FCOS: Fully Convolutional One-Stage Object Detection
如果对你有帮助的话,希望帮我点个赞~
文章目录
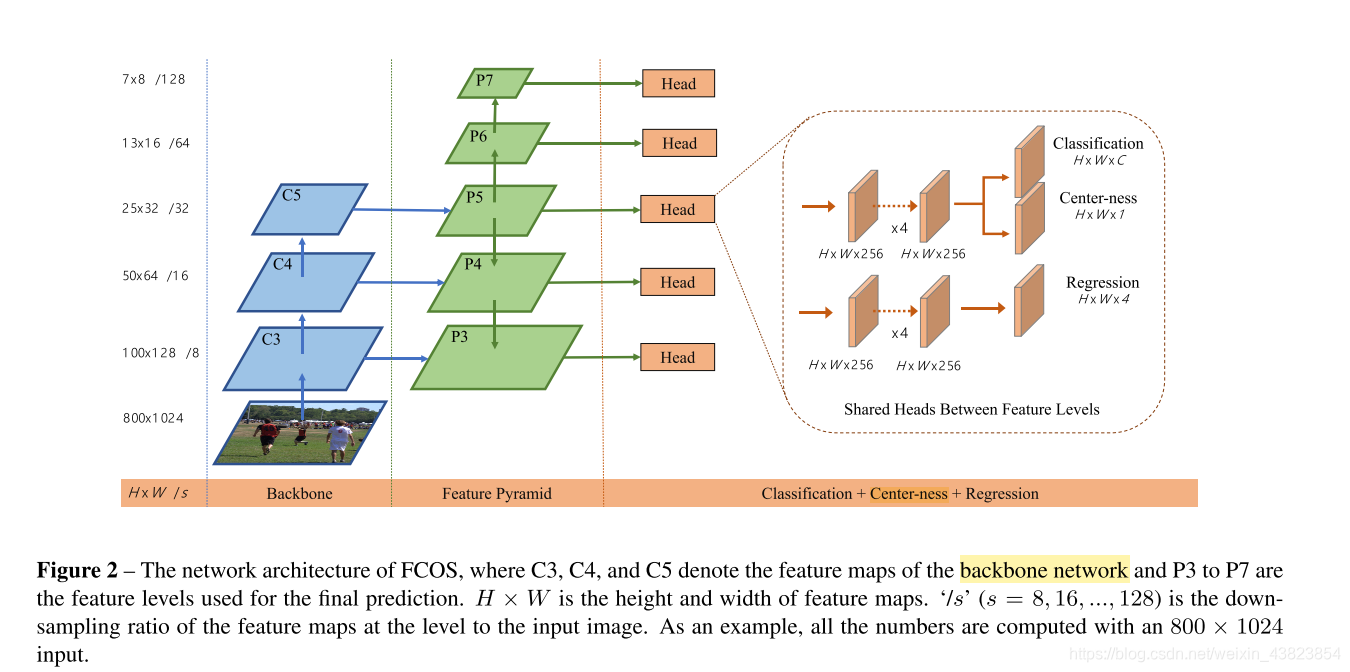
FCOS网络结构以及论文中重点内容
FCOS网络结构
注意文中提到的share weight指的是5个fpn层输出的特征图经过各自的share head,其中share head分为回归的4个conv 以及 分类的4个conv,共享权重指的是5个head 共享回归的conv权重以及分类的conv权重,而在同一个FPN中回归和分类各自的权重并不共享。
详情见代码部分。
feature = self.share_tower(feature) # torch.Size([1, 256, 52, 76]) torch.Size([1, 256, 26, 38])
cls_tower = self.cls_tower(feature) # torch.Size([1, 256, 52, 76])
bbox_tower = self.bbox_tower(feature) # torch.Size([1, 256, 52, 76])
self.cls_tower 以及 self.bbox_tower 用的都是统一的分类conv以及回归的conv,即共享权重。

5层FPN上的每个点映射回原图的公式。(s/2 + xs, s/2+ys)

根据max(l*, t*, r*, b*),FPN上的挑选postivie axample的限制条件。

centerness计算公式

1. AdelaiDet/adet/modeling/fcos/fcos.py
import math
from typing import List, Dict
import torch
from torch import nn
from torch.nn import functional as F
from detectron2.layers import ShapeSpec, NaiveSyncBatchNorm
from detectron2.modeling.proposal_generator.build import PROPOSAL_GENERATOR_REGISTRY
from adet.layers import DFConv2d, NaiveGroupNorm
from adet.utils.comm import compute_locations
from .fcos_outputs import FCOSOutputs
import pdb
__all__ = ["FCOS"]
INF = 100000000
class Scale(nn.Module):
def __init__(self, init_value=1.0):
super(Scale, self).__init__()
self.scale = nn.Parameter(torch.FloatTensor([init_value]))
def forward(self, input):
return input * self.scale
class ModuleListDial(nn.ModuleList):
def __init__(self, modules=None):
super(ModuleListDial, self).__init__(modules)
self.cur_position = 0
def forward(self, x):
result = self[self.cur_position](x)
self.cur_position += 1
if self.cur_position >= len(self):
self.cur_position = 0
return result
# 从detectron2/detectron2/modeling/proposal_generator/build.py PROPOSAL_GENERATOR_REGISTRY.get(name)(cfg, input_shape)
@PROPOSAL_GENERATOR_REGISTRY.register()
class FCOS(nn.Module):
"""
Implement FCOS (https://arxiv.org/abs/1904.01355).
"""
def __init__(self, cfg, input_shape: Dict[str, ShapeSpec]):
super().__init__()
self.in_features = cfg.MODEL.FCOS.IN_FEATURES # ["p3", "p4", "p5", "p6", "p7"]
self.fpn_strides = cfg.MODEL.FCOS.FPN_STRIDES # [8, 16, 32, 64, 128]
self.yield_proposal = cfg.MODEL.FCOS.YIELD_PROPOSAL # False
# 调用FCOSHead()函数
self.fcos_head = FCOSHead(cfg, [input_shape[f] for f in self.in_features])
pdb.set_trace()
self.in_channels_to_top_module = self.fcos_head.in_channels_to_top_module # 256
# 调用FCOSOutpues(cfg)
self.fcos_outputs = FCOSOutputs(cfg) #FCOSOutputs((loc_loss_func): IOULoss())
pdb.set_trace()
def forward_head(self, features, top_module=None):
features = [features[f] for f in self.in_features]
pred_class_logits, pred_deltas, pred_centerness, top_feats, bbox_towers = self.fcos_head(
features, top_module, self.yield_proposal)
pdb.set_trace()
return pred_class_logits, pred_deltas, pred_centerness, top_feats, bbox_towers
def forward(self, images, features, gt_instances=None, top_module=None):
"""
Arguments:
images (list[Tensor] or ImageList): images to be processed
targets (list[BoxList]): ground-truth boxes present in the image (optional)
Returns:
result (list[BoxList] or dict[Tensor]): the output from the model.
During training, it returns a dict[Tensor] which contains the losses.
During testing, it returns list[BoxList] contains additional fields
like `scores`, `labels` and `mask` (for Mask R-CNN models).
"""
pdb.set_trace()
features = [features[f] for f in self.in_features] # len(features) = num(FPN) = 5 详细见下面注释
# locations(x, y)就是相当于 训练时候的bbox的中心
locations = self.compute_locations(features) # 调用compute_locations len(locations) = 5
pdb.set_trace()
logits_pred, reg_pred, ctrness_pred, top_feats, bbox_towers = self.fcos_head( # 走了fcos_head的forward
features, top_module, self.yield_proposal
)
results = {
}
if self.yield_proposal: # self.yield_proposal: false
results["features"] = {
f: b for f, b in zip(self.in_features, bbox_towers)
}
if self.training:
results, losses = self.fcos_outputs.losses( # 调用fcos_outpus.py的losses()
logits_pred, reg_pred, ctrness_pred,
locations, gt_instances, top_feats
)
if self.yield_proposal:
with torch.no_grad():
results["proposals"] = self.fcos_outputs.predict_proposals(
logits_pred, reg_pred, ctrness_pred,
locations, images.image_sizes, top_feats
)
pdb.set_trace()
return results, losses # len(results) = 2 len(losses) =3
else:
results = self.fcos_outputs.predict_proposals(
logits_pred, reg_pred, ctrness_pred,
locations, images.image_sizes, top_feats
)
pdb.set_trace()
return results, {
}
def compute_locations(self, features):
locations = []
for level, feature in enumerate(features): # levels 0 - 4
h, w = feature.size()[-2:]
locations_per_level = compute_locations( # 调用comm.py的文件
h, w, self.fpn_strides[level],
feature.device
)
locations.append(locations_per_level)
pdb.set_trace() # len(locations) = 5
# locations[i].shape ==> (torch.Size([3952, 2]), torch.Size([988, 2]), torch.Size([247, 2]), torch.Size([70, 2]), torch.Size([20, 2]))
# example : locations[0].shape : torch.Size([3952, 2]) [1, 3, 52, 76] --> 3952 = 52 * 76 这就是全卷积网络,对于每一个pixel,进行计算
return locations
class FCOSHead(nn.Module):
def __init__(self, cfg, input_shape: List[ShapeSpec]):
"""
Arguments:
in_channels (int): number of channels of the input feature
"""
super().__init__()
# TODO: Implement the sigmoid version first.
self.num_classes = cfg.MODEL.FCOS.NUM_CLASSES # num_classes 80
self.fpn_strides = cfg.MODEL.FCOS.FPN_STRIDES # fpn_strides [8, 16, 32, 64, 128]
head_configs = {
"cls": (cfg.MODEL.FCOS.NUM_CLS_CONVS,
cfg.MODEL.FCOS.USE_DEFORMABLE),
"bbox": (cfg.MODEL.FCOS.NUM_BOX_CONVS,
cfg.MODEL.FCOS.USE_DEFORMABLE),
"share": (cfg.MODEL.FCOS.NUM_SHARE_CONVS,
False)}
# head_configs = {'cls': (4, False), 'bbox': (4, False), 'share': (0, False)}
norm = None if cfg.MODEL.FCOS.NORM == "none" else cfg.MODEL.FCOS.NORM # GN
self.num_levels = len(input_shape) # 5
in_channels = [s.channels for s in input_shape] # 256
assert len(set(in_channels)) == 1, "Each level must have the same channel!"
in_channels = in_channels[0] # in_channels 256
# input_shape:
# [
# ShapeSpec(channels=256, height=None, width=None, stride=8),
# ShapeSpec(channels=256, height=None, width=None, stride=16),
# ShapeSpec(channels=256, height=None, width=None, stride=32),
# ShapeSpec(channels=256, height=None, width=None, stride=64),
# ShapeSpec(channels=256, height=None, width=None, stride=128)
# ]
self.in_channels_to_top_module = in_channels # 256
for head in head_configs:
tower = []
num_convs, use_deformable = head_configs[head]
for i in range(num_convs):
if use_deformable and i == num_convs - 1:
conv_func = DFConv2d
else:
conv_func = nn.Conv2d
tower.append(conv_func(
in_channels, in_channels,
kernel_size=3, stride=1,
padding=1, bias=True
))
if norm == "GN":
tower.append(nn.GroupNorm(32, in_channels))
elif norm == "NaiveGN":
tower.append(NaiveGroupNorm(32, in_channels))
elif norm == "BN":
tower.append(ModuleListDial([
nn.BatchNorm2d(in_channels) for _ in range(self.num_levels)
]))
elif norm == "SyncBN":
tower.append(ModuleListDial([
NaiveSyncBatchNorm(in_channels) for _ in range(self.num_levels)
]))
tower.append(nn.ReLU())
self.add_module('{}_tower'.format(head),
nn.Sequential(*tower))
self.cls_logits = nn.Conv2d(
in_channels, self.num_classes,
kernel_size=3, stride=1,
padding=1
)
# cls_logtis
# Conv2d(256, 3, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# 256 --> 3 num_classes = 3
self.bbox_pred = nn.Conv2d(
in_channels, 4, kernel_size=3,
stride=1, padding=1
)
# bbox_pred
# Conv2d(256, 4, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# 256 --> 4 [left, top, right, bottom] 4d-vector
self.ctrness = nn.Conv2d(
in_channels, 1, kernel_size=3,
stride=1, padding=1
)
# ctrness
# Conv2d(256, 1, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# 256 --> 1 h * w * 1
pdb.set_trace()
if cfg.MODEL.FCOS.USE_SCALE: # True
self.scales = nn.ModuleList([Scale(init_value=1.0) for _ in range(self.num_levels)])
else:
self.scales = None
for modules in [
self.cls_tower, self.bbox_tower,
self.share_tower, self.cls_logits,
self.bbox_pred, self.ctrness
]:
for l in modules.modules():
if isinstance(l, nn.Conv2d):
torch.nn.init.normal_(l.weight, std=0.01)
torch.nn.init.constant_(l.bias, 0)
# self.add_module:
# cls_tower:
# (Sequential(
# (0): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (1): GroupNorm(32, 256, eps=1e-05, affine=True)
# (2): ReLU()
# (3): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (4): GroupNorm(32, 256, eps=1e-05, affine=True)
# (5): ReLU()
# (6): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (7): GroupNorm(32, 256, eps=1e-05, affine=True)
# (8): ReLU()
# (9): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (10): GroupNorm(32, 256, eps=1e-05, affine=True)
# (11): ReLU()
# bbox_tower:
# Sequential(
# (0): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (1): GroupNorm(32, 256, eps=1e-05, affine=True)
# (2): ReLU()
# (3): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (4): GroupNorm(32, 256, eps=1e-05, affine=True)
# (5): ReLU()
# (6): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (7): GroupNorm(32, 256, eps=1e-05, affine=True)
# (8): ReLU()
# (9): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (10): GroupNorm(32, 256, eps=1e-05, affine=True)
# (11): ReLU()
# share_tower --> 空
# Sequential()
# cls_logits
# (Conv2d(256, 3, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)), Conv2d(256, 1, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)))
# ctrness
# Conv2d(256, 1, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# bbox_pred
# Conv2d(256, 4, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# scales: ModuleList(
# (0): Scale()
# (1): Scale()
# (2): Scale()
# (3): Scale()
# (4): Scale()
# )
# initialize the bias for focal loss
prior_prob = cfg.MODEL.FCOS.PRIOR_PROB # 0.01
bias_value = -math.log((1 - prior_prob) / prior_prob) # log(1 - 0.01) / 0.01
torch.nn.init.constant_(self.cls_logits.bias, bias_value) # self.cls_logits.bias: tensor([ 0.0070, -0.0133, -0.0184], requires_grad=True)
pdb.set_trace()
def forward(self, x, top_module=None, yield_bbox_towers=False):
logits = []
bbox_reg = []
ctrness = []
top_feats = []
bbox_towers = []
for l, feature in enumerate(x):
# x --> list x[tensor()] x[0] --> tensor
# len(x) = 5 循环5次
# x[0].shape, x[1].shape, x[2].shape, x[3].shape, x[4].shape
# (torch.Size([1, 256, 52, 76]), torch.Size([1, 256, 26, 38]), torch.Size([1, 256, 13, 19]), torch.Size([1, 256, 7, 10]), torch.Size([1, 256, 4, 5]))
# feature, torch.Size([1, 256, 52, 76])
# feature经过cls_tower 以及 bbox_tower网络训练
feature = self.share_tower(feature) # torch.Size([1, 256, 52, 76]) torch.Size([1, 256, 26, 38])
cls_tower = self.cls_tower(feature) # torch.Size([1, 256, 52, 76])
bbox_tower = self.bbox_tower(feature) # torch.Size([1, 256, 52, 76])
if yield_bbox_towers: # false
bbox_towers.append(bbox_tower)
logits.append(self.cls_logits(cls_tower))
ctrness.append(self.ctrness(bbox_tower))
reg = self.bbox_pred(bbox_tower)
if self.scales is not None:
reg = self.scales[l](reg)
# Note that we use relu, as in the improved FCOS, instead of exp.
bbox_reg.append(F.relu(reg))
if top_module is not None:
top_feats.append(top_module(bbox_tower))
pdb.set_trace()
return logits, bbox_reg, ctrness, top_feats, bbox_towers
# logits[i].shape len(logits) = 5
# (torch.Size([1, Num_classes, 52, 76]), torch.Size([1, Num_classes, 26, 38]), torch.Size([1, Num_classes, 13, 19]), torch.Size([1, Num_classes, 7, 10]), torch.Size([1, Num_classes, 4, 5]))
# bbox_reg[i].shape
# (torch.Size([1, 4, 52, 76]), torch.Size([1, 4, 26, 38]), torch.Size([1, 4, 13, 19]), torch.Size([1, 4, 7, 10]), torch.Size([1, 4, 4, 5]))
# ctrness[i].shape
# (torch.Size([1, 1, 52, 76]), torch.Size([1, 1, 26, 38]), torch.Size([1, 1, 13, 19]), torch.Size([1, 1, 7, 10]), torch.Size([1, 1, 4, 5]))
# when training, top_feats is empty[]
'''
(Pdb) top_feats
[]
(Pdb) bbox_towers
[]
'''
'''
images:
len(images) = 4 # batch_size
(Pdb) images[0].size()
torch.Size([3, 796, 1333])
(Pdb) images[1].size()
torch.Size([3, 800, 1067])
(Pdb) images[2].size()
torch.Size([3, 800, 1208])
(Pdb) images[3].size()
torch.Size([3, 800, 1199])
features:
(Pdb) len(features)
5
(Pdb) type(features)
<class 'dict'>
(Pdb) len(features)
5
(Pdb) type(features['p3'])
<class 'torch.Tensor'>
(Pdb) features.keys()
dict_keys(['p3', 'p4', 'p5', 'p6', 'p7'])
(Pdb) features['p3'].size()
torch.Size([4, 256, 100, 168])
(Pdb) features['p4'].size()
torch.Size([4, 256, 50, 84])
(Pdb) features['p5'].size()
torch.Size([4, 256, 25, 42])
(Pdb) features['p6'].size()
torch.Size([4, 256, 13, 21])
(Pdb) features['p7'].size()
torch.Size([4, 256, 7, 11])
(Pdb) gt_instances
len(gt_instances) = 4
(Pdb) gt_instances[0]
Instances(num_instances=1, image_height=796, image_width=1333, fields=[gt_boxes: Boxes(tensor([[ 495.7760, 499.0487, 1057.7688, 663.6442]], device='cuda:0')), gt_classes: tensor([71], device='cuda:0')])
(Pdb) gt_instances[1]
[[DInstances(num_instances=15, image_height=800, image_width=1067, fields=[gt_boxes: Boxes(tensor([[ 482.0673, 70.1667, 979.0725, 775.1000],
[ 162.0007, 86.8333, 625.1620, 775.5667],
[ 540.8690, 67.5500, 606.1227, 165.7000],
[ 604.8557, 55.1167, 669.3591, 158.6333],
[ 433.5355, 60.9333, 516.9781, 201.9333],
[ 224.0534, 19.8500, 308.5297, 222.3000],
[ 98.1139, 55.5333, 177.6555, 216.3833],
[ 880.6085, 168.0667, 937.5095, 250.1500],
[ 45.6643, 431.8667, 213.9501, 549.9833],
[ 901.5150, 322.3500, 1002.3632, 604.6333],
[ 468.1629, 212.1333, 545.4871, 267.8667],
[ 578.2806, 183.0000, 673.3270, 259.4833],
[ 685.3808, 13.5333, 764.7556, 137.0500],
[ 47.1648, 227.1667, 116.8532, 276.7333],
[ 34.7275, 96.5833, 96.3801, 225.6333]], device='cuda:0')), gt_classes: tensor([ 0, 0, 0, 0, 0, 0, 0, 0, 34, 34, 0, 0, 0, 0, 0],
device='cuda:0')])
(Pdb) gt_instances[2]
Instances(num_instances=16, image_height=800, image_width=1208, fields=[gt_boxes: Boxes(tensor([[ 137.3534, 567.5095, 815.9096, 791.2264],
[ 747.8652, 569.3019, 1208.0000, 789.4340],
[ 491.8447, 28.4717, 502.6978, 93.0000],
[ 202.6798, 276.8491, 564.1549, 600.4528],
[ 558.0204, 110.3208, 637.0690, 201.0566],
[ 437.8246, 34.3585, 505.6235, 192.4717],
[ 613.8527, 315.5660, 926.6115, 656.7548],
[ 0.0000, 506.0189, 70.1018, 593.1509],
[ 570.1760, 499.3774, 645.6572, 586.9246],
[ 562.0031, 140.1887, 581.4255, 158.5094],
[ 0.0000, 576.9811, 93.5067, 800.0000],
[ 844.9960, 503.9434, 892.6176, 536.6603],
[ 473.8947, 478.2641, 527.3109, 511.4529],
[ 624.1963, 67.9057, 705.8683, 209.0755],
[ 935.6904, 328.3773, 1201.7712, 577.7170],
[ 81.3512, 517.3962, 172.8006, 644.1509]], device='cuda:0')), gt_classes: tensor([56, 56, 34, 0, 0, 0, 0, 0, 0, 35, 56, 0, 0, 0, 0, 0],
device='cuda:0')])
(Pdb) gt_instances[3]
Instances(num_instances=6, image_height=800, image_width=1199, fields=[gt_boxes: Boxes(tensor([[ 799.9578, 48.4871, 1190.1012, 701.7330],
[ 692.1040, 40.8056, 952.7554, 734.7260],
[ 34.6586, 390.4262, 163.6448, 431.9438],
[ 880.0472, 120.8431, 969.2791, 159.0820],
[ 884.8995, 379.5972, 934.4894, 396.9087],
[ 2.0795, 367.7939, 536.0841, 704.4122]], device='cuda:0')), gt_classes: tensor([72, 0, 45, 45, 45, 60], device='cuda:0')])
'''
2. AdelaiDet/adet/modeling/fcos/fcos_outputs.py
import logging
import torch
from torch import nn
import torch.nn.functional as F
from detectron2.layers import cat
from detectron2.structures import Instances, Boxes
from detectron2.utils.comm import get_world_size
from fvcore.nn import sigmoid_focal_loss_jit
from adet.utils.comm import reduce_sum
from adet.layers import ml_nms, IOULoss
import pdb
logger = logging.getLogger(__name__)
INF = 100000000
"""
Shape shorthand in this module:
N: number of images in the minibatch
L: number of feature maps per image on which RPN is run
Hi, Wi: height and width of the i-th feature map
4: size of the box parameterization
Naming convention:
labels: refers to the ground-truth class of an position.
reg_targets: refers to the 4-d (left, top, right, bottom) distances that parameterize the ground-truth box.
logits_pred: predicted classification scores in [-inf, +inf];
reg_pred: the predicted (left, top, right, bottom), corresponding to reg_targets
ctrness_pred: predicted centerness scores
"""
def compute_ctrness_targets(reg_targets):
if len(reg_targets) == 0:
return reg_targets.new_zeros(len(reg_targets))
#print("reg_targets.shape: ", reg_targets.shape) # torch.Size([155, 4]) 155代表正样本。
'''
reg_targets:
tensor([[3.5625, 7.6250, 5.3750, 8.0000],
[4.5625, 7.6250, 4.3750, 8.0000],
[5.5625, 7.6250, 3.3750, 8.0000],
[1.0312, 3.0625, 3.4375, 4.7500],
[2.0312, 3.0625, 2.4375, 4.7500],
[3.0312, 3.0625, 1.4375, 4.7500],
[1.0312, 4.0625, 3.4375, 3.7500],
[2.0312, 4.0625, 2.4375, 3.7500],
[3.0312, 4.0625, 1.4375, 3.7500],
[1.0312, 5.0625, 3.4375, 2.7500],
[2.0312, 5.0625, 2.4375, 2.7500],
[3.0312, 5.0625, 1.4375, 2.7500]], device='cuda:0')
'''
pdb.set_trace()
left_right = reg_targets[:, [0, 2]] # torch.Size([12, 2])
top_bottom = reg_targets[:, [1, 3]] # torch.Size([12, 2])
'''
top_bottom:
tensor([[7.6250, 8.0000],
[7.6250, 8.0000],
[7.6250, 8.0000],
[3.0625, 4.7500],
[3.0625, 4.7500],
[3.0625, 4.7500],
[4.0625, 3.7500],
[4.0625, 3.7500],
[4.0625, 3.7500],
[5.0625, 2.7500],
[5.0625, 2.7500],
[5.0625, 2.7500]], device='cuda:0')
left_right:
tensor([[3.5625, 5.3750],
[4.5625, 4.3750],
[5.5625, 3.3750],
[1.0312, 3.4375],
[2.0312, 2.4375],
[3.0312, 1.4375],
[1.0312, 3.4375],
[2.0312, 2.4375],
[3.0312, 1.4375],
[1.0312, 3.4375],
[2.0312, 2.4375],
[3.0312, 1.4375]], device='cuda:0')
'''
ctrness = (left_right.min(dim=-1)[0] / left_right.max(dim=-1)[0]) * \
(top_bottom.min(dim=-1)[0] / top_bottom.max(dim=-1)[0]) # torch.size([12])
'''
tensor([0.6317, 0.9140, 0.5783, 0.1934, 0.5373, 0.3058, 0.2769, 0.7692, 0.4377,
0.1630, 0.4527, 0.2576], device='cuda:0')
'''
return torch.sqrt(ctrness)
#__init__, _transpose, _get_ground_truth, get_sample_region
class FCOSOutputs(nn.Module):
def __init__(self, cfg):
super(FCOSOutputs, self).__init__()
self.focal_loss_alpha = cfg.MODEL.FCOS.LOSS_ALPHA # 0.25
self.focal_loss_gamma = cfg.MODEL.FCOS.LOSS_GAMMA # 2.0
self.center_sample = cfg.MODEL.FCOS.CENTER_SAMPLE # True
self.radius = cfg.MODEL.FCOS.POS_RADIUS # POS_RADIUS = 1.5
self.pre_nms_thresh_train = cfg.MODEL.FCOS.INFERENCE_TH_TRAIN # 0.05
self.pre_nms_topk_train = cfg.MODEL.FCOS.PRE_NMS_TOPK_TRAIN # 1000
self.post_nms_topk_train = cfg.MODEL.FCOS.POST_NMS_TOPK_TRAIN # 100
self.loc_loss_func = IOULoss(cfg.MODEL.FCOS.LOC_LOSS_TYPE) # IOULoss
self.pre_nms_thresh_test = cfg.MODEL.FCOS.INFERENCE_TH_TEST # 0.05
self.pre_nms_topk_test = cfg.MODEL.FCOS.PRE_NMS_TOPK_TEST # 1000
self.post_nms_topk_test = cfg.MODEL.FCOS.POST_NMS_TOPK_TEST # 100
self.nms_thresh = cfg.MODEL.FCOS.NMS_TH # 0.6
self.thresh_with_ctr = cfg.MODEL.FCOS.THRESH_WITH_CTR # Flase
self.num_classes = cfg.MODEL.FCOS.NUM_CLASSES # 80
self.strides = cfg.MODEL.FCOS.FPN_STRIDES # [8, 16, 32, 64, 128]
# generate sizes of interest
soi = []
prev_size = -1
for s in cfg.MODEL.FCOS.SIZES_OF_INTEREST: # cfg.MODEL.FCOS.SIZES_OF_INTEREST : [64, 128, 256, 512]
soi.append([prev_size, s])
prev_size = s
soi.append([prev_size, INF])
self.sizes_of_interest = soi # [[-1, 64], [64, 128], [128, 256], [256, 512], [512, 100000000]]
pdb.set_trace()
def _transpose(self, training_targets, num_loc_list):
'''
This function is used to transpose image first training targets to level first ones
:return: level first training targets
'''
for im_i in range(len(training_targets)):
training_targets[im_i] = torch.split(
training_targets[im_i], num_loc_list, dim=0
)
# type( training_targets[im_i]) --> tuple() len(training_targets) = instances, len(training_targets[i]) = 5
targets_level_first = []
for targets_per_level in zip(*training_targets):
targets_level_first.append(
torch.cat(targets_per_level, dim=0)
)
pdb.set_trace()
return targets_level_first # 把training_targets的5个value都进行transpose划分到每个FPN。 eg. 第一个len(targets_level_first) = 5 targets_level_first[0].size() = 33600 = 16800 * 2 = 第i个fpn层的像素点 * batch_size
# _get_ground_truth 调用了 compute_targets_for_locations() 和 _transpose()
def _get_ground_truth(self, locations, gt_instances):
# gt_instances:
# [Instances(num_instances=4, image_height=400, image_width=600,
# fields=
# [gt_boxes:
# Boxes(tensor([[192., 210., 233., 240.],[137., 210., 177., 238.],[197., 193., 224., 238.],[143., 197., 170., 237.]], device='cuda:0')),
# gt_classes: tensor([0, 0, 2, 2], device='cuda:0')])]
num_loc_list = [len(loc) for loc in locations] # num_loc_list [16800, 4200, 1050, 273, 77]
# compute locations to size ranges
loc_to_size_range = []
for l, loc_per_level in enumerate(locations):
# 根据paper,争对max(l*,r*,t*,b*),每层FPN设置M_i M_(i-1)的值进行分配
#self.sizes_of_interest [[-1, 64], [64, 128], [128, 256], [256, 512], [512, 100000000]] 相当于将FPN每层上的点对应到了input image原图上,然后原图上的点进行设置Mi的划分,见论文。
loc_to_size_range_per_level = loc_per_level.new_tensor(self.sizes_of_interest[l]) # torch.size([2])
loc_to_size_range.append(
loc_to_size_range_per_level[None].expand(num_loc_list[l], -1)
) # loc_to_size_range_per_level[None].expand(num_loc_list[l], -1) --> 就是 torch.size([2]) --> torch.size([1, 2]) --> torch.size([16800, 2])
pdb.set_trace()
loc_to_size_range = torch.cat(loc_to_size_range, dim=0) # [22400 , 2] 第一维代表像素点的个数,第二维代表每个像素点的(x,y)
locations = torch.cat(locations, dim=0) # [22400 , 2]
pdb.set_trace()
training_targets = self.compute_targets_for_locations( # 调用了 compute_targets_for_locations()
locations, gt_instances, loc_to_size_range, num_loc_list
)
training_targets["locations"] = [locations.clone() for _ in range(len(gt_instances))] # [22400, 2]
training_targets["im_inds"] = [
locations.new_ones(locations.size(0), dtype=torch.long) * i for i in range(len(gt_instances))
]
# transpose im first training_targets to level first ones
training_targets = {
k: self._transpose(v, num_loc_list) for k, v in training_targets.items()
}
training_targets["fpn_levels"] = [ # [3952, 988, 247, 70, 20]
loc.new_ones(len(loc), dtype=torch.long) * level
for level, loc in enumerate(training_targets["locations"])
]
#print(training_targets["fpn_levels"])
# we normalize reg_targets by FPN's strides here
reg_targets = training_targets["reg_targets"] # [3952, 4] [988, 4] [274, 4] [70, 4] [20, 4]
for l in range(len(reg_targets)):
reg_targets[l] = reg_targets[l] / float(self.strides[l])
pdb.set_trace()
return training_targets # dict_keys(['labels', 'reg_targets', 'target_inds', 'locations', 'im_inds', 'fpn_levels'])
# 输出false, ture的采样矩阵
def get_sample_region(self, boxes, strides, num_loc_list, loc_xs, loc_ys, bitmasks=None, radius=1):
if bitmasks is not None:
_, h, w = bitmasks.size()
ys = torch.arange(0, h, dtype=torch.float32, device=bitmasks.device)
xs = torch.arange(0, w, dtype=torch.float32, device=bitmasks.device)
m00 = bitmasks.sum(dim=-1).sum(dim=-1).clamp(min=1e-6)
m10 = (bitmasks * xs).sum(dim=-1).sum(dim=-1)
m01 = (bitmasks * ys[:, None]).sum(dim=-1).sum(dim=-1)
center_x = m10 / m00
center_y = m01 / m00
else:
# boxes [2, 4] dim=-1表示对最后一维度求和。 center_x center_y 求中心坐标(相加除2)
center_x = boxes[..., [0, 2]].sum(dim=-1) * 0.5 # boxes[..., [0, 2]] --> [ 2]
center_y = boxes[..., [1, 3]].sum(dim=-1) * 0.5
pdb.set_trace()
num_gts = boxes.shape[0] # 2 gt_instances的数量
K = len(loc_xs) # 5277
boxes = boxes[None].expand(K, num_gts, 4) # [5277, 2, 4] dim = 1 --> num_classes:2
center_x = center_x[None].expand(K, num_gts) # [5277, 2]
center_y = center_y[None].expand(K, num_gts) # [5277, 2]
center_gt = boxes.new_zeros(boxes.shape) # [5277, 2, 4]
# no gt
if center_x.numel() == 0 or center_x[..., 0].sum() == 0:
return loc_xs.new_zeros(loc_xs.shape, dtype=torch.uint8)
beg = 0
for level, num_loc in enumerate(num_loc_list): # [3952, 988, 247, 70, 20]
end = beg + num_loc #
stride = strides[level] * radius # strides [8, 16, 32, 64, 128]
xmin = center_x[beg:end] - stride
ymin = center_y[beg:end] - stride
xmax = center_x[beg:end] + stride
ymax = center_y[beg:end] + stride
# limit sample region in gt
center_gt[beg:end, :, 0] = torch.where(xmin > boxes[beg:end, :, 0], xmin, boxes[beg:end, :, 0])
center_gt[beg:end, :, 1] = torch.where(ymin > boxes[beg:end, :, 1], ymin, boxes[beg:end, :, 1])
center_gt[beg:end, :, 2] = torch.where(xmax > boxes[beg:end, :, 2], boxes[beg:end, :, 2], xmax)
center_gt[beg:end, :, 3] = torch.where(ymax > boxes[beg:end, :, 3], boxes[beg:end, :, 3], ymax)
beg = end
pdb.set_trace()
#l, r, t, b
left = loc_xs[:, None] - center_gt[..., 0] # [5277, num_instance]
right = center_gt[..., 2] - loc_xs[:, None] # [5277, num_instance]
top = loc_ys[:, None] - center_gt[..., 1] # [5277, num_instance]
bottom = center_gt[..., 3] - loc_ys[:, None] # [5277, num_instance]
center_bbox = torch.stack((left, top, right, bottom), -1) # [5277, 2] --> [5277, num_instance, 4] torch.stack(x, dim=-1)指在新增加的一维进行扩充
inside_gt_bbox_mask = center_bbox.min(-1)[0] > 0 #bool [5277, 2]
# inside_gt_bbox_mask 判断图像中的每个像素点是否是正样本,若为正样本,则为True
pdb.set_trace()
return inside_gt_bbox_mask
#调用get_sample_region()函数
def compute_targets_for_locations(self, locations, targets, size_ranges, num_loc_list): # target 就是 gt_instances, len(targets) = batch size
pdb.set_trace()
labels = []
reg_targets = []
target_inds = []
xs, ys = locations[:, 0], locations[:, 1] # xs, ys 是每个像素点的坐标 xs, ys :[22400]
num_targets = 0
for im_i in range(len(targets)):
targets_per_im = targets[im_i] # Instances(num_instances=2, image_height=400, image_width=600, fields=[gt_boxes: Boxes(tensor([[401., 65., 523., 339.],[336., 68., 441., 318.]], device='cuda:0')), gt_classes: tensor([2, 2], device='cuda:0')])
# spec的使用
bboxes = targets_per_im.gt_boxes.tensor # [2, 4] 4d vector
labels_per_im = targets_per_im.gt_classes # 类别
# no gt
if bboxes.numel() == 0: # torch.numel() 返回元素数目 (torch.numel)
labels.append(labels_per_im.new_zeros(locations.size(0)) + self.num_classes)
reg_targets.append(locations.new_zeros((locations.size(0), 4)))
target_inds.append(labels_per_im.new_zeros(locations.size(0)) - 1)
continue
area = targets_per_im.gt_boxes.area() # area = (ymax - ymin) * (xmax - xmin) torch.size([1])
# bboxes(x1, y1, x2, y2) compute center (l, t, r, b)
# xs[:, None] --> size(): [22400, 1]
# a[10 , 1] b[1, 2] (a-b).size() --> (10,2) 我认为这是一种广播!
l = xs[:, None] - bboxes[:, 0][None] # tensor[None]永远都是补充在第一维。eg [2] --> [1, 2]; bboxes[:, 0][None] --> [1, instance]; xs[:, None] --> [22400, instance]; l --> [22400, instance]
t = ys[:, None] - bboxes[:, 1][None]
r = bboxes[:, 2][None] - xs[:, None] # [22400, instance] 22400 表示 图片经过了5个fpn。22400 = \sum(hi * wi) 像素点的个数
b = bboxes[:, 3][None] - ys[:, None] # [22400, instance]
reg_targets_per_im = torch.stack([l, t, r, b], dim=2) # [22400, instance, 4]
pdb.set_trace()
if self.center_sample: # True 采用中心采样方法 难点理解和论文不太一样的地方
if targets_per_im.has("gt_bitmasks_full"): # false
bitmasks = targets_per_im.gt_bitmasks_full
else:
bitmasks = None
# 调用get_sample_region
# [22400, instances] is_in_boxes表示根据gt的中心点(center_x, center_y)以及围绕中心点的radius半径的一个中心采样(center sample)区域,进行筛选。
is_in_boxes = self.get_sample_region(
bboxes, self.strides, num_loc_list, xs, ys,
bitmasks=bitmasks, radius=self.radius
)
else:
# 如果不采用canter_sample 这就是论文中直接拿location和bbox之间的是否在里面的关系。
# is_in_boxes 得到[l,t,r,b]中最小的一个点是否大于0的bool值。
is_in_boxes = reg_targets_per_im.min(dim=2)[0] > 0 #如果小于0 代表负样本 注意torch.min() 返回值有value和index。a.min(dim=2)[0]代表取value
# max_reg_targets_per_im 得到[l,t,r,b]中最大的一个点。
max_reg_targets_per_im = reg_targets_per_im.max(dim=2)[0]
# limit the regression range for each location
# 根据paper 这样就把FPN层的map回input image的每个的像素的点进行限制。
is_cared_in_the_level = \
(max_reg_targets_per_im >= size_ranges[:, [0]]) & \
(max_reg_targets_per_im <= size_ranges[:, [1]])
# [22400, instances] bool类型
locations_to_gt_area = area[None].repeat(len(locations), 1) # [22400, instances]
locations_to_gt_area[is_in_boxes == 0] = INF # 1. 第一个限制,把在center sample区域外面的location置为负样本。
locations_to_gt_area[is_cared_in_the_level == 0] = INF # 2. 第二个限制,把max(l,r,t,b)超过或者低于第i个FPN层,就相当于把大小物体的预测分开了
# if there are still more than one objects for a location,
# we choose the one with minimal area
locations_to_min_area, locations_to_gt_inds = locations_to_gt_area.min(dim=1)
# reg_targets_per_im [22400, instances, 4] 取经过筛选后的回归的点。
reg_targets_per_im = reg_targets_per_im[range(len(locations)), locations_to_gt_inds] # [22400, instances, 4]
target_inds_per_im = locations_to_gt_inds + num_targets # 为什么要加num_targets??? 答: blendmask中有用到
num_targets += len(targets_per_im) # len(targets_per_im) 的值是 Instances(num_instances=23,........)中的23,也就是instances的个数。
labels_per_im = labels_per_im[locations_to_gt_inds]
labels_per_im[locations_to_min_area == INF] = self.num_classes # 如果min area还是为INF,那么就把负样本的点的类别设置为80 backbround
labels.append(labels_per_im) # [22400]
reg_targets.append(reg_targets_per_im) # [22400, 4]
target_inds.append(target_inds_per_im) # [22400]
pdb.set_trace()
pdb.set_trace()
return {
"labels": labels,
"reg_targets": reg_targets,
"target_inds": target_inds
}
def losses(self, logits_pred, reg_pred, ctrness_pred, locations, gt_instances, top_feats=None):
"""
Return the losses from a set of FCOS predictions and their associated ground-truth.
Returns:
dict[loss name -> loss value]: A dict mapping from loss name to loss value.
"""
#losses 调用了 _get_ground_truth函数
training_targets = self._get_ground_truth(locations, gt_instances)
# Collect all logits and regression predictions over feature maps
# and images to arrive at the same shape as the labels and targets
# The final ordering is L, N, H, W from slowest to fastest axis.
instances = Instances((0, 0))
instances.labels = cat([
# Reshape: (N, 1, Hi, Wi) -> (N*Hi*Wi,)
x.reshape(-1) for x in training_targets["labels"]
], dim=0)
instances.gt_inds = cat([
# Reshape: (N, 1, Hi, Wi) -> (N*Hi*Wi,)
x.reshape(-1) for x in training_targets["target_inds"]
], dim=0)
instances.im_inds = cat([
x.reshape(-1) for x in training_targets["im_inds"]
], dim=0)
instances.reg_targets = cat([
# Reshape: (N, Hi, Wi, 4) -> (N*Hi*Wi, 4)
x.reshape(-1, 4) for x in training_targets["reg_targets"]
], dim=0,)
instances.locations = cat([
x.reshape(-1, 2) for x in training_targets["locations"]
], dim=0)
instances.fpn_levels = cat([
x.reshape(-1) for x in training_targets["fpn_levels"]
], dim=0)
instances.logits_pred = cat([
# Reshape: (N, C, Hi, Wi) -> (N, Hi, Wi, C) -> (N*Hi*Wi, C)
x.permute(0, 2, 3, 1).reshape(-1, self.num_classes) for x in logits_pred
], dim=0,)
instances.reg_pred = cat([
# Reshape: (N, B, Hi, Wi) -> (N, Hi, Wi, B) -> (N*Hi*Wi, B)
x.permute(0, 2, 3, 1).reshape(-1, 4) for x in reg_pred
], dim=0,)
instances.ctrness_pred = cat([
# Reshape: (N, 1, Hi, Wi) -> (N*Hi*Wi,)
x.permute(0, 2, 3, 1).reshape(-1) for x in ctrness_pred
], dim=0,)
if len(top_feats) > 0: # blendmask
instances.top_feats = cat([
# Reshape: (N, -1, Hi, Wi) -> (N*Hi*Wi, -1) [784, -1]
x.permute(0, 2, 3, 1).reshape(-1, x.size(1)) for x in top_feats
], dim=0,)\
'''
in blendmask:
top_feats[0].size()
torch.Size([2, 784, 96, 148])
top_feats[1].size()
torch.Size([2, 784, 48, 74])
top_feats[2].size()
torch.Size([2, 784, 24, 37])
top_feats[3].size()
torch.Size([2, 784, 12, 19])
top_feats[4].size()
torch.Size([2, 784, 6, 10])
'''
# instances.top_feats.size() [37872, 784] 在接下来的fcos_losses(self, instances)函数中会继续筛选,最后只剩下[instances, 784]的大小。
# 这就是attention的矩阵方法:
# 每一行有784个特征。784代表又784个channel,而37872代表了hw * batchsize的大小.
# 说白了就把二维的图像h*w平铺成了1维度hw
pdb.set_trace()
return self.fcos_losses(instances)
def fcos_losses(self, instances):
num_classes = instances.logits_pred.size(1)
assert num_classes == self.num_classes
labels = instances.labels.flatten() # [36268]
pdb.set_trace()
# 开始将 H * W * 5(eg 36268)的像素点 筛选到只包含正样本的数量。
pos_inds = torch.nonzero(labels != num_classes).squeeze(1)# [155], 因为num_classes = 80代表的是负样本(正样本应该是0 ~ 79), 因此labels != num_classes计算正样本的索引
num_pos_local = pos_inds.numel() # eg. 155 总共正样本的像素点
num_gpus = get_world_size()
total_num_pos = reduce_sum(pos_inds.new_tensor([num_pos_local])).item() # 155
num_pos_avg = max(total_num_pos / num_gpus, 1.0)
# prepare one_hot
class_target = torch.zeros_like(instances.logits_pred) # [36268, 80]
class_target[pos_inds, labels[pos_inds]] = 1
class_loss = sigmoid_focal_loss_jit(
instances.logits_pred, #eg. [36268, 80]
class_target, # eg. [36268, 80]
alpha=self.focal_loss_alpha,
gamma=self.focal_loss_gamma,
reduction="sum", # 求和
) / num_pos_avg # 只除以前景框的数量, reference: https://blog.csdn.net/bhfs9999/article/details/103754077
instances = instances[pos_inds] # 这一步后 len(instances) = 155 直接筛选了到所需的instances
instances.pos_inds = pos_inds # 同样筛选pos_inds
pdb.set_trace()
ctrness_targets = compute_ctrness_targets(instances.reg_targets)
#调式
pdb.set_trace()
ctrness_targets_sum = ctrness_targets.sum()
loss_denorm = max(reduce_sum(ctrness_targets_sum).item() / num_gpus, 1e-6)
instances.gt_ctrs = ctrness_targets
#IOU LOSS FCOS是先检测每个点是否为正样本,得到类别后,再根据这些正样本去检测
if pos_inds.numel() > 0: # 并且将ctrness的gt值, 加入了reg_loss中训练
# IOU loss
reg_loss = self.loc_loss_func(
instances.reg_pred, # eg. [155, 4]
instances.reg_targets, # eg. [155, 4]
ctrness_targets # eg. [155]
) / loss_denorm # loss_denor为ctrness_targets.sum()
ctrness_loss = F.binary_cross_entropy_with_logits(
instances.ctrness_pred,
ctrness_targets,
reduction="sum"
) / num_pos_avg # num_pos_avg为前景框的数量
else:
reg_loss = instances.reg_pred.sum() * 0
ctrness_loss = instances.ctrness_pred.sum() * 0
losses = {
"loss_fcos_cls": class_loss,
"loss_fcos_loc": reg_loss,
"loss_fcos_ctr": ctrness_loss
}
extras = {
"instances": instances,
"loss_denorm": loss_denorm
}
return extras, losses
def predict_proposals(
self, logits_pred, reg_pred, ctrness_pred,
locations, image_sizes, top_feats=None
):
if self.training:
self.pre_nms_thresh = self.pre_nms_thresh_train
self.pre_nms_topk = self.pre_nms_topk_train
self.post_nms_topk = self.post_nms_topk_train
else:
self.pre_nms_thresh = self.pre_nms_thresh_test
self.pre_nms_topk = self.pre_nms_topk_test
self.post_nms_topk = self.post_nms_topk_test
sampled_boxes = []
bundle = {
"l": locations, "o": logits_pred,
"r": reg_pred, "c": ctrness_pred,
"s": self.strides,
}
if len(top_feats) > 0:
bundle["t"] = top_feats
for i, per_bundle in enumerate(zip(*bundle.values())):
# get per-level bundle
per_bundle = dict(zip(bundle.keys(), per_bundle))
# recall that during training, we normalize regression targets with FPN's stride.
# we denormalize them here.
l = per_bundle["l"]
o = per_bundle["o"]
r = per_bundle["r"] * per_bundle["s"]
c = per_bundle["c"]
t = per_bundle["t"] if "t" in bundle else None
sampled_boxes.append(
self.forward_for_single_feature_map(
l, o, r, c, image_sizes, t
)
)
for per_im_sampled_boxes in sampled_boxes[-1]:
per_im_sampled_boxes.fpn_levels = l.new_ones(
len(per_im_sampled_boxes), dtype=torch.long
) * i
boxlists = list(zip(*sampled_boxes))
boxlists = [Instances.cat(boxlist) for boxlist in boxlists]
boxlists = self.select_over_all_levels(boxlists)
pdb.set_trace()
return boxlists
def forward_for_single_feature_map(
self, locations, logits_pred, reg_pred,
ctrness_pred, image_sizes, top_feat=None
):
pdb.set_trace()
N, C, H, W = logits_pred.shape
# put in the same format as locations
logits_pred = logits_pred.view(N, C, H, W).permute(0, 2, 3, 1)
logits_pred = logits_pred.reshape(N, -1, C).sigmoid()
box_regression = reg_pred.view(N, 4, H, W).permute(0, 2, 3, 1)
box_regression = box_regression.reshape(N, -1, 4)
ctrness_pred = ctrness_pred.view(N, 1, H, W).permute(0, 2, 3, 1)
ctrness_pred = ctrness_pred.reshape(N, -1).sigmoid()
if top_feat is not None:
top_feat = top_feat.view(N, -1, H, W).permute(0, 2, 3, 1)
top_feat = top_feat.reshape(N, H * W, -1)
# if self.thresh_with_ctr is True, we multiply the classification
# scores with centerness scores before applying the threshold.
if self.thresh_with_ctr:
logits_pred = logits_pred * ctrness_pred[:, :, None]
candidate_inds = logits_pred > self.pre_nms_thresh
pre_nms_top_n = candidate_inds.view(N, -1).sum(1)
pre_nms_top_n = pre_nms_top_n.clamp(max=self.pre_nms_topk)
if not self.thresh_with_ctr:
logits_pred = logits_pred * ctrness_pred[:, :, None]
results = []
for i in range(N):
per_box_cls = logits_pred[i]
per_candidate_inds = candidate_inds[i]
per_box_cls = per_box_cls[per_candidate_inds]
per_candidate_nonzeros = per_candidate_inds.nonzero()
per_box_loc = per_candidate_nonzeros[:, 0]
per_class = per_candidate_nonzeros[:, 1]
per_box_regression = box_regression[i]
per_box_regression = per_box_regression[per_box_loc]
per_locations = locations[per_box_loc]
if top_feat is not None:
per_top_feat = top_feat[i]
per_top_feat = per_top_feat[per_box_loc]
per_pre_nms_top_n = pre_nms_top_n[i]
if per_candidate_inds.sum().item() > per_pre_nms_top_n.item():
per_box_cls, top_k_indices = \
per_box_cls.topk(per_pre_nms_top_n, sorted=False)
per_class = per_class[top_k_indices]
per_box_regression = per_box_regression[top_k_indices]
per_locations = per_locations[top_k_indices]
if top_feat is not None:
per_top_feat = per_top_feat[top_k_indices]
detections = torch.stack([
per_locations[:, 0] - per_box_regression[:, 0],
per_locations[:, 1] - per_box_regression[:, 1],
per_locations[:, 0] + per_box_regression[:, 2],
per_locations[:, 1] + per_box_regression[:, 3],
], dim=1)
boxlist = Instances(image_sizes[i])
boxlist.pred_boxes = Boxes(detections)
boxlist.scores = torch.sqrt(per_box_cls)
boxlist.pred_classes = per_class
boxlist.locations = per_locations
if top_feat is not None:
boxlist.top_feat = per_top_feat
results.append(boxlist)
pdb.set_trace()
return results
def select_over_all_levels(self, boxlists):
num_images = len(boxlists)
results = []
for i in range(num_images):
# multiclass nms
result = ml_nms(boxlists[i], self.nms_thresh)
number_of_detections = len(result)
# Limit to max_per_image detections **over all classes**
if number_of_detections > self.post_nms_topk > 0:
cls_scores = result.scores
image_thresh, _ = torch.kthvalue(
cls_scores.cpu(),
number_of_detections - self.post_nms_topk + 1
)
keep = cls_scores >= image_thresh.item()
keep = torch.nonzero(keep).squeeze(1)
result = result[keep]
results.append(result)
return results
'''
in blendmask:
(Pdb) top_feats[0].size()
torch.Size([2, 784, 96, 148])
(Pdb) top_feats[1].size()
torch.Size([2, 784, 48, 74])
(Pdb) top_feats[2].size()
torch.Size([2, 784, 24, 37])
(Pdb) top_feats[3].size()
torch.Size([2, 784, 12, 19])
(Pdb) top_feats[4].size()
torch.Size([2, 784, 6, 10])
'''
3. AdelaiDet/adet/layers/iou_loss.py
class IOULoss(nn.Module):
"""
Intersetion Over Union (IoU) loss which supports three
different IoU computations:
* IoU
* Linear IoU
* gIoU
"""
def __init__(self, loc_loss_type='iou'):
super(IOULoss, self).__init__()
self.loc_loss_type = loc_loss_type
def forward(self, pred, target, weight=None): # !!!对于Fcos 这里的weight是 center-ness
"""
Args:
pred: Nx4 predicted bounding boxes
target: Nx4 target bounding boxes
weight: N loss weight for each instance
"""
pred_left = pred[:, 0]
pred_top = pred[:, 1]
pred_right = pred[:, 2]
pred_bottom = pred[:, 3]
target_left = target[:, 0]
target_top = target[:, 1]
target_right = target[:, 2]
target_bottom = target[:, 3]
target_aera = (target_left + target_right) * \
(target_top + target_bottom)
pred_aera = (pred_left + pred_right) * \
(pred_top + pred_bottom)
w_intersect = torch.min(pred_left, target_left) + \
torch.min(pred_right, target_right)
h_intersect = torch.min(pred_bottom, target_bottom) + \
torch.min(pred_top, target_top)
g_w_intersect = torch.max(pred_left, target_left) + \
torch.max(pred_right, target_right)
g_h_intersect = torch.max(pred_bottom, target_bottom) + \
torch.max(pred_top, target_top)
ac_uion = g_w_intersect * g_h_intersect
area_intersect = w_intersect * h_intersect
area_union = target_aera + pred_aera - area_intersect
ious = (area_intersect + 1.0) / (area_union + 1.0)
gious = ious - (ac_uion - area_union) / ac_uion
if self.loc_loss_type == 'iou':
losses = -torch.log(ious)
elif self.loc_loss_type == 'linear_iou':
losses = 1 - ious
elif self.loc_loss_type == 'giou':
losses = 1 - gious
else:
raise NotImplementedError
if weight is not None:
return (losses * weight).sum() # 通过IOU loss 得到的L_reg, 还需要乘上weight(ctrness)
else:
return losses.sum()
4. AdelaiDet/adet/utils/comm.py
import torch
import torch.nn.functional as F
import torch.distributed as dist
from detectron2.utils.comm import get_world_size
import pdb
def reduce_sum(tensor):
world_size = get_world_size()
if world_size < 2:
return tensor
tensor = tensor.clone()
dist.all_reduce(tensor, op=dist.ReduceOp.SUM)
return tensor
def aligned_bilinear(tensor, factor):
assert tensor.dim() == 4
assert factor >= 1
assert int(factor) == factor
if factor == 1:
return tensor
h, w = tensor.size()[2:]
tensor = F.pad(tensor, pad=(0, 1, 0, 1), mode="replicate")
oh = factor * h + 1
ow = factor * w + 1
tensor = F.interpolate(
tensor, size=(oh, ow),
mode='bilinear',
align_corners=True
)
tensor = F.pad(
tensor, pad=(factor // 2, 0, factor // 2, 0),
mode="replicate"
)
return tensor[:, :, :oh - 1, :ow - 1]
# FCOS self.fpn_strides [8, 16, 32, 64, 128]
# 其实就是把FPN feature_map[i]上的点映射到原图input image
def compute_locations(h, w, stride, device):
shifts_x = torch.arange(
0, w * stride, step=stride,
dtype=torch.float32, device=device
)
# 76
shifts_y = torch.arange(
0, h * stride, step=stride,
dtype=torch.float32, device=device
)
# 52
shift_y, shift_x = torch.meshgrid(shifts_y, shifts_x) # level = 1 : [52 * 76]
shift_x = shift_x.reshape(-1) # level = 1 : [52, 76] --> 3952
shift_y = shift_y.reshape(-1) # level = 1 : [52, 76] --> 3952
'''
paper :
For each location (x, y) on the feature map Fi, we can
map it back onto the input image as (s/2 + xs, s/2 + ys)
)
'''
locations = torch.stack((shift_x, shift_y), dim=1) + stride // 2 # [3952, 2]
pdb.set_trace()
return locations
'''
(Pdb) locations[0].size()
torch.Size([16800, 2]) 16800 = 100 * 168
(Pdb) locations[1].size()
torch.Size([4200, 2]) 4200 = 50 * 84
(Pdb) locations[2].size()
torch.Size([1050, 2])
(Pdb) locations[3].size()
torch.Size([273, 2])
(Pdb) locations[4].size()
torch.Size([77, 2])
'''