1.数据结构中的树和机器学习中的树对比
现实生活中树:
- 树根-------树干-------树枝----树叶
数据结构树:
- 根据人的习惯将现实生活中的树进行翻转
- 先树根
- 在树枝
- 在树叶
机器学习中的树:
- 1-叶子节点和分支节点(树根是特殊的分支节点)

2. 什么是决策树?
简介: 决策树是机器学习中分类方法中的一个重要算法;是一个类似于流程图的树结构:其中,每个内部结点表示一个特征或属性,而每个树叶结点代表一个分类。树的最顶层是根结点。使用决策树分类时就是将实例分配到叶节点的类中。该叶节点所属的类就是该节点的分类。
比如:你母亲要给你介绍男朋友,是这么来对话的:
女儿:多大年纪了?
母亲:26。
女儿:长的帅不帅?
母亲:挺帅的。
女儿:收入高不?
母亲:不算很高,中等情况。
女儿:是公务员不?
母亲:是,在税务局上班呢。
女儿:那好,我去见见。
于是你在脑袋里面就有了下面这张图:

- 你在决策过程就是典型的分类树决策。相当于通过年龄、长相、收入和是否公务员对将男人分为两个类别:见和不见。
如何构建一颗决策树:
- 根据特征将样本分列在不同的叶子结点上的过程,称之为决策树的算法构建
3.电商业务场景深入决策树
-
在商业的数据挖掘中,不同的消费行为顾客特征的提炼和表述极为重要。
-
达成共识:构建的模型一定是有利于业务的服务
- 业务问题1:如何对客户进行分类?
- 业务问题2:如何根据决策树对销售人员进行精准营销
-
分析数据:
- 1024个样本
- 4个特征
- 1个标签列—两种取值
-
使用数据构建决策树
- 1-基于规则构建
- 2-基于模型构建
4. 基于规则的建树
- 什么规则?—专家或业务专家制定规则
- 规则:按照特征出现的顺序进行建立决策树
- 回答业务员问题:
- 根据什么进行分类?
- 如何进行精准营销?
- 基于规则的建立决策树的问题?
- 基于规则会引入专家的知识,会引入认为的主观的因素
- 需要使用机器学习的方法使用基于模型的建立决策树的方法
如下图: 1024个样本决策


5.构建决策树的三要素[重点]
1-特征选择
- 1-基于规则的选择
- 2-熵----->信息熵------>信息增益
2-决策树的生成
- 1-基于规则的生成
- 2-基于ID3算法的模型建树:
- 3-C4.5算法
- 4-CART树算法
3-决策树剪枝
- 1-基于规则的剪枝
- 先剪枝
- 后剪枝
6.基于模型的建树[重点]
核心公式: 信息熵也叫香农熵, 信息增益.
-
引入熵(entropy)的概念: 基于物理学上的物体能量分布的均匀性,熵越大的,物体能量分布越均匀
-
香农熵或信息熵: 熵在信息论上的表达形式,
- 信息熵越大,信息的分布越均匀,信息的不确定性越大,信息的确定性小
- 信息熵越小,信息的分布越不均匀,信息的不确定性越小,信息的确定性越大

通常多个独立事件所产生的不确定性等于各自不确定性之和,也就是每个事件的发生与不发生是相互独立的,这在数学上称为可加性,而满足这样可加性的函数就是我们在高中阶段所学习过的对数函数(log函数)。由此得到第一个不确定性函数公式:

如果对一个随机事件有n种取值:X1,X2,X3…,对应的概率p1,p2……pn,则该事件的不确定性应该是单个取值的不确定性的期望E,也叫作信息熵,即:
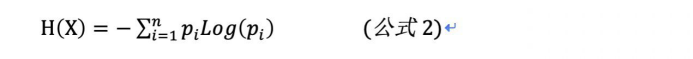
上述若对数的底数取值为2,就是我们平常所说的信息单位bit(比特)。
总结:变量的不确定性越大,熵也就越大。熵越小,信息的纯度越高。
用于决策树的选择特征中:
- 优先选择信息熵较小的特征,信息熵较小信息的不均匀,信息的确定性较大
信息增益:
-
Gain(A) = Info(D)-Info_A(D): 整个数据集信息熵 与 当前节点(划分节点)信息熵的 差
- 总体的信息熵是不变的,前提是数据确定好了
- 以A节点作为分支节点,一般情况下优先选择A节点信息熵较小的值对应的特征
- 以A节点作为分支节点的信息增益越大优先选择

特征选择:优先选择信息增益最大的值作为优先选择的节点