1. 摘要
本文是一个端到端的一阶段anchor-free的目标检测(可以扩充到3D检测,人体姿态估计等)方法。使用的是预测物体的中心点来代替Anchor。利用关键点估计来寻找中心点,进而再回归目标的其他属性,大小、3D位置、方向、姿势等。(本文包括目标检测、3D检测、姿态估计三部分,本文只讨论目标检测部分)
总体流程大概是,目标检测是一个标准的关键点估计问题。我们只需将输入图像输入到生成热图的完全卷积网络。热图中的峰值对应于物体中心。每个峰值的图像特征预测对象边界框的高度和权重。推理是一个单一的网络前向传递,没有对后处理的非最大抑制。
本文的方法CenterNet的简单性允许它以非常高的速度运行。
2. 相关工作
本文的方法与基于anchor的单阶段方法密切相关。一个中心点可以看作为一个单一的形状未知的anchor(见图3)。然而,有一些重要的区别。
- 首先,本文的中心网只根据位置而不是框重叠来分配“anchor”,所以没有用于前景和背景分类的手动阈值。
- 其次,每个目标只有一个正“anchor”,因此不需要非最大值抑制。只需提取关键点热图中的局部峰值。
- 第三,与传统的目标检测器相比,CenterNet使用更大的输出分辨率(本文输出步长为4,传统的检测器输出步长为16)。这样就不需要多个anchor。

2.本文方法
2.1 Preliminary
设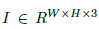 为宽度W和高度H的输入图像。目的是要生成一个关键点热图
为宽度W和高度H的输入图像。目的是要生成一个关键点热图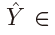
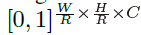
,其中R是输出跨距,C是关键点类型的数目。关键点类型包括物体检测中的C=80个物体类别。本文默认输出跨距R=4。输出跨距将输出预测降低一个因子R。
预测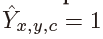 对应于检测到的关键点,而
对应于检测到的关键点,而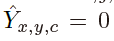 是背景。本文使用几种不同的卷积网络来预测图像 I 中的Y:A stacked hourglass network、ResNet 和 DLA。
是背景。本文使用几种不同的卷积网络来预测图像 I 中的Y:A stacked hourglass network、ResNet 和 DLA。
对于C类的每个真实值关键点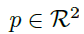 计算了一个低分辨率等价
计算了一个低分辨率等价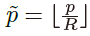 。然后,使用高斯核
。然后,使用高斯核 将所有真实值关键点散放到热图
将所有真实值关键点散放到热图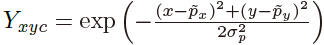 上,其中
上,其中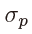 是目标大小自适应标准偏差。如果同一类的两个高斯子重叠,则取元素的最大值。
是目标大小自适应标准偏差。如果同一类的两个高斯子重叠,则取元素的最大值。
损失函数:
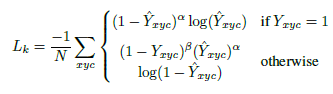
其中α和β 是focal loss的超参数,N是图像I中的关键点数量。选择N进行归一化,将所有正focal loss实例归一化为1。
为了恢复由输出步长引起的离散化误差,本文还为每个中心点预测了局部偏移量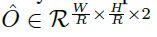 。
。
所有c类共享相同的偏移量预测。用L1损失训练偏移量
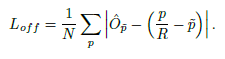
监督仅在关键点位置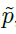 起作用,其他所有位置均被忽略。
起作用,其他所有位置均被忽略。
以上这些,与CornerNet基本类似。
2.2 将物体视为一个点(objects as points)
设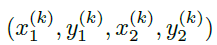 是类别为C_k的目标k的边界框。它的中心点位于P_k =
是类别为C_k的目标k的边界框。它的中心点位于P_k = 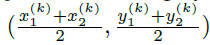 ,本文用关键点估计预测中心点,此外,还回归每个目标k的大小
,本文用关键点估计预测中心点,此外,还回归每个目标k的大小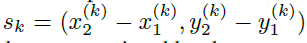 。为减少计算负担,为所有类别使用同一size。在中心点位置使用L1 loss:
。为减少计算负担,为所有类别使用同一size。在中心点位置使用L1 loss:
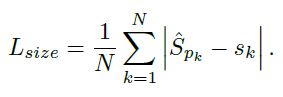
总体的loss函数为:
本文不将scale进行归一化,直接使用原始像素坐标。为了调节该loss的影响,将其乘了个系数,整个训练的目标loss函数为
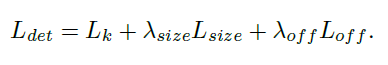
网络预测关键点Y,偏移量O和大小S,每个位置有C+4个输出(即类别数目C个的热图,偏移量的x,y,尺寸的w,h)。
点到框
- 独立提取每个类别的热图中的峰值(做法是将热力图上的所有响应点与其连接的8个临近点进行比较,如果该点响应值大于或等于其八个临近点值则保留)
- 保留前100个峰值
- 使用关键点预测值作为检测置信度度量
设P_c是检测到的 c 类别的 n 个中心点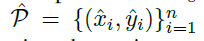 的集合,每个关键点由整形(x_i,y_i)给出,产生如下box:
的集合,每个关键点由整形(x_i,y_i)给出,产生如下box:

其中,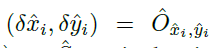 是偏移预测,
是偏移预测,
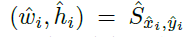 是size预测。
是size预测。
2.3 网络结构细节

3. 实验

- 沙漏网络在相对较好的速度下能达到最佳性能。
- DLA-34得到了最好的速度/准确率的折中。
- 两个不同物体可能共享同一个中心点,这样的话网络只能检测到一个。但这种情况是很少的(COCO中不到0.1%的比例),这部分误差可以忽略。
- 用NMS提升甚微,所以就不用NMS了。
- 在这里,L1比Smooth L1效果好。