介绍
- FM 模型的参数支持非常稀疏的特征,而 SVM 等模型不行
- FM 的时间复杂度为 O ( n ) O(n) O(n),并且可以直接优化原问题的参数,而不需要依靠支持向量或者是转化成对偶问题解决
- FM 是通用的模型,可以适用于任何实数特征的场景,其他的模型不行

FM模型
引入
在线性回归上,把特征进行二项组合后,
y ^ = w 0 + ∑ i = 1 n w i x i + ∑ i = 1 n − 1 ∑ j = i + 1 n w i j x i x j (1) \hat{y}=w_0+\sum^n_{i=1}w_ix_i+\sum^{n-1}_{i=1}\sum^n_{j=i+1}w_{ij}x_ix_j \tag{1} y^=w0+i=1∑nwixi+i=1∑n−1j=i+1∑nwijxixj(1) 对于 n 维特征,共需要 C n 2 C^2_n Cn2 个,即 n ( n − 1 ) 2 \frac{n(n-1)}{2} 2n(n−1)
隐向量
FM 模型引入了矩阵 V,矩阵 V 是一个 n × k n \times k n×k 的二维矩阵。这里的 k 是我们设置的参数,一般不会很大,比如 16、32 之类。对于特征每一个维度 i i i,我们都可以找到一个 v i v_i vi,它表示一个长度为 k 的向量。
那原来的 w i j w_{ij} wij 由 v i v_i vi 和 v j v_j vj 计算得到
w i j = v i T v j (2) w_{ij}=v^T_iv_j \tag{2} wij=viTvj(2) 参数量为 n × k n \times k n×k,k 是一个常数,所以就是 O ( n ) O(n) O(n)
式 (1) 改写为
y ^ = w 0 + ∑ i = 1 n w i x i + ∑ i = 1 n − 1 ∑ j = i + 1 n v i T v j x i x j (3) \hat{y}=w_0+\sum^n_{i=1}w_ix_i+\sum^{n-1}_{i=1}\sum^n_{j=i+1}v^T_iv_jx_ix_j \tag{3} y^=w0+i=1∑nwixi+i=1∑n−1j=i+1∑nviTvjxixj(3) 当 k 足够大时,可以得到 W = V ⋅ V T W = V \cdot V^T W=V⋅VT,矩阵 V 可以看作对 W 做了一个因子分解
运用中,不用设置很大的 k,一是可能没有足够多的样本训练这么多参数,二是限制 k 一定程度提升 FM 模型的泛化能力
最后,FM 引入的隐向量可看作 embedding 的方式
优化
式 (3) 的计算复杂度是 O ( n 2 ) O(n^2) O(n2),
∑ i = 1 n ∑ j = i + 1 n ⟨ v i , v j ⟩ x i x j = 1 2 ( ∑ i = 1 n ∑ j = 1 n ⟨ v i , v j ⟩ x i x j − ∑ i = 1 n ⟨ v i , v i ⟩ x i x i ) = 1 2 ( ∑ i = 1 n ∑ j = 1 n ∑ f = 1 k v i , f v j , f x i x j − ∑ i = 1 n ∑ f = 1 k v i , f v i , f x i x i ) = 1 2 ∑ f = 1 k ( ( ∑ i = 1 n v i , f x i ) ( ∑ j = 1 n v j , f x j ) − ∑ i = 1 n v i , f 2 x i 2 ) = 1 2 ∑ f = 1 k ( ( ∑ i = 1 n v i , f x i ) 2 − ∑ i = 1 n v i , f 2 x i 2 ) (4) \begin{aligned} & \sum_{i=1}^{n} \sum_{j=i+1}^{n}\left\langle\mathbf{v}_{i}, \mathbf{v}_{j}\right\rangle x_{i} x_{j} \\ =& \frac{1}{2} \left(\sum_{i=1}^{n} \sum_{j=1}^{n}\left\langle\mathbf{v}_{i}, \mathbf{v}_{j}\right\rangle x_{i} x_{j}- \sum_{i=1}^{n}\left\langle\mathbf{v}_{i}, \mathbf{v}_{i}\right\rangle x_{i} x_{i} \right) \\ =& \frac{1}{2}\left(\sum_{i=1}^{n} \sum_{j=1}^{n} \sum_{f=1}^{k} v_{i, f} v_{j, f} x_{i} x_{j}-\sum_{i=1}^{n} \sum_{f=1}^{k} v_{i, f} v_{i, f} x_{i} x_{i}\right) \\ =& \frac{1}{2} \sum_{f=1}^{k}\left(\left(\sum_{i=1}^{n} v_{i, f} x_{i}\right)\left(\sum_{j=1}^{n} v_{j, f} x_{j}\right)-\sum_{i=1}^{n} v_{i, f}^{2} x_{i}^{2}\right) \\ =& \frac{1}{2} \sum_{f=1}^{k}\left(\left(\sum_{i=1}^{n} v_{i, f} x_{i}\right)^{2}-\sum_{i=1}^{n} v_{i, f}^{2} x_{i}^{2}\right) \end{aligned} \tag{4} ====i=1∑nj=i+1∑n⟨vi,vj⟩xixj21(i=1∑nj=1∑n⟨vi,vj⟩xixj−i=1∑n⟨vi,vi⟩xixi)21⎝⎛i=1∑nj=1∑nf=1∑kvi,fvj,fxixj−i=1∑nf=1∑kvi,fvi,fxixi⎠⎞21f=1∑k((i=1∑nvi,fxi)(j=1∑nvj,fxj)−i=1∑nvi,f2xi2)21f=1∑k⎝⎛(i=1∑nvi,fxi)2−i=1∑nvi,f2xi2⎠⎞(4) 这就相当于一个对称矩阵,先减掉对角线元素,再取 1/2
对比
Linear SVM
y ^ ( X ) = w o + w u + w i (2) \hat{y}(\bold{X})=w_o+w_u+w_i \tag{2} y^(X)=wo+wu+wi(2) x j = 1 x_j = 1 xj=1 if and only if j = u j = u j=u or j = i j = i j=i.
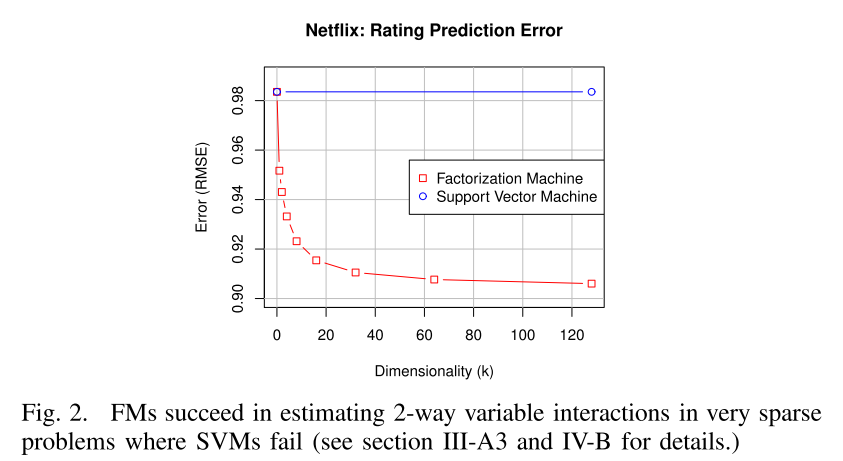
the parameters can be estimated well even under sparsity.
However, the empirical prediction quality typically is low
Polynomial SVM
y ^ ( x ) = w 0 + 2 ( w u + w i ) + w u , u ( 2 ) + w i , i ( 2 ) + 2 w u , i ( 2 ) (5) \hat{y}(\mathbf{x})=w_{0}+\sqrt{2}\left(w_{u}+w_{i}\right)+w_{u, u}^{(2)}+w_{i, i}^{(2)}+\sqrt{2} w_{u, i}^{(2)} \tag{5} y^(x)=w0+2(wu+wi)+wu,u(2)+wi,i(2)+2wu,i(2)(5)
总结
(1) FMs are able to estimate parameters under huge sparsity, (2) the model equation is linear and depends only on the model parameters and thus (3) they can be optimized directly in the primal.
(1) FM能够在非常稀疏的情况下估计参数;(2) 模型方程是线性的,并且仅取决于模型参数,因此 (3) 可以直接对其进行优化。
simply by using the right indicators in the input feature vector, FMs are identical or very similar to many of the specialized state-of-the-art models
只需在输入特征向量中使用正确的指示器,FM 就可以与许多专门的最新模型相同或非常相似
代码
import torch
from torch import nn
ndim = len(feature_names)
k = 16
class FM(nn.Module):
def __init__(self, dim, k):
super(FM, self).__init__()
self.dim = dim
self.k = k
self.linear = nn.Linear(self.dim, 1, bias=True)
# 初始化V矩阵
self.v = nn.Parameter(torch.rand(self.dim, self.k) / 100)
def forward(self, x):
y_linear = self.linear(x)
# 二次项
y_quadradic = 0.5 * torch.sum(torch.pow(torch.mm(x, self.v), 2) - torch.mm(torch.pow(x, 2), torch.pow(self.v, 2)))
# 输出
return torch.sigmoid(y_linear+ y_quadradic)
fm = FM(ndim, k)