冒泡排序算法(Bubble Sort)
概述与算法基本思想
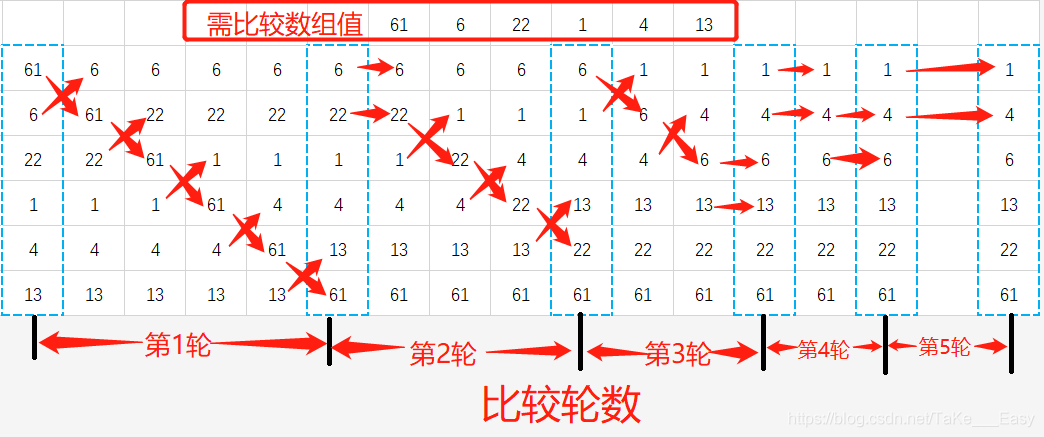
排序过程示意图
命令脚本
方式一
[root@localhost ~]# ./28.sh
需排序数组的值为:61 6 22 1 4 13
排序后的新数组值为:1 4 6 13 22 61
[root@localhost ~]# vim 28.sh
#!/bin/bash
sz=(61 6 22 1 4 13)
echo "需排序数组的值为:${sz[@]}"
leng=${
#sz[@]}
【获取数组长度】
for ((w=1;w<$leng;w++))
【定义比较轮数,为数组长度减1,因为这里是小于,所以不用减1,并每次执行+1的操作】
do
for ((e=0;e<$leng-$w;e++))
【因为这里的变量e是用来定义第一个比较元素的索引值,所以从0开始,又因为最后一次比较是索引4和索引5进行比较,所以这里变量e的值小于数组长度
减变量w(减变量w而不直接减1是因为待比较元素的位置需要随着轮数的增加而减少)】
do
one=${
sz[$e]}
【定义第1个比较元素的值】
two=${
sz[$e+1]}
【定义第2个比较元素的值】
if [ $one -gt $two ];then
【如果第1个元素的值大于第2个元素的值,则只需位置交换操作】
sz1=$one
【把第一个元素的值赋给临时变量sz1】
sz[$e]=$two
【把第二个元素的值赋给第一个元素】
sz[$e+1]=$sz1
【再把第一个元素的值(sz1的值)赋给第二个元素】
fi
done
done
echo "排序后的新数组值为:${sz[*]}"
方式二(手动定义需要排序的数组值)
[root@localhost ~]# ./28-1.sh
输入你需要排序的数组:33 2 28 5 44 32 18 29
需排序数组的值为:33 2 28 5 44 32 18 29
排序后的新数组值为:2 5 18 28 29 32 33 44
[root@localhost ~]# vim 28-1.sh
#!/bin/bash
read -p "输入你需要排序的数组:" num 【将需要排序的数组值赋给变量num】
sz=($num) 【与方式一的区别在于这里是通过变量num获取到值,而不是脚本内定义好值】
echo "需排序数组的值为:${sz[@]}"
leng=${
#sz[@]}
for ((w=1;w<$leng;w++))
do
for ((e=0;e<$leng-$w;e++))
do
one=${
sz[$e]}
two=${
sz[$e+1]}
if [ $one -gt $two ];then
sz1=$one
sz[$e]=$two
sz[$e+1]=$sz1
fi
done
done
echo "排序后的新数组值为:${sz[*]}"
方式三(将算法封装成函数,并通过函数传参待排序的数组进算法内)
[root@localhost ~]# ./28-2.sh 88 91 102 32 45 27 1 13
需排序数组的值为:88 91 102 32 45 27 1 13
排序后的新数组值为:1 13 27 32 45 88 91 102
[root@localhost ~]# vim 28-2.sh
sz=($@)
echo "需排序数组的值为:${sz[@]}"
leng=${
#sz[@]}
for ((w=1;w<$leng;w++))
do
for ((e=0;e<$leng-$w;e++))
do
one=${
sz[$e]}
two=${
sz[$e+1]}
if [ $one -gt $two ];then
sz1=$one
sz[$e]=$two
sz[$e+1]=$sz1
fi
done
done
echo "排序后的新数组值为:${sz[*]}"
}
#################main################# 【仅为注释从这以下为主代码】
list=$@ 【将命令行获取到的数组值赋给变量list】
paixu $list 【将变量list获得的值传参到函数paixu内】
直接选择排序算法(Straight Select Sorting)
概述与算法基本思想
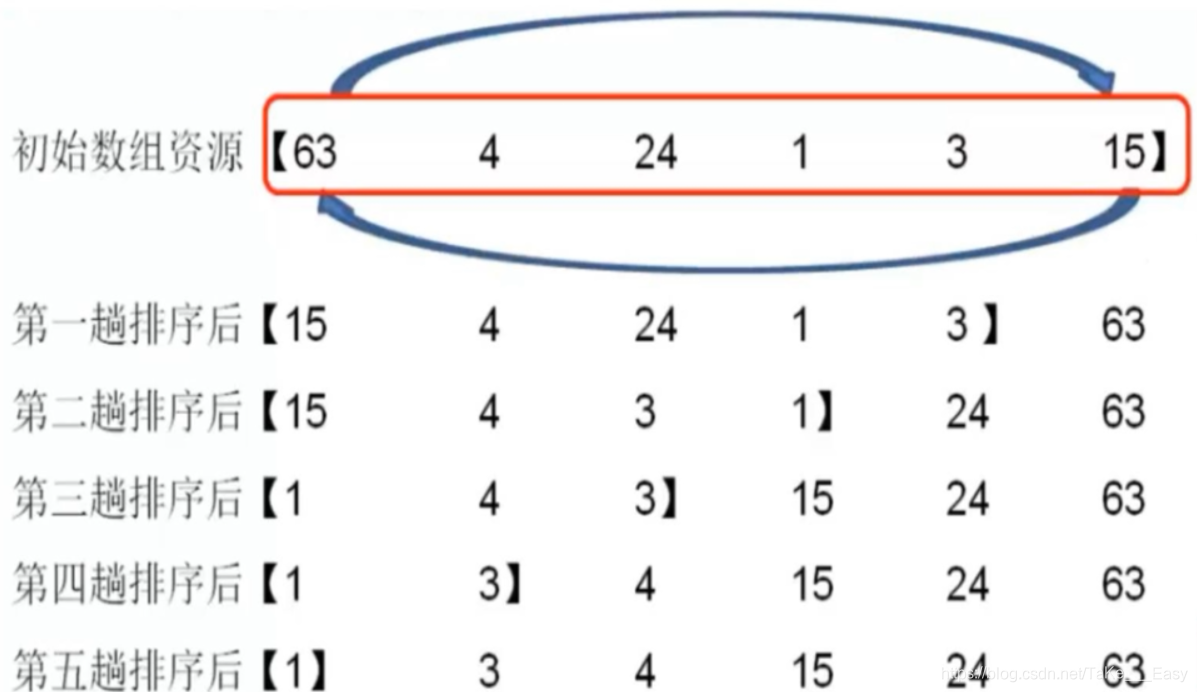
排序过程示意图
命令脚本
[root@localhost ~]# ./29.sh
待排序的数组值为:63 4 24 1 3 15
排序后的数组值为: 1 3 4 15 24 63
[root@localhost ~]# vim 29.sh
#!/bin/bash
sz=(63 4 24 1 3 15)
echo "待排序的数组值为:${sz[@]}"
leng=${
#sz[@]} 【定义排序的轮数】
for ((w=1;w<$leng;w++))
do
jx=0 【假设所以为0的元素是最大,并将值赋给jx】
for ((e=1;e<=$leng-$w;e++)) 【定义和第一个元素比较的索引,用来确定最大的元素索引】
do
max=${
sz[$jx]} 【定义最大的元素的值】
cs=${
sz[$e]} 【定义从索引1开始比较的元素的值】
if [ $cs -gt $max ];then 【判断如果从索引1开始比较的元素值大于当前最大元素的值时,则记录最大值的索引到变量jx】
jx=$e
fi
done
qz=$[$leng-$w] 【定义每一轮比较的最后一个元素的索引】
qz1=${
sz[$qz]} 【把当前轮次的最后一个元素的值赋给临时变量qz1】
sz[$qz]=${
sz[$jx]} 【把最大的值赋给当前轮次的最后一个元素】
sz[$jx]=$qz1 【把qz1里的原来最后一个元素的值赋给原来最大值所在索引的元素】
done
echo "排序后的数组值为: ${sz[*]}"
反转排序算法(Reverse Sort)
概述与算法基本思想
命令脚本
[root@localhost ~]# ./30.sh
待排序的数组为:3 4 24 31 43 65 89
反转排序后的数组顺序为:89 65 43 31 24 4 3
[root@localhost ~]# vim 30.sh
#!/bin/bash
sz=(3 4 24 31 43 65 89)
echo "待排序的数组为:${sz[@]}"
leng=${
#sz[@]} 【输出数组sz的长度值并赋给变量leng】
for ((w=0; w<$leng/2; w++)) 【索引从0开始,/2是折半对调,所以是长度/2,且索引每次增加1次】
do
one=${
sz[$w]} 【将第一个索引对应的元素赋值给变量one】
two=${
sz[$leng-1-$w]} 【将最后一个索引对应的元素赋给变量two】
sz1=$one
sz[$w]=$two 【将最后一个索引对应的元素赋给第一个索引对应的元素】
sz[$leng-1-$w]=$sz1 【将第一个索引对应的元素赋给最后一个索引对应的元素】
done
echo "反转排序后的数组顺序为:${sz[@]}"