openblas系列:第一弹cblas_sgemm
大家好,时隔近一个月后。老汤再次回归!之前在更新图像分类模型的相关内容,最近一个月大佬带着做pc端的cpu部署和加速。给了一份基于openblas的C++加速代码,作为从未写过C++的小白。鬼知道这一个月我经历了什么,,,,
熟悉代码的过程面临跨平台编译和python的版本转换等问题,再加上自己想继续深造读研(C语言,高数,,)。所以一直没有时间来更新文章。关于跨平台和中间遇到的问题有需要的朋友可以留言在更新。这次本着重点内容做下讲解。
深度学习在做图像处理,最关键的layer就是卷积层。具体openblas的加速原理和能够加速多少,还没试验和学习暂不做评论。这里主要讲解openblas的矩阵计算原理和对应的卷积。
API参数
cblas_sgemm(order,transA,transB,M,N,K,ALPHA,A,LDA,B,LDB,BETA,C,LDC);
alpha =1,beta =0 的情况下,等于两个矩阵相成。
第一参数 oreder 候选值 有ClasRowMajow 和ClasColMajow 这两个参数决定一维数组怎样存储在内存中,
一般用ClasRowMajow
参数 transA和transB :表示矩阵A,B是否进行转置。候选参数 CblasTrans 和CblasNoTrans.
参数M:表示 A或C的行数。如果A转置,则表示转置后的行数
参数N:表示 B或C的列数。如果B转置,则表示转置后的列数。
参数K:表示 A的列数或B的行数(A的列数=B的行数)。如果A转置,则表示转置后的列数。
参数LDA:表示A的列数,与转置与否无关。
参数LDB:表示B的列数,与转置与否无关。
参数LDC:始终=N
NOTE: 首先判定是行优先还是列优先;
再次,依照lda,ldb分别将两个矩阵按行、列分开
再次,判定是否进行转置操作
输出结果;
示例程序
#include <iostream>
#include <cblas.h>
using namespace std;
int main() {
const int M=4;
const int N=2;
const int K=3;
const float alpha=1;
const float beta=0;
const int lda=M;
const int ldb=K;
const int ldc=N;
const float A[K*M]={
1,2,3,4,5,6,7,8,9,8,7,6};
const float B[N*K]={
5,4,3,2,1,0};
float C[M*N];
cblas_sgemm(CblasRowMajor, CblasTrans, CblasTrans, M, N, K, alpha, A, lda, B, ldb, beta, C, ldc);
for(int i=0;i<M;i++)
{
for(int j=0;j<N;j++)
{
cout<<C[i*N+j]<<" ";
}
cout<<endl;
}
输出结果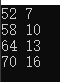
矩阵A、B是优先行排列,其中A是3行4列的矩阵、转置后是4行3列。B是2行3列的矩阵、转置后是3行4列的矩阵。由矩阵的乘法的 A T ∗ B T A^T*B^T AT∗BT为4行两列的矩阵。具体的计算就用手写啦。

灰度图像卷积
先上代码!
#include <cblas.h>
#include <iostream>
using namespace std;
int main()
{
//定义被卷积矩阵
const int Map = 8;
const float A[Map * Map] = {
1,2,3,4,5,6,7,8,
1,2,3,4,5,6,7,8,
1,2,3,4,5,6,7,8,
1,2,3,4,5,6,7,8,
1,2,3,4,5,6,7,8,
1,2,3,4,5,6,7,8,
1,2,3,4,5,6,7,8,
1,2,3,4,5,6,7,8 };
//定义卷积核
const int Kernel = 3;
const float B[Kernel * Kernel] = {
1,1,1,
1,1,1,
1,1,1 };
//计算卷积输出矩阵宽高
const int outM = Map - Kernel + 1;
//定义被卷积矩阵宽高
const int convAw = Kernel * Kernel;
const int convAh = outM * outM;
//转换被卷积矩阵 这里根据步长和kernel_size大小进行转换
float A_convert[convAh*convAw] = {
0 };
for (int i = 0; i < outM; i++)
{
for (int j = 0; j < outM; j++)
{
int wh = i * outM * convAw + j * convAw;
int col1 = i * Map + j;
A_convert[wh] = A[col1];
A_convert[wh + 1] = A[col1 + 1];
A_convert[wh + 2] = A[col1 + 2];
int col2 = (i + 1) * Map + j;
A_convert[wh + 3] = A[col2];
A_convert[wh + 4] = A[col2 + 1];
A_convert[wh + 5] = A[col2 + 2];
int col3 = (i + 2) * Map + j;
A_convert[wh + 6] = A[col3];
A_convert[wh + 7] = A[col3 + 1];
A_convert[wh + 8] = A[col3 + 2];
}
}
//定义cblas初始值
const enum CBLAS_ORDER Order = CblasRowMajor;
const enum CBLAS_TRANSPOSE TransA = CblasNoTrans;
const enum CBLAS_TRANSPOSE TransB = CblasNoTrans;
const int M = convAh;//A的行数,C的行数
const int N = 1;//B的列数,C的列数
const int K = convAw;//A的列数,B的行数
const float alpha = 1;
const float beta = 0;
const int lda = K;//A的列
const int ldb = N;//B的列
const int ldc = N;//C的列
//定义卷积输出矩阵
float C[M*N];
//cblas计算输出矩阵 M=36 N=1 k=9。A_convert = [36,9]=36*9,B=[9,1]=9*1 C= [M,N]=M*N
cblas_sgemm(Order, TransA, TransB, M, N, K, alpha, A_convert, lda, B, ldb, beta, C, ldc);
//输出验证
cout << "A is:" << endl;
for (int i = 0; i < Map; i++)
{
for (int j = 0; j < Map; j++)
{
cout << A[i*Map + j] << " ";
}
cout << endl;
}
cout << endl;
cout << "B is:" << endl;
for (int i = 0; i < Kernel; i++)
{
for (int j = 0; j < Kernel; j++)
{
cout << B[i*Kernel + j] << " ";
}
cout << endl;
}
cout << endl;
cout << "C is:" << endl;
for (int i = 0; i < outM; i++)
{
for (int j = 0; j < outM; j++)
{
cout << C[i*outM + j] << " ";
}
cout << endl;
}
cout << endl;
return 0;
}
输出结果
卷积的过程就不在过多讲解。这里主要讲解如果将卷积的过程和矩阵计算联系到一起,因为卷积的通过卷积核的相乘相加和步长的移动来实现的。卷积核的宽,高再加步长就是三个维度,是不符合二维矩阵的计算。那么这里的关键是如何将卷积过程处理成矩阵的计算。
这里的kernel_size=[3,3],每一次的kernel_size计算会得出输出矩阵中的一个值。根据步长的大小我们计算出一共需要移动多少次kernel_size。我们将kernel_size的宽高合并为一个维度(33=9),一共需要移动(8-3+1)(8-3+1)=36次。故cblas_sgemm中A矩阵的大小为36行9列,B矩阵也就是kernel_size为9行1列。得出的结果为36行1列,格式化输出卷积结果6行6列。
参考博文:
Openblas加速二维矩阵卷积操作
openblas第一弹:openblas 使用说明和常用接口介绍
Developer Reference for Intel® Math Kernel Library - C