COCO官网:http://cocodataset.org
COCO论文1:Microsoft COCO: Common Objects in Context
COCO论文2:What makes for effective detection proposals?
1.简介
- MS COCO的全称是Microsoft Common Objects in Context。
- MS COCO 数据集是微软构建的一个数据集,其包含 detection, segmentation, keypoints等任务。
- 与PASCAL COCO数据集相比,COCO中的图片包含了自然图片以及生活中常见的目标图片,背景比较复杂,目标数量比较多,目标尺寸更小,因此COCO数据集上的任务更难,对于检测任务来说,现在衡量一个模型好坏的标准更加倾向于使用COCO数据集上的检测结果。
2. 数据集信息
- MSCOCO总共包含80个类别,每个类别的图片数量如下:
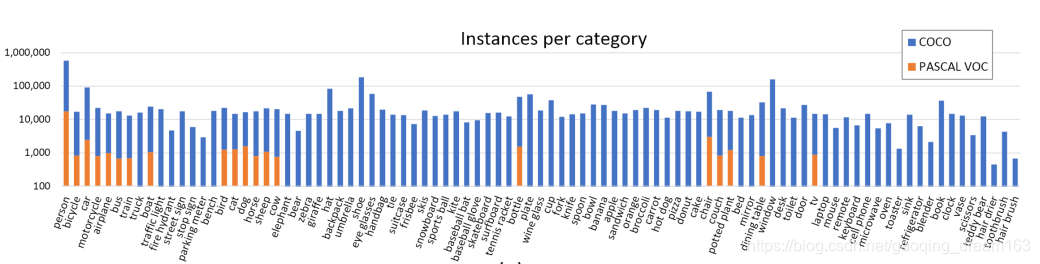
- COCO数据集平均每张图片包含 3.5个类别和 7.7 个实例目标,仅有不到20%的图片只包含一个类别,仅有10%的图片包含一个实例目标。
- COCO2014数据集包含82,783 training, 40,504 validation, and 40,775 testing (大约1/2 train, 1/4 val, and /4 test)。大约270k的分割people,886k的分割物体实例。
- COCO2015数据集包含165,482 train, 81,208 val, and 81,434 test。

3.评估标准
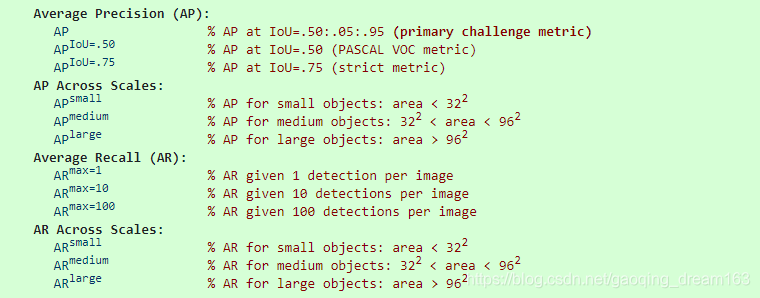
- IoU:Intersection over Union。边界框的 IoU 计算是关于 boxes的 ,而 segmentation mask 的 IoU 计算是关于 masks 的。
- AP :是对所有类别(80个)的求平均值. 这在传统上被称为平均准确度(mAP, mean average precision).
- [email protected]: 跟PASCAL VOC中的mAP是相同的含义。
- [email protected] :跟PASCAL VOC中的mAP也相同,只是IOU阈值提高到了0.75,显然这个层面更严格,精度也会更低。
- [email protected]:0.05:0.95:指 IOU从0.5到0.95 每变化 0.05 就测试一次 AP,然后求这10次测量结果的平均值作为最终的 AP。
- AP@small/medium/large:针对 三种不同大小(small,medium,large) 的图片提出了测量标准,COCO中包含大约 41% 的小目标 (area<32×32), 34% 的中等目标 (32×32<area<96×96), 和 24% 的大目标 (area>96×96). 小目标的AP是很难提升的。
- AR: 是指每张图片中,在给定固定数量的检测结果中的最大召回(maximum recall),在所有 IoUs 和全部类别上求平均值. AR 与 proposal evaluation 中所使用的相同,但这里 AR是按类别计算的。
- 边界框(bounding boxes)的检测和segmentation mask 的所有评测指标是一致的。
4. 代码
- cocoAPI代码:https://github.com/cocodataset/cocoapi
- coco评价指标代码:PythonAPI/pycocotools/cocoeval.py