卷积网络正在推动图像识别技术的进步。卷积网络不仅提升整幅图像的分类能力,而且对于具有结构化输出的局部任务同样取得进展,这包括目标检测、关键点检测等。从粗到精的推理过程中,自然而然的下一步就是在每个像素点上进行预测。
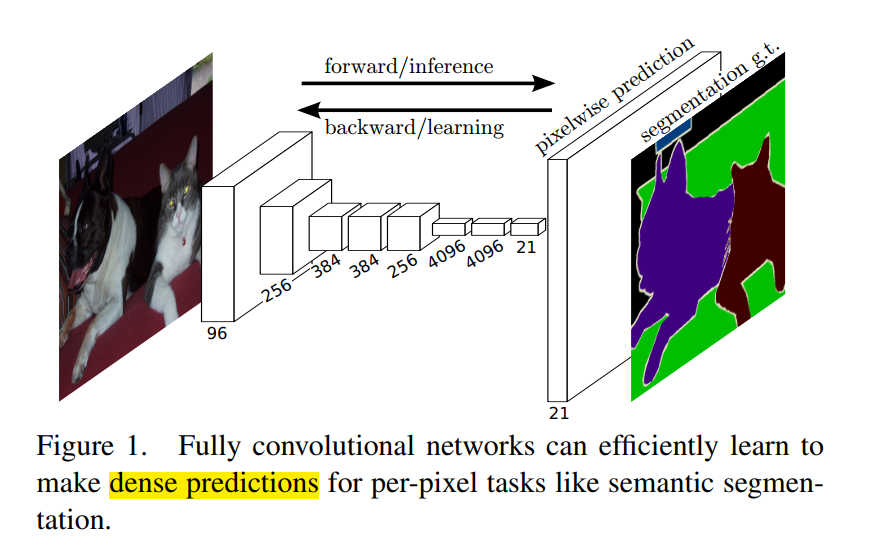
本文提出了一个全卷积网络概念,采用端到端、像素到像素的训练,在语义分割场景下达到了最优的水平。这是第一次端到端训练的FCN,以用于像素级的预测;同时是第一次用监督预训练的方法训练FCN。
下面对FCN的关键点进行介绍。
一、调整分类器以进行密集预测
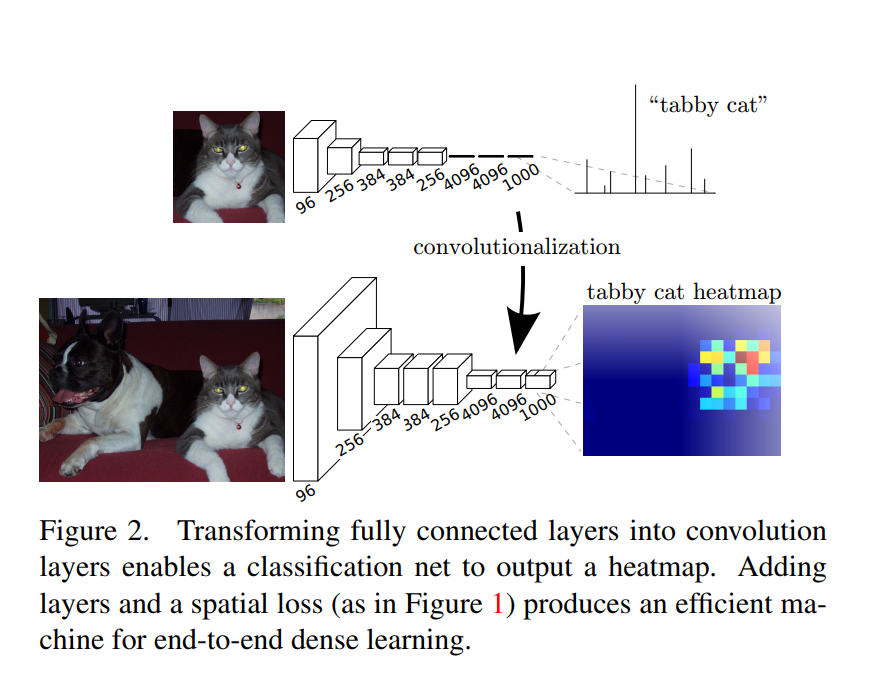
图中上半部分是一个经典的8层AlexNet网络,其中前五层是卷积层,最后三层是全连接层。
作者认为全连接层有着固定的维度,且丢失了空间信息。这里丢失空间信息是指从二维展平为一维。因此,作者采用卷积层来代替全连接层,如图中下半部分所示。
原来的AlexNet 最后三层分别是 9216 ∗ 4096 9216*4096 9216∗4096的全连接层、 4096 ∗ 4096 4096*4096 4096∗4096的全连接层、 4096 ∗ 1000 4096*1000 4096∗1000的全连接层。其中 9126 = 256 ∗ 6 ∗ 6 9126=256*6*6 9126=256∗6∗6, 256是第五层卷积层的通道数,6是第五层卷积层的核大小。
经过采用卷积层的替换,最后三层变为 4096 ∗ 6 ∗ 6 4096*6*6 4096∗6∗6的卷积层(输出特征图是 4096 ∗ 1 ∗ 1 4096*1*1 4096∗1∗1)、 4096 ∗ 1 ∗ 1 4096*1*1 4096∗1∗1的卷积层(输出特征图是 4096 ∗ 1 ∗ 1 4096*1*1 4096∗1∗1)、 1000 ∗ 1 ∗ 1 1000*1*1 1000∗1∗1的卷积层(输出特征图是 1000 ∗ 1 ∗ 1 1000*1*1 1000∗1∗1)。
经过这样的处理,我们得到了一个 1000 ∗ 1 ∗ 1 1000*1*1 1000∗1∗1的输出特征图,使它们成为语义分割等密集预测问题的自然选择。
二、上采样
我们从上一节知道,经过对网络的全连接层调整之后,输出的结果是一个特征图,它的宽和高是 1 ∗ 1 1*1 1∗1。
那么我们需要把这种 1 ∗ 1 1*1 1∗1的宽高恢复到原输入图像大小,以实现像素级的预测。

图中使用的是VGG-16网络实现的特征提取。我们知道,VGG的网络结构非常简洁,只有 k = 3 ∗ 3 , s t r i d e = 1 , p a d d i n g = 1 k=3*3,stride=1,padding=1 k=3∗3,stride=1,padding=1的卷积层和 k = 2 ∗ 2 , s t r i d e = 2 , p a d d i n g = 0 k=2*2,stride=2,padding=0 k=2∗2,stride=2,padding=0的最大池化层,通过公式$output = (input - k + 2 * padding)/stride + 1 可 以 算 出 , 特 征 图 经 过 卷 积 层 的 结 果 是 可以算出,特征图经过卷积层的结果是 可以算出,特征图经过卷积层的结果是output = input , 特 征 图 经 过 池 化 层 的 结 果 是 , 特征图经过池化层的结果是 ,特征图经过池化层的结果是output = input / 2$。
再结合上图,对于输入图像image, 只有在 p o o l 1 , p o o l 2 , p o o l 3 , p o o l 4 , p o o l 5 pool1,pool2,pool3,pool4,pool5 pool1,pool2,pool3,pool4,pool5这五个层输入尺寸会变化。与输入图像相比,尺寸分别是下降2倍、4倍、8倍、16倍、32倍。
所以VGG-16特征提取之后,图像尺寸已经下降为原来的32倍。那么为了对图像尺寸进行恢复,需要进行一个32倍的上采样,还原到与输入图像相同大小的尺寸。
对于这种上采样恢复操作,作者在文中一共提到了四种方法来实现这个过程。分别是:
- 输入转移与输出隔行扫描
- 过滤器稀疏
- 反卷积(也叫转置卷积)
- 双线性插值
其中作者没有采用前两种,使用了后两种方法。具体双线性插值和反卷积的详细介绍,之前专门写过一篇文章,可以详细了解。
三、融合语义信息和位置信息
虽然完全卷积的分类器可以经过微调(fine-tuning)适用到语义分割的场景中,并且在标准指标上取得了很好的分数,但它的输出结果仍然是粗糙的。原因在于最终预测层的32像素步幅限制了上采样输出的细节比例。
作者采用将高层(包含语义信息)和低层(包含位置信息)进行结合,可以使得模型做出符合全局结构的局部预测。
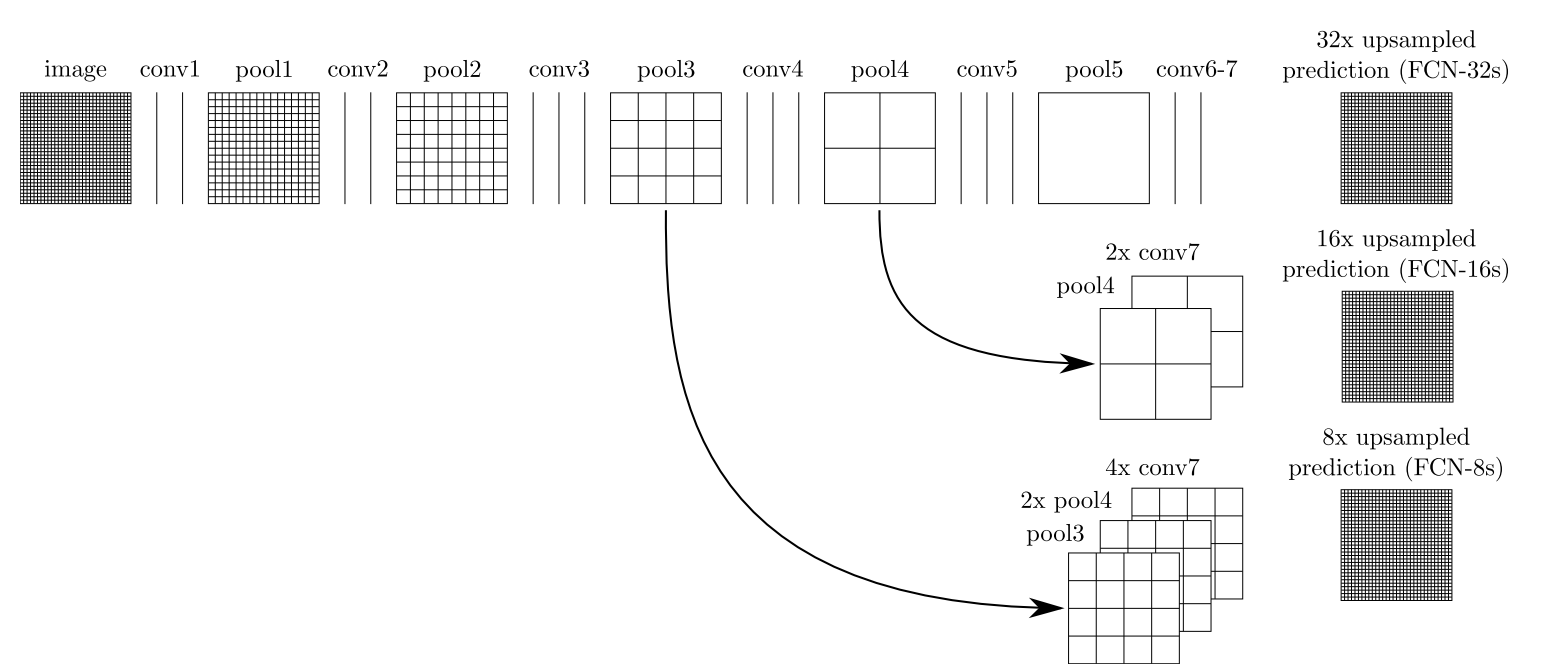
具体做法是:
- 在conv7 层输出特征图上做一个2倍上采样,然后和pool4层输出特征图,进行融合(add 操作)。
- 然后在融合的特征图上做一个16倍上采样,得到最终的预测结果FCN-16s。
然后作者沿着这个思路进行尝试:
- 在conv7 层输出特征图上做一个2倍上采样,然后和pool4层输出特征图,进行融合(add 操作)。
- 然后在融合的特征图上做一个2倍上采样,和pool3层的输出特征图,再进行融合(add 操作)。
- 最后在融合的特征图上做一个8倍上采样,得到最终的预测结果FCN-8s。
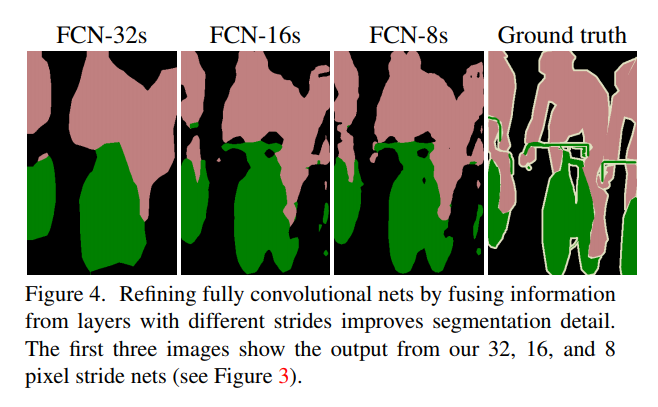
下图是FCN-32s、FCN-16s、FCN-8s三种方式预测的效果。可见语义分割效果从FCN-32s到FCN-8s 是越来越好。
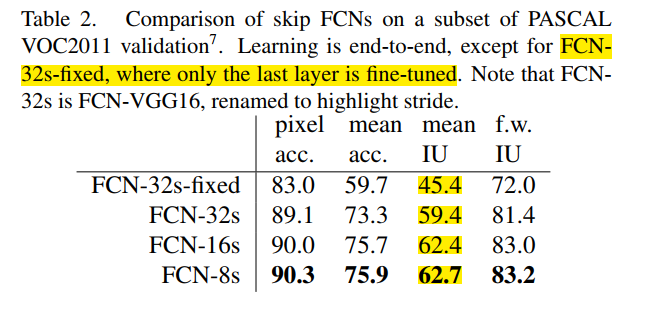
下表是展示在不同评价指标上的对比数据。**注意:**作者提到从FCN-16s到FCN-8s,各项指标的提升已经很小。所以作者没有再继续尝试FCN-4s这种实现。
四、实现过程中的Tricks
4.1 在第一个卷积层设置padding=100
在本文第二节中,我们已经介绍了VGG-16的网络层和前向传播过程图像尺寸的变化。按照标准的VGG-16, 在pool5 之后图像尺寸下降了32倍。
假设输入图像的尺寸为 h = w = i n p u t h=w=input h=w=input, 那么在pool5层得到的特征图大小为 i n p u t / 32 input/32 input/32 。
在conv6(pool5下一层)使用的是 k = 7 ∗ 7 , s t r i d e = 1 , p a d d i n g = 0 k=7*7,stride=1,padding=0 k=7∗7,stride=1,padding=0的卷积,则得到conv6输出特征图大小为 i n p u t / 32 − 7 + 1 = ( i n p u t − 192 ) / 32 input/32 -7 +1 = (input-192)/32 input/32−7+1=(input−192)/32 。
即输入图像尺寸 i n p u t < 192 input<192 input<192时,经过conv6后的输出特征图尺寸小于0。这样会使得模型对图像输入限制太严格。
作者为了解决这个问题,在VGG-16第一个卷积时,将 p a d d i n g = 1 padding=1 padding=1改为了 p a d d i n g = 100 padding=100 padding=100。 那么经过conv6后的特征图大小为 ( i n p u t − 192 + 198 ) / 32 = ( i n p u t + 6 ) / 32 (input-192 + 198)/32= (input+6)/32 (input−192+198)/32=(input+6)/32
4.2 对图像做裁剪
这个操作在FCN-32s、FCN-16s、FCN-8s三种方式中都有使用。
咱们先以在FCN-32s的使用来介绍。
在4.1节我们知道,经过conv6后的特征图大小为 ( i n p u t + 6 ) / 32 (input+6)/32 (input+6)/32.
现在我们需要对它进行32倍上采样,已知下采样的卷积公式是 o = ( i − k + 2 ∗ p ) / s + 1 o = (i - k +2 *p)/s + 1 o=(i−k+2∗p)/s+1, 那么反卷积的公式是 o ’ = ( i ’ − 1 ) ∗ s ’ + k ’ − 2 ∗ p ’ o^{’} = (i^{’} -1) *s^{’} +k^{’} - 2*p^{’} o’=(i’−1)∗s’+k’−2∗p’。
代入 i ’ = ( i n p u t + 6 ) / 32 , s ′ = 32 , k ’ = 64 , p ’ = 0 i^{’}=(input+6)/32,s^{'}=32,k^{’} =64,p^{’}=0 i’=(input+6)/32,s′=32,k’=64,p’=0,可以得到 o ’ = i n p u t + 38 o^{’}=input+38 o’=input+38
可见经过上采样之后的图像大小超过了原始输入图像的大小,所以需要对上采样后的图像进行裁剪。裁剪即采用中心裁剪的方式。具体实现如下:
# 经过上采样后的output = input + 38, 通过裁剪,使得output = input
output = output[:,:,19:19+input.size()[2], 19:19+input.size()[3]].contiguous()
五、FCN 优劣分析
优点:
- 将分类网络经过调整适用到语义分割场景中。
- 能够接收任意大小的图像输入,不需要对输入图像进行限制。
- 结合精细层和粗糙层的信息进行融合,改善语义分割结果。
- 相比传统的语义分割思路(传统思路中为了对像素分类,使用像素周围的图像作为网络输入),计算效率高效。
不足:
- 分割结果仍不够精细。
- 忽略了在通常的基于像素分类的分割方法中使用的空间规整步骤,缺乏空间一致性。
六、PyTorch实现FCN-32s
import torch
import torch.nn as nn
import numpy as np
# https://github.com/shelhamer/fcn.berkeleyvision.org/blob/master/surgery.py
def get_upsampling_weight(in_channels, out_channels, kernel_size):
"""Make a 2D bilinear kernel suitable for upsampling"""
factor = (kernel_size + 1) // 2
if kernel_size % 2 == 1:
center = factor - 1
else:
center = factor - 0.5
og = np.ogrid[:kernel_size, :kernel_size]
filt = (1 - abs(og[0] - center) / factor) * \
(1 - abs(og[1] - center) / factor)
weight = np.zeros((in_channels, out_channels, kernel_size, kernel_size),
dtype=np.float64)
weight[range(in_channels), range(out_channels), :, :] = filt
return torch.from_numpy(weight).float()
class FCN32s(nn.Module):
def __init__(self, num_classes=21):
super(FCN32s, self).__init__()
# 这里Encoder使用的是Vgg16: [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M']
# conv1, 为了防止尺寸小于197的图像被下采样为0, 使用了padding=100
self.conv1_1 = nn.Conv2d(3, 64, 3, padding=100)
self.relu1_1 = nn.ReLU(inplace=True)
self.conv1_2 = nn.Conv2d(3, 64, 3, padding=1)
self.relu1_2 = nn.ReLU(inplace=True)
self.pool1 = nn.MaxPool2d(2, 2, ceil_mode=True) # 下采样 1/2
# conv2
self.conv2_1 = nn.Conv2d(64, 128, 3, padding=1)
self.relu2_1 = nn.ReLU(inplace=True)
self.conv2_2 = nn.Conv2d(128, 128, 3, padding=1)
self.relu2_2 = nn.ReLU(inplace=True)
self.pool2 = nn.MaxPool2d(2, 2, ceil_mode=True) # 下采样 1/4
# conv3
self.conv3_1 = nn.Conv2d(128, 256, 3, padding=1)
self.relu3_1 = nn.ReLU(inplace=True)
self.conv3_2 = nn.Conv2d(256, 256, 3, padding=1)
self.relu3_2 = nn.ReLU(inplace=True)
self.conv3_3 = nn.Conv2d(256, 256, 3, padding=1)
self.relu3_3 = nn.ReLU(inplace=True)
self.pool3 = nn.MaxPool2d(2, 2, ceil_mode=True) # 下采样 1/8
# conv4
self.conv4_1 = nn.Conv2d(256, 512, 3, padding=1)
self.relu4_1 = nn.ReLU(inplace=True)
self.conv4_2 = nn.Conv2d(512, 512, 3, padding=1)
self.relu4_2 = nn.ReLU(inplace=True)
self.conv4_3 = nn.Conv2d(512, 512, 3, padding=1)
self.relu4_3 = nn.ReLU(inplace=True)
self.pool4 = nn.MaxPool2d(2, 2, ceil_mode=True) # 下采样 1/16
# conv5
self.conv5_1 = nn.Conv2d(512, 512, 3, padding=1)
self.relu5_1 = nn.ReLU(inplace=True)
self.conv5_2 = nn.Conv2d(512, 512, 3, padding=1)
self.relu5_2 = nn.ReLU(inplace=True)
self.conv5_3 = nn.Conv2d(512, 512, 3, padding=1)
self.relu5_3 = nn.ReLU(inplace=True)
self.pool5 = nn.MaxPool2d(2, 2, ceil_mode=True) # 下采样 1/32
# fc6
self.fc6 = nn.Conv2d(512, 4096, 7)
self.relu6 = nn.ReLU(inplace=True)
self.drop6 = nn.Dropout2d()
# 正常vgg经历了五次下采样和fc6一次7×7的卷积是(h - 192) / 32,为了避免图像大小小于192的图像被池化为0, 才在第一个卷积上padding=100
# 经历了五次下采样和fc6一次7×7的卷积, output: (h + 6) / 32
# fc7
self.fc7 = nn.Conv2d(4096, 4096, 1)
self.relu7 = nn.ReLU(inplace=True)
self.drop7 = nn.Dropout2d()
self.score_fr = nn.Conv2d(4096, num_classes, 1)
# h7 = (h6 - 1) * stride - 2 * padding + kernel_size = ((h + 6) / 32 - 1) * 32 + 64 = h + 38
# 此时经过32倍上采样的输出图像尺寸,大于了原始尺寸。所以在后面操作做了一个中心裁剪, 裁剪到和h一样大小
self.upscore = nn.ConvTranspose2d(num_classes, num_classes, 64, stride=32, bias=False)
self._initialize_weights()
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
m.weight.data.zero_()
if m.bias is not None:
m.bias.data.zero_()
if isinstance(m, nn.ConvTranspose2d):
assert m.kernel_size[0] == m.kernel_size[1]
initial_weight = get_upsampling_weight(
m.in_channels, m.out_channels, m.kernel_size[0])
m.weight.data.copy_(initial_weight)
def forward(self, x):
output = self.relu1_1(self.conv1_1(x))
output = self.relu1_2(self.conv1_2(output))
output = self.pool1(output)
output = self.relu2_1(self.conv2_1(output))
output = self.relu2_2(self.conv2_2(output))
output = self.pool2(output)
output = self.relu3_1(self.conv1_1(x))
output = self.relu3_2(self.conv1_2(output))
output = self.relu3_3(self.conv1_3(output))
output = self.pool3(output)
output = self.relu4_1(self.conv4_1(output))
output = self.relu4_2(self.conv4_2(output))
output = self.relu4_3(self.conv4_3(output))
output = self.pool4(output)
output = self.relu5_1(self.conv5_1(output))
output = self.relu5_2(self.conv5_2(output))
output = self.relu5_3(self.conv5_3(output))
output = self.pool5(output)
output = self.relu6(self.fc6(output))
output = self.drop6(output)
output = self.relu7(self.fc7(output))
output = self.drop7(output)
output = self.score_fr(output)
output = self.upscore(output)
output = output[:, :, 19:19 + x.size()[2], 19:19 + x.size()[3]].contiguous()
return output
写在最后的话
公众号:CV面试宝典,定期原创技术分享。公众号后台回复“图像分割”,获取本文涉及到的经典论文。
愿与各位一起进步!