1、准备工作
数据集
| 数据集 | #图 | #节点 | #边 | #特征 | #标签(y) |
|---|---|---|---|---|---|
| Cora | 1 | 2708 | 5429 | 1433 | 7 |
| Citeseer | 1 | 3327 | 4732 | 3703 | 6 |
| Pubmed | 1 | 19717 | 44338 | 500 | 3 |
数据集划分方式:https://github.com/kimiyoung/planetoid (Zhilin Yang, William W. Cohen, Ruslan Salakhutdinov, Revisiting Semi-Supervised Learning with Graph Embeddings, ICML 2016)
| 数据集划分(数量) | 训练集 | 验证集 | 测试集 |
|---|---|---|---|
| Cora | 140 | 500 | 1000 |
| Citeseer | 120 | 500 | 1015 |
| Pubmed | 60 | 500 | 1000 |
代码
参考:https://github.com/FighterLYL/GraphNeuralNetwork/tree/master/chapter7。
使用监督学习的方法,增加了Citeseer和Pubmed数据集,并对其代码进行了重构和调试,排除了一些小bug,增加了详细的注释。
完善后的代码:https://github.com/ytchx1999/GraphSAGE-Cora-Citeseer-Pubmed。
实验环境
其实本地用mac的CPU跑也蛮快的。。
但是还是用GPU(最开始是一块2080Ti,后面用的Tesla T4)会更快一点,毕竟time is money!
2、超参数
BATCH_SIZE = 16 # 批处理大小
EPOCHS = 10
NUM_BATCH_PER_EPOCH = 20 # 每个epoch循环的批次数
LEARNING_RATE = 「0.1,0.01」 # 学习率,每5个epoch x0.1
3、实验结果
2层SageGCN层
GraphSage(
in_features=【输入的特征维度】, num_neighbors_list=[10, 10]
(gcn): ModuleList(
(0): SageGCN(
in_features=【输入的特征维度】, out_features=256, aggr_hidden_method=sum
(aggregator): NeighborAggregator(in_features=【输入的特征维度】, out_features=256, aggr_method=mean)
)
(1): SageGCN(
in_features=256, out_features=【输出的特征维度】, aggr_hidden_method=sum
(aggregator): NeighborAggregator(in_features=256, out_features=【输出的特征维度】, aggr_method=mean)
)
)
)
| 聚合 + 更新方法 | Cora | Citeseer | Pubmed |
|---|---|---|---|
| mean_pool + sum | 0.78 | 0.57 | 0.73 |
| max_pool + sum | 0.75 | 0.57 | 0.75 |
| mean_pool + concat | 0.74 | 0.55 | 0.75 |
| max_pool + concat | 0.75 | 0.59 | 0.75 |
2021.1.14更新
感觉还是数据集划分的问题,根据paper原作者的实验代码,重新划分数据集,做了实验(lr=0.1)
| 数据集划分(数量) | 训练集 | 验证集 | 测试集 |
|---|---|---|---|
| Cora | 1208 | 500 | 1000 |
| 聚合 + 更新方法 | Cora |
|---|---|
| mean_pool + sum | 0.85 |
| max_pool + sum | 0.84 |
| mean_pool + concat | 0.84 |
| max_pool + concat | 0.82 |
结果比之前好不少了。
2021.1.18更新
使用PyG进行实验。
数据集的划分同最开始,使用full-batch。发现效果要比minibatch好一些。
实现代码:https://github.com/ytchx1999/PyG-GraphSAGE。
Net(
(conv1): SAGEConv(num_node_feature, 16)
(conv2): SAGEConv(16, num_classes)
)
| 聚合 + 更新方法 | Cora | Citeseer | Pubmed |
|---|---|---|---|
| mean_pool + sum | 0.81 | 0.67 | 0.77 |
3层SageGCN层
GraphSage(
in_features=【输入的特征维度】, num_neighbors_list=[10, 5, 5]
(gcn): ModuleList(
(0): SageGCN(
in_features=【输入的特征维度】, out_features=256, aggr_hidden_method=sum
(aggregator): NeighborAggregator(in_features=【输入的特征维度】, out_features=256, aggr_method=mean)
)
(1): SageGCN(
in_features=256, out_features=128, aggr_hidden_method=sum
(aggregator): NeighborAggregator(in_features=256, out_features=128, aggr_method=mean)
)
(2): SageGCN(
in_features=128, out_features=【输出的特征维度】, aggr_hidden_method=sum
(aggregator): NeighborAggregator(in_features=128, out_features=【输入的特征维度】, aggr_method=mean)
)
)
)
| 聚合 + 更新方法 | Cora | Citeseer | Pubmed |
|---|---|---|---|
| mean_pool + sum | 0.78 | 0.50 | 0.75 |
| max_pool + sum | 0.73 | – | 0.76 |
| mean_pool + concat | 0.77 | 0.58 | 0.75 |
| max_pool + concat | 0.74 | – | 0.77 |
–: 代表出现了以下的问题。
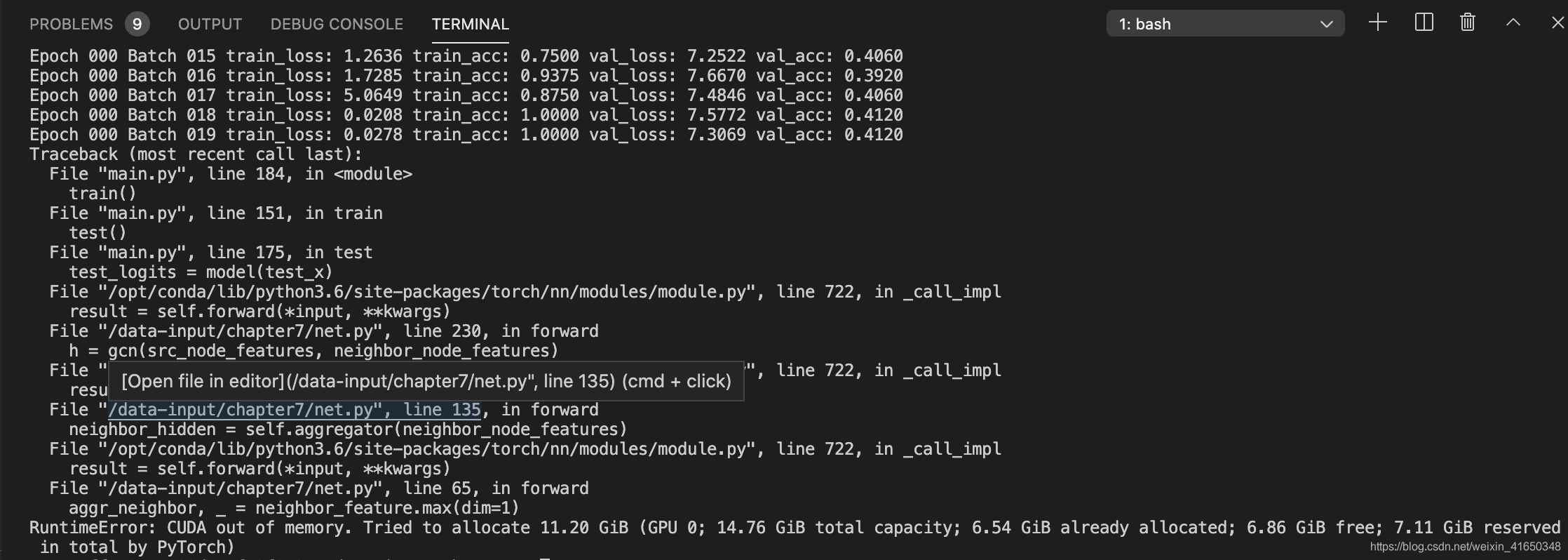
4、问题分析
-
GraphSAGE原文使用的citation数据集是WoS(一个比较大的图),效果要比本实验小图的效果好一些,不过差距也不太大,也进一步说明了GraphSAGE归纳学习的能力。
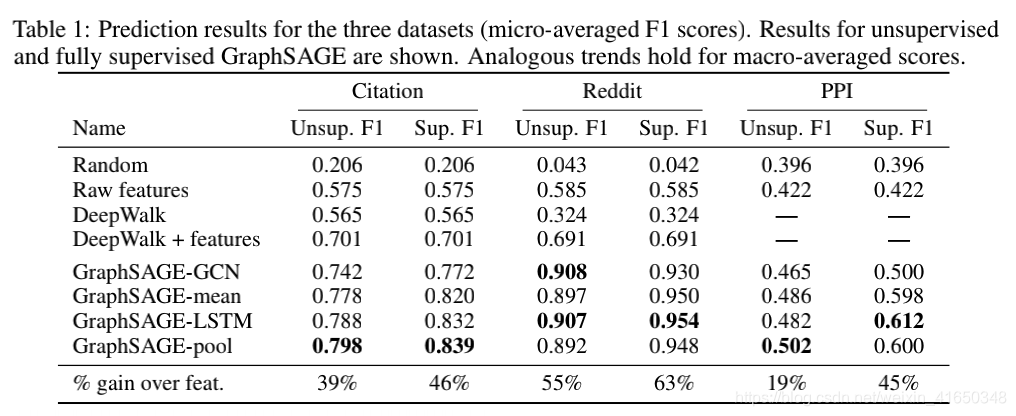
-
这是GNN综述《A Comprehensive Survey on Graph Neural Networks》中汇总各个paper的结果,但是GraphSAGE并没有使用到这几个数据集(Cora、Citeseer、Pubmed),可能是因为这几个数据集都比较小,而GraphSAGE对于大图来说效果比较好。GraphSAGE采样可能意味着邻居信息的丢失,这在小图中可能影响很大,因此,效果可能并不如GCN等模型。
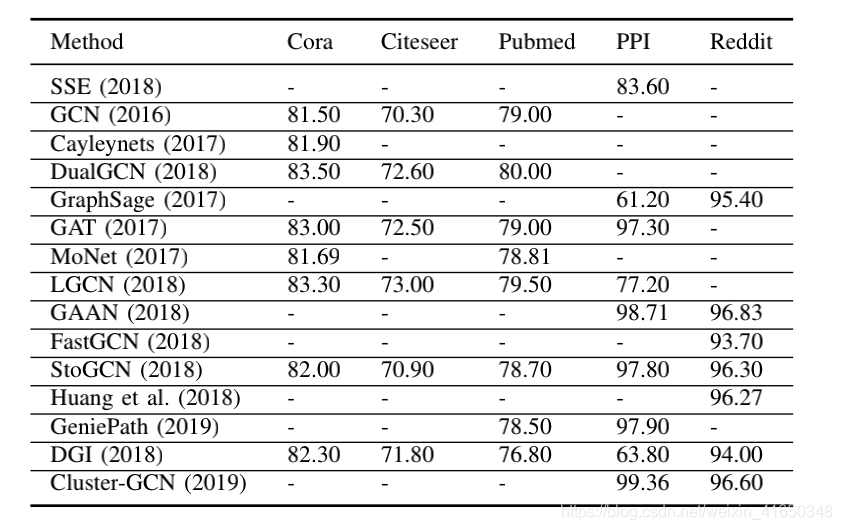
-
关于数据集的划分,总感觉怪怪的,下面(参考引用)也列了一篇吐槽的文章,后面有时间去看一下那篇paper,看看到底为什么要这样划分(可能是个坑)。
-
关于Citeseer数据集的问题。应该是有15个孤立节点,导致了程序出现问题以及训练精度都不好。我之前也写过一篇博客说过这个问题:《citeseer数据集的读取和处理》。
有2种思路来解决这个问题:①直接删除3312之后的节点;②补全法:Citeseer的测试数据集中有一些孤立的点没有在test.index中(15个),可把这些点当作特征全为0的节点加入到测试集tx中,并且对应的标签加入到ty中。

2020.1.18
破案了。。15个孤立节点,PyG采用了补全法强行将其补全为3327。。。
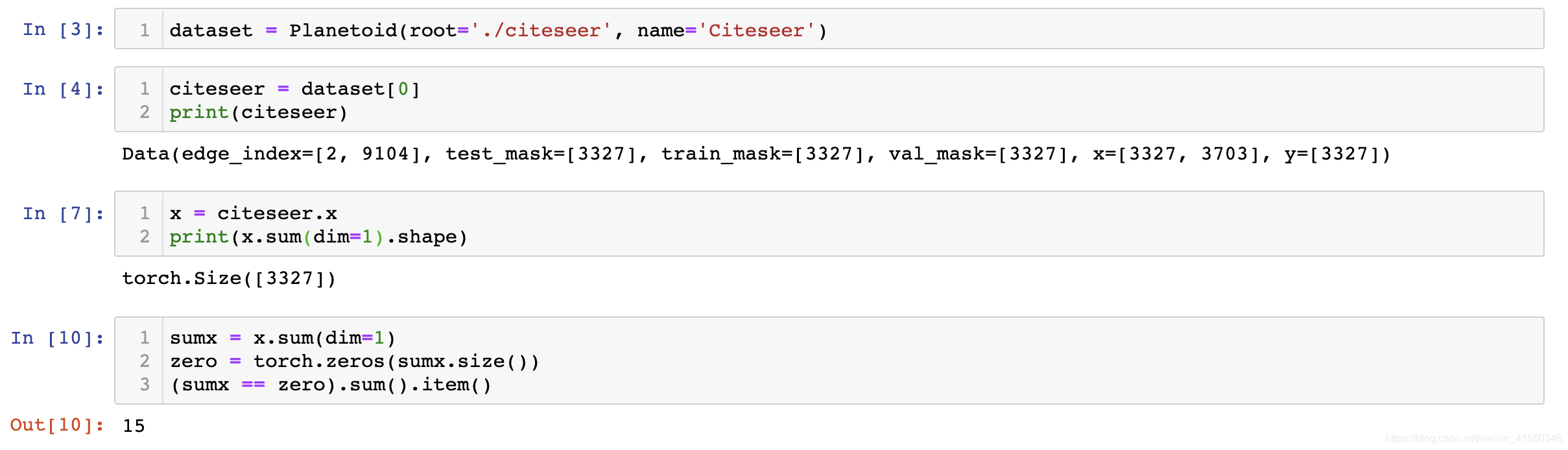
总之就是有问题,实际上总共有3327各节点,但是原始数据集是有向图,只有3312个节点有出边。只能说,数据集本身就有问题,这也导致了效果远不如Cora和Pubmed。
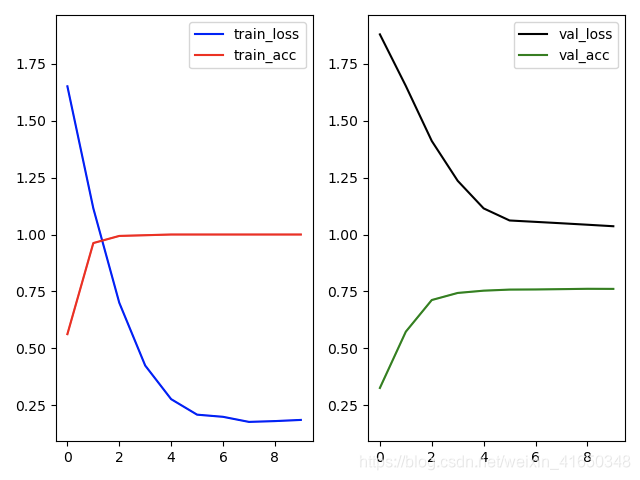
5、可视化
以cora + mean_pool + sum为例
6、参考引用
代码:Chapter7:GraphSage示例(使用Cora数据集)–github
数据集划分:《Revisiting Semi-Supervised Learning with Graph Embeddings》–github
关于数据集:
《GCN使用的数据集Cora、Citeseer、Pubmed、Tox21格式》
《GCN数据集Cora、Citeseer、Pubmed文件分析》
《GCN的Benchmark数据集追溯》