建的基础上)
*
* @param arr
* @param i
* @param length
*/
public static void adjustHeap(int[] arr, int i, int length) {
//先取出当前元素i
int temp = arr[i];
//从i结点的左子结点开始,也就是2i+1处开始
for (int k = i * 2 + 1; k < length; k = k * 2 + 1) {
//如果左子结点小于右子结点,k指向右子结点
if (k + 1 < length && arr[k] < arr[k + 1]) {
k++;
}
//如果子节点大于父节点,将子节点值赋给父节点
if (arr[k] > temp) {
arr[i] = arr[k];
i = k;
} else {
break;
}
}
//将temp值放到最终的位置
arr[i] = temp;
}
/**
* 交换元素
*
* @param arr
* @param a
* @param b
*/
public static void swap(int[] arr, int a, int b) {
int temp = arr[a];
arr[a] = arr[b];
arr[b] = temp;
}
5)冒泡排序
基本思想:冒泡排序(Bubble Sort)是一种简单的排序算法。它重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。走访数列的工作是重复地进行直到不再需要交换,也就是说该数列已经排序完成。这个算法的名字由来是因为越大的元素会经由交换慢慢“浮”到数列的顶端。
代码:
/**
* 冒泡排序
* 第一次次将最大的数冒泡到最后,第二次将第二大的数冒泡到倒数第二个位置,以此类推
* @param array
*/
public static void bubbleSort(int[] array){
//外层控制冒泡次数
for(int i=0;i<array.length-1;i++){
//-i是控制循环完成的数据不再进行比较
for(int j=0;j<array.length-1-i;j++){
if(array[j]>array[j+1]){
swap(array,j,j+1);
}
}
}
}6)快速排序
基本思想:挖坑填数+分治法。
首先选一个轴值(pivot,也有叫基准的),通过一趟排序将待排记录分隔成独立的两部分,其中一部分记录的关键字均比另一部分的关键字小,则可分别对这两部分记录继续进行排序,以达到整个序列有序。
平均时间复杂度:O(nlogn);
代码:
选一个轴值,维护两个指针i和j,一个指针i指向数组的第一个元素,一个指针j指向数组的最后一个元素,当array[j]>轴值时,j向前移动,记录当前array[j]<=轴值的j,然后array[i]<轴值时,i向后移动,记录当前array[i]>=轴值的i,交换i和j位置上的值,然后递归完成剩余元素。
public static void quickSort(int[] array, int left, int right) {
if (left > right) {
return;
}
int temp = array[left];
int j = right;
int i = left;
while (i < j) {
while (array[j] >= temp && i < j) {
j--;
}
while (array[i] <= temp && i < j) {
i++;
}
if (i < j) {
swap(array, i, j);
}
}
//最终将基准数归位
array[left] = array[i];
array[i] = temp;
quickSort(array, left, i - 1);
quickSort(array, i + 1, right);
}快速排序稍微顺序很重要,要先从右边开始找。
当i停下来时,a[i]的值大于基准数或走到了尽头。
当i没有走到尽头,也就是说i找到了一个大于基准的数,
接着j开始向左走,企图寻找一个小于基准的数,但是存在i < j这个条件的限制,j有可能没找到小于基准的数时就被迫停下来了,此时i==j的位置与基准数交换位置,结果就会出现错误。 当然,我们想从左开始并且正确也是可以的。改基准值为数组最右边即可
快速排序优化:三数取中
未优化:我们总是把数组尾元素固定为key的值,然后通过调整让key回到它正确的位置前快排
然后以key为中心,把数组划分为key左边和key右边两个区域,然后继续在左边的区域和右边划分区域,直到最后区域里没有元素或者只有一个元素的时候,排序结束
理想的是key的位置刚好在数组的中间,那么两边划分区域就快一点,但是如果key的值很小或者很大呢?那么左边或者右边至少有一边是没有元素的,这样效率就低了
思路:因为key的值最好每次都能把数组分成二分的两半,所以key的值最好是区域内比较居中的值,所以每次把区域内的首元素、尾元素、中间的元素做比较,选出不大不小的那个,然后把选出来的这个值,交换到数组的尾部,以便调整后它能回到数组中间的位置
https://blog.csdn.net/zcpvn/article/details/78150692
https://www.cnblogs.com/chengxiao/p/6262208.html
7)归并排序
基本思想:是利用归并的思想实现的排序方法,该算法采用经典的分治(divide-and-conquer)策略(分治法将问题分(divide)成一些小的问题然后递归求解,而治(conquer)的阶段则将分的阶段得到的各答案"修补"在一起,即分而治之)。
平均时间复杂度:O(nlogn);
/**
* 归并排序
* 将数组分成很小的单元,每个单元排序后,再将这两个单元合成一个有序的序列
* 递归完成
* @param array
* @param left
* @param right
* @param temp
*/
public static void mergeSort(int[] array,int left,int right,int[] temp){
if (left<right){
int mid = (left+right)/2;
mergeSort(array,left,mid,temp);
mergeSort(array,mid+1,right,temp);
merge(array,left,right,mid,temp);
}
}
public static void merge(int[] array ,int left,int right,int mid,int[] temp){
int i = left;
int j = mid+1;
int t = 0;
while (i<=mid && j<=right){
if(array[i]<=array[j]){
temp[t++] = array[i++];
}else {
temp[t++] = array[j++];
}
}
while (i<=mid){
temp[t++] = array[i++];
}
while (j<=right){
temp[t++] = array[j++];
}
t = 0;
//将temp中的元素全部拷贝到原数组中
while(left <= right){
array[left++] = temp[t++];
}
}https://www.cnblogs.com/chengxiao/p/6194356.html
8)基数排序
基本思想:是一种非比较型整数排序算法,其原理是将整数按位数切割成不同的数字,然后按每个位数分别比较。
排序过程:将所有待比较数值(正整数)统一为同样的数位长度,数位较短的数前面补零。然后,从最低位开始,依次进行一次排序。这样从最低位排序一直到最高位排序完成以后, 数列就变成一个有序序列。
基数排序法会使用到桶 (Bucket),顾名思义,通过将要比较的位(个位、十位、百位…),将要排序的元素分配至 0~9 个桶中,借以达到排序的作用,在某些时候,基数排序法的效率高于其它的比较性排序法。
实例分析:
基数排序的方式可以采用 LSD (Least sgnificant digital) 或 MSD (Most sgnificant digital),LSD 的排序方式由键值的最右边开始,而 MSD 则相反,由键值的最左边开始。 以 LSD 为例,假设原来有一串数值如下所示:
| 1 36 9 0 25 1 49 64 16 81 4 |
首先根据个位数的数值,按照个位置等于桶编号的方式,将它们分配至编号0到9的桶子中:
| 编号 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 64 | 25 | 36 | 9 | |||||
| 81 | 4 | 16 | 49 |
然后,将这些数字按照桶以及桶内部的排序连接起来:
| 0 1 81 64 4 25 36 16 9 49 |
接着按照十位的数值,分别对号入座:
| 编号 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 16 | 25 | 36 | 49 | 64 | 81 | ||||
| 1 | ||||||||||
| 4 | ||||||||||
| 9 |
最后按照次序重现连接,完成排序:
| 0 1 4 9 16 25 36 49 64 81 |
http://bubkoo.com/2014/01/15/sort-algorithm/radix-sort/
代码:
/**
* 基数排序
* 将整数按位数切割成不同的数字,然后按每个位数分别比较
*
* @param array
* @param radix 基数:十进制为10radix = 10;
*/
public static void radisSort(int[] array, int radix) {
int[][] bucket = new int[radix][array.length];
int maxDigit = getMaxDigit(array);
int divisor = 1;
int currentDigit = 1;
while (currentDigit <= maxDigit) {
// 用来计数:数组counter[i]用来表示该位是i的数的个数
//因为每个位置上可能有多个数据,因此使用一个数组记录位置上的元素数
int[] counter = new int[radix];
// 将array中元素分布填充到bucket中,并进行计数
for (int i = 0; i < array.length; i++) {
int which = (array[i] / divisor) % radix;
bucket[which][counter[which]] = array[i];
counter[which]++;
}
int index = 0;
// 根据bucket中收集到的array中的元素,根据统计计数,在array中重新排列
for (int i = 0; i < radix; i++) {
if (counter[i] != 0) {
for (int j = 0; j < counter[i]; j++) {
array[index] = bucket[i][j];
index++;
}
}
counter[i] = 0;
}
divisor *= radix;
currentDigit++;
}
}
public static int getMaxDigit(int[] array) {
int maxNum = getMaxNum(array);
int[] sizeTable = {9, 99, 999, 9999, 99999, 999999, 9999999,
99999999, 999999999, Integer.MAX_VALUE};
for (int i = 0; ; i++) {
if (maxNum <= sizeTable[i]) {
return i + 1;
}
}
}
public static int getMaxNum(int[] array) {
int maxNum = array[0];
for (int i = 0; i < array.length; i++) {
if (array[i] > maxNum) {
maxNum = array[i];
}
}
return maxNum;
}
9)最后在看jdk源码时,发现了二分插入排序,主要讲一下原理吧。一个数插入到一个有序的数组中时,先根据数组的中间元素比较,大于中间元素向右找,小于中间元素向左找,其实就是二分查找合适的位置插入。以下为jdk源码
private static void binarySort(Object[] a, int lo, int hi, int start) {
assert lo <= start && start <= hi;
//start为第一个未排序字段的位置
if (start == lo)
start++;
for ( ; start < hi; start++) {
Comparable pivot = (Comparable) a[start];
// Set left (and right) to the index where a[start] (pivot) belongs
int left = lo;
int right = start;
assert left <= right;
/*
* Invariants:
* pivot >= all in [lo, left).
* pivot < all in [right, start).
* 这里找到未排序字段在排序字段中的位置
*/
while (left < right) {
int mid = (left + right) >>> 1;
if (pivot.compareTo(a[mid]) < 0)
right = mid;
else
left = mid + 1;
}
assert left == right;
/*
* The invariants still hold: pivot >= all in [lo, left) and
* pivot < all in [left, start), so pivot belongs at left. Note
* that if there are elements equal to pivot, left points to the
* first slot after them -- that's why this sort is stable.
* Slide elements over to make room for pivot.
*/
//排序的字段中,插入字段后面的字段向后移动
int n = start - left; // The number of elements to move
// Switch is just an optimization for arraycopy in default case
switch (n) {
case 2: a[left + 2] = a[left + 1];
case 1: a[left + 1] = a[left];
break;
default: System.arraycopy(a, left, a, left + 1, n);
}
a[left] = pivot;
}
}java中的排序?
jdk8中主要使用的方法是
ComparableTimSort.sort(a, 0, a.length, null, 0, 0);当元素个数少于32时,使用不带merge的mini-TimSort排序,对应的方法为9)中的binarySort
否则,使用TimSort排序(带归并的)。
binarySort基本思路:
1. 我们先找到这个序列中从第一个位置开始的非严格升序(可以接受等于的情况,文章中后面简称升序)或者严格降序(不能接受等于的情况, 文章中后面简称降序)。比如对集合{7,4,2,1,1,3,5}进行排序。我发现从第一个元素开始是一个降序。那么我把集合分割成下面两个字集合。{7,4,2,1}{1,3,5}。因为严格降序,第5个元素1,被划入后一个集合。
2. 反转集合{7,4,2,1}->{1,2,4,7}如果为降序,反转集合
3. 把剩下的部分{1,3,5}用二分插入的方式插入已经排好序列的{1,2,4,7}中。
Timsort是结合了合并排序(merge sort)和插入排序(insertion sort)而得出的排序算法。算法找到数据中已经排好序的块-分区,每一个分区叫一个run,然后按规则合并这些run。当元素个数少于32,使用二分插入排序,不用合并。分区有序后,使用二分插入排序将两个run合并成一个run,直到整个run有序。
https://blog.csdn.net/yangzhongblog/article/details/8184707
2. 什么是跳表?
跳表(skip list) 对标的是平衡树(AVL Tree),是一种 插入/删除/搜索 都是 O(log n) 的数据结构。它最大的优势是原理简单、容易实现、方便扩展、效率更高。因此在一些热门的项目里用来替代平衡树,如 redis, leveldb 等。(前提是有序的集合)
(1)基本思想
每一个结点不单单只包含指向下一个结点的指针,可能包含很多个指向后续结点的指针,这样就可以跳过一些不必要的结点,从而加快查找、删除等操作。对于一个链表内每一个结点包含多少个指向后续元素的指针,这个过程是通过一个随机函数生成器得到,这样就构成了一个跳跃表。
redis中只有有序集合使用了该数据结构
我们先来看看这张图:

如果要在这里面找 21 ,过程为 3→ 6 → 7 → 9 → 12 → 17 → 19 → 21 。
我们考虑从中抽出一些节点,建立一层索引作用的链表:

跳表的主要思想就是这样逐渐建立索引,加速查找与插入。
一般来说,如果要做到严格 O(logn) ,上层结点个数应是下层结点个数的 1/2 。但是这样实现会把代码变得十分复杂,就失去了它在 OI 中使用的意义。
此外,我们在实现时,一般在插入时就确定数值的层数,而且层数不能简单的用随机数,而是以1/2的概率增加层数。
用实验中丢硬币的次数 K 作为元素占有的层数。显然随机变量 K 满足参数为 p = 1/2 的几何分布,K 的期望值 E[K] = 1/p = 2. 就是说,各个元素的层数,期望值是 2 层。
同时,为了防止出现极端情况,设计一个最大层数MAX_LEVEL。如果使用非指针版,定义这样一个常量会方便许多,更能节省空间。如果是指针版,可以不加限制地任由它增长。
(2)随机层数
r.nextInt() % 2 == 1表示这个随机数为奇数,那么随机生成一个随机数为奇数和偶数的概率是相同的,那么生成结果为1的概率为1/2,生成结果为2的概率为1/4,3的概率为1/8以此论推。
private int randomLevel() {
int level = 1;
while (r.nextInt() % 2==1 && level <= MAX_LEVEL)
++level;
return level;
}(3)存储结构:
public class Node<E> {
private E data ;
private Node<E>[] forwards;
private int maxLevel;
public Node() {
forwards = new Node[MAX_LEVEL];
maxLevel = 0;
}
@Override
public String toString() {
StringBuilder builder = new StringBuilder();
builder.append("{ data: ");
builder.append(data);
builder.append("; levels: ");
builder.append(maxLevel);
builder.append(" }");
return builder.toString();
}
}forward[i]表示当前节点第i层的后续节点
(4)插入新结点
思路:生成新增节点的层数,然后,每一层开始遍历:找到小于新结点值的最大节点,这个节点就是插入节点的前置节点。当前节点的后置节点为前置节点的后置节点(这一步要在前面,否则找不到前置节点的后置节点了),修改前置节点的后续节点为当前节点。
例子:插入 119, K = 2

public void insert(E value) {
int level = randomLevel();
Node newNode = new Node();
newNode.data = value;
newNode.maxLevel = level;
Node update[] = new Node[level];
//更新跳表最大层数
if (levelCount < level){
levelCount = level;
}
for (int i = 0; i < level; ++i) {
update[i] = head;
}
//插入方向由上到下,每一层都要插入
//每一层找到插入前一个节点后,
//先取到前一个节点的forward[i],因为前一个节点forwards[i]将更新到newNode上1
//再将前一个节点的forwards[i]更新到new2
Node<E> p = head;
for (int i = level - 1; i >= 0; --i) {
while (p.forwards[i] != null && p.forwards[i].data.compareTo(value)<0) {
p = p.forwards[i];
}
update[i] = p;
//1
newNode.forwards[i] = update[i].forwards[i];
//2
update[i].forwards[i] = newNode;
}
}(5)删除结点
从最高层层开始遍历:找到删除节点的前一个节点,将前一个节点的后续节点连接到当前节点的后续节点中即可,每一层都这么做
public void delete(E value) {
Node<E>[] update = new Node[levelCount];
Node<E> p = head;
for (int i = levelCount - 1; i >= 0; --i) {
while (p.forwards[i] != null && p.forwards[i].data.compareTo(value)<0 ) {
p = p.forwards[i];
}
update[i] = p;
}
//找到了再删除
if (p.forwards[0] != null && p.forwards[0].data == value) {
for (int i = levelCount - 1; i >= 0; --i) {
if (update[i].forwards[i] != null && update[i].forwards[i].data.compareTo(value)==0) {
update[i].forwards[i] = update[i].forwards[i].forwards[i];
}
}
}
}(6)查找
从最上层开始,找到每一层中最大比查找的值小的数,在最后一层中判断 最后一层的下一个数是否与查找的值相等
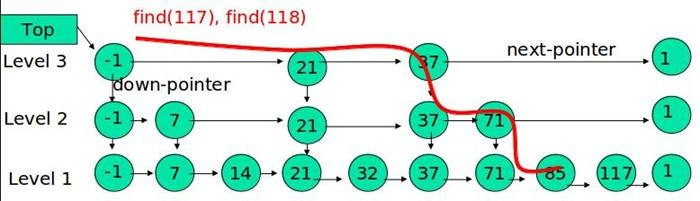
public Node find(E value) {
Node<E> p = head;
//找到最后一层中最大比查找的值小的数
for (int i = levelCount - 1; i >= 0; --i) {
//层次减一后,每次从上次节点的i层开始向后查找
while (p.forwards[i] != null && p.forwards[i].data.compareTo(value)<0) {
p = p.forwards[i];
}
}
//最后一层的下一个数是否与查找的值相等
if (p.forwards[0] != null && p.forwards[0].data == value) {
return p.forwards[0];
} else {
return null;
}
}(7)空间复杂度
原始链表大小为n ,那么第1层索引大约有n/2个节点,第2层有n /4 个节点,依次类推,直到最后剩下2个节点,总数为: n/2 + n /4 + n /8 + . . . + 8 + 4 + 2 = n − 2 ,因此空间复杂度是O ( n )
这篇文章是c++写的,我后面按照思路,改成的java版本
https://www.cnblogs.com/lfri/p/9991925.html
java完整代码
package com.example.questionspractice;
import java.util.Random;
public class SkipList<E extends Comparable<? super E>> {
//测试代码
public static void main(String[] args) {
int[] values = {1, 3, 5,6, 9, 10, 11};
SkipList<Integer> list = new SkipList<Integer>();
for (int value : values) {
list.insert(value);
}
System.out.println("before remove:");
list.printAll();
System.out.println();
for (int value : values) {
list.delete(value);
System.out.println("remove: " + value);
list.printAll();
System.out.println();
}
}
private static final int MAX_LEVEL = 3;
//跳表的最大层数
private int levelCount = 1;
// 带头链表
private Node<E> head = new Node<>();
private Random r = new Random();
//第三步:查找
public Node find(E value) {
Node<E> p = head;
//找到最后一层中最大比查找的值小的数
for (int i = levelCount - 1; i >= 0; --i) {
//层次减一后,每次从上次节点的i层开始向后查找
while (p.forwards[i] != null && p.forwards[i].data.compareTo(value)<0) {
p = p.forwards[i];
}
}
//最后一层的下一个数是否与查找的值相等
if (p.forwards[0] != null && p.forwards[0].data == value) {
return p.forwards[0];
} else {
return null;
}
}
//第四步:添加
public void insert(E value) {
int level = randomLevel();
Node newNode = new Node();
newNode.data = value;
newNode.maxLevel = level;
Node update[] = new Node[level];
//更新跳表最大层数
if (levelCount < level){
levelCount = level;
}
for (int i = 0; i < level; ++i) {
update[i] = head;
}
//插入方向由上到下,每一层都要插入
//每一层找到插入前一个节点后,
//先取到前一个节点的forward[i],因为前一个节点forwards[i]将更新到newNode上1
//再将前一个节点的forwards[i]更新到new2
Node<E> p = head;
for (int i = level - 1; i >= 0; --i) {
while (p.forwards[i] != null && p.forwards[i].data.compareTo(value)<0) {
p = p.forwards[i];
}
update[i] = p;
//1
newNode.forwards[i] = update[i].forwards[i];
//2
update[i].forwards[i] = newNode;
}
}
//第五步:删除
//找到删除节点的前一个节点,将前一个节点的后续节点连接到当前节点的后续节点中即可,每一层都这么做
public void delete(E value) {
Node<E>[] update = new Node[levelCount];
Node<E> p = head;
for (int i = levelCount - 1; i >= 0; --i) {
while (p.forwards[i] != null && p.forwards[i].data.compareTo(value)<0 ) {
p = p.forwards[i];
}
update[i] = p;
}
//找到了再删除
if (p.forwards[0] != null && p.forwards[0].data == value) {
for (int i = levelCount - 1; i >= 0; --i) {
if (update[i].forwards[i] != null && update[i].forwards[i].data.compareTo(value)==0) {
update[i].forwards[i] = update[i].forwards[i].forwards[i];
}
}
}
}
/**
* 第二步:生成随机层数[0,maxLevel)
* 如果是奇数层数 +1,防止伪随机
* 第一层的概率是1.第二层的概率是1/2,第三层的概率是1/4
*/
private int randomLevel() {
int level = 1;
while (r.nextInt() % 2==1 && level <= MAX_LEVEL)
++level;
return level;
}
public void printAll() {
Node p = head;
while (p.forwards[0] != null) {
System.out.print(p.forwards[0] + " ");
p = p.forwards[0];
}
System.out.println();
}
//第一步
public class Node<E> {
private E data ;
private Node<E>[] forwards;
private int maxLevel;
public Node() {
forwards = new Node[MAX_LEVEL];
maxLevel = 0;
}
@Override
public String toString() {
StringBuilder builder = new StringBuilder();
builder.append("{ data: ");
builder.append(data);
builder.append("; levels: ");
builder.append(maxLevel);
builder.append(" }");
return builder.toString();
}
}
}3. 如何确认一个链表有环?进一步,确认环的位置。
第一种办法:使用hashmap记录遍历过的节点,当hashmap中有存在的节点时,退出遍历,确认有环,也找到了环的入口。
public boolean hasCycle(ListNode head) {
Set<ListNode> nodesSeen = new HashSet<>();
while (head != null) {
if (nodesSeen.contains(head)) {
return true;
} else {
nodesSeen.add(head);
}
head = head.next;
}
return false;
}
第二种办法:快慢指针,想象一下,如果链表有环,那么快的指针总会追上慢的指针。如果快指针走到了尽头,那么链表没有环。假设慢指针走一步,快指针走两步。
public boolean hasCycle(ListNode head) {
//单链表要两个及以上个元素才能构成环
if (head == null || head.next == null) {
return false;
}
ListNode slow = head;
ListNode fast = head.next;
while (slow != fast) {
//快指针走到了尽头,那么一定没有环
if (fast == null || fast.next == null) {
return false;
}
slow = slow.next;
fast = fast.next.next;
}
return true;
}
那怎么确认环的位置呢?
在找到了相遇点后,怎么找到环形的入口呢?(下图顺时针遍历)
假设:快指针走了f步,慢指针走了s步。开始节点到环形入口长度为a,环形长度为b.
假设我们有两个指针,一个指向头指针,一个指向相遇点。
(1)快指针走的距离是慢指针的两倍得
f=2s;
(2)快指针比慢指针多走n个环的步数
f=s+nb
由(1)(2)两个式子运算得s=nb,f=2nb;
(3)找环形的入口位置
入口位置为k=a+nb;
nb刚好为慢指针的步数,因此在找到相遇的位置后,慢指针再走a步就会到达环形入口,那么a步应该要怎么找呢?
(我们使用双指针的方式,用一个指针计数,另一个指针向后走)从开始节点开始走a步就找到了环形的入口,两个指针同时到达入口,就会相遇。
(头指针向前走,相遇指针向前走,当两个指针相遇时就是环形的入口)

private ListNode getIntersect(ListNode head) {
ListNode tortoise = head;
ListNode hare = head;
// A fast pointer will either loop around a cycle and meet the slow
// pointer or reach the `null` at the end of a non-cyclic list.
while (hare != null && hare.next != null) {
tortoise = tortoise.next;
hare = hare.next.next;
if (tortoise == hare) {
return tortoise;
}
}
return null;
}
public ListNode detectCycle(ListNode head) {
if (head == null) {
return null;
}
// If there is a cycle, the fast/slow pointers will intersect at some
// node. Otherwise, there is no cycle, so we cannot find an e***ance to
// a cycle.
ListNode intersect = getIntersect(head);
if (intersect == null) {
return null;
}
// To find the e***ance to the cycle, we have two pointers traverse at
// the same speed -- one from the front of the list, and the other from
// the point of intersection.
ListNode ptr1 = head;
ListNode ptr2 = intersect;
while (ptr1 != ptr2) {
ptr1 = ptr1.next;
ptr2 = ptr2.next;
}
return ptr1;
}
https://leetcode-cn.com/problems/linked-list-cycle-ii/solution/huan-xing-lian-biao-ii-by-leetcode/
4. 如何遍历一棵二叉树?
一 深度优先遍历:
有三种方式,前序遍历,中序遍历,后续遍历,这三种方式以根节点的先后访问顺序,例如先访问根节点,再左子树,最后右子树,这种访问方式为前序遍历
首先是递归的方式
public class TreeTraverse {
public class Tree{
Tree left;
Tree right;
int data;
}
public void preOrderTraverse(Tree root){
if(root == null){
return;
}
System.out.println(root.data);
preOrderTraverse(root.left);
preOrderTraverse(root.right);
}
public void inOrderTraverse(Tree root){
if(root == null){
return;
}
preOrderTraverse(root.left);
System.out.println(root.data);
preOrderTraverse(root.right);
}
public void postOrderTraverse(Tree root){
if(root == null){
return;
}
preOrderTraverse(root.left);
preOrderTraverse(root.right);
System.out.println(root.data);
}
}
其次是非递归方式
前序遍历算法核心:先把根节点放到栈中,随后取出并删除栈顶节点,再放右节点,最后放左节点;下一次循环时会将左节点取出并删除,并把左节点的两个子节点放进栈中,实现了左子树先打印完成再打印右子树的功能。当栈为空时,循环结束。
中序遍历算法核心:先遍历找最左边的节点,如果这个节点为空,则取出栈顶元素,同时,如果右子节点不为空,则将右子节点入栈,如果右子节点为空,继续取出栈顶元素,该元素其实为下一个要遍历的根节点(其实下一个节点为空时,证明前面已经遍历完成了,当前根节点节点如果有右子节点,那么再将该子树遍历完成即可)
后续遍历算法核心:先遍历到最后一个左子树节点,如果这个节点没有右子树,则直接取出并删除该节点,如果这个节点有右子树,那么先取出并删除该节点后再将右子树入栈。
public static void BFS_posOrder(Tree root){
//Deque<Tree> stack = new ArrayDeque<>();
LinkedList<Tree> stack = new LinkedList<>();
// 最后一个访问 visit 的节点
Tree lastVisited = null;
while (!stack.isEmpty() || root != null) {
if (root != null) {
stack.addFirst(root);
root = root.left;
} else {
Tree peekNode = stack.peekFirst();
// 判断该节点的右子节点是否已访问
if (peekNode.right != null && lastVisited != peekNode.right) {
root = peekNode.right;
} else {
visit(peekNode);
lastVisited = stack.removeFirst();
}
}
}
}
public static void BFS_preOrder(Tree root) {
if (root == null) {
return;
}
Deque<Tree> stack = new ArrayDeque<Tree>();
stack.addFirst(root);
while (!stack.isEmpty()) {
Tree node = stack.removeFirst();
visit(node);
if (node.right != null) {
stack.addFirst(node.right);
}
if (node.left != null) {
stack.addFirst(node.left);
}
}
}
public static void BFS_inOrder(Tree root) {
Deque<Tree> stack = new ArrayDeque<Tree>();
while (!stack.isEmpty() || root != null) {
if (root != null) {
stack.addFirst(root);
root = root.left;
} else {
root = stack.removeFirst();
visit(root);
root = root.right;
}
}
}二 广度优先遍历:
层次遍历:从根结点开始按层次遍历,每层按照从左到右的顺序遍历。

public void levelTraverse(Tree root) {
if (root == null) {
return;
}
LinkedList<Tree> queue = new LinkedList<>();
queue.offer(root);
while (!queue.isEmpty()) {
Tree node = queue.poll();
visit(node);
if (node.left != null) {
queue.offer(node.left);
}
if (node.right != null) {
queue.offer(node.right);
}
}
}
5. 倒排一个LinkedList。
首先在java中LinkedList是一个无环的双向链表。listIterator中index参数是定位到第index位置开始的遍历开始节点,因此,将index设置为最后一个节点,从后向前遍历即可完成倒排。
public ListIterator<E> listIterator(int index) {
checkPositionIndex(index);
return new ListItr(index);
}
/**
* 倒排LinkedList
**/
public void reverse(LinkedList<Integer> data){
ListIterator<Integer> iterator = data.listIterator(data.size());
while (iterator.hasPrevious()){
System.out.println(iterator.previous());
}
}如果自己实现的单链表数据结构,那么可以使用递归的方式实现。
递归实现:因为递归和栈一样,都是底层结果输出后再输出上层结果,因此可以在链表长度不是很大时可以使用递归实现。
也可以更改节点的指针来实现:遍历到当前节点时,将后当前节点指向当前节点的前一个节点,并将当前节点设为previous节点,下一个节点为当前节点
class Node {
char value;
Node next;
}
//非递归实现
public Node reverse(Node current) {
Node previous = null;
Node next = null;
while (current != null) {
//存储下一节点
next = current.next;
current.next = previous;
//更新遍历节点
previous = current;
current = next;
}
return current;
}
//递归
public Node reverse_rec(Node current) {
if (current == null || current.next == null) { return current; }
Node nextNode = current.next;
current.next = null;
Node reverseRest = reverse(nextNode);
nextNode.next = current;
return reverseRest;
}6. HashSet的实现方式
继承set接口,且不保证元素之间的顺序,允许存储null值,没有重复元素。
Hashset是基于hashmap实现的,底层采用hashmap保存数据。其不可重复性是由添加元素时,将元素放到key位置上实现的,当map.put("当前元素",PRESENT)==null时,证明该元素没有添加过,证明该元素添加到set中成功了,否则是失败的!
public HashSet(int initialCapacity, float loadFactor) {
map = new HashMap<>(initialCapacity, loadFactor);
}
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}