

由于我们不能通过随机试验解决遗漏变量偏差和内生性问题,因此以下这些方式成为次优中的最优选择:二阶段最小二乘法,结构方程模型,广义矩估计,控制方程方法。这四种方法都能够得到相同的估计结果,因为都是在通过寻找工具变量来控制诸如内生性等问题,当然这里面最具一般性的方法就是广义矩估计,因为其他方法都可以通过广义矩估计得到。
注:点击图片,看清晰文字(PDF下载看文末)。




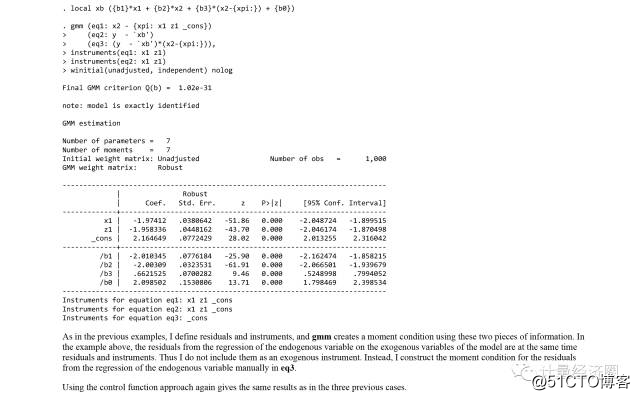
In the first example, I used an estimator that exists in Stata. In the last two examples, I used estimation tools that allow us to obtain estimators for a large class of models.
Concluding remarks
Estimating the parameters of a model in the presence of endogeneity or related problems http://blog.stata.com/tag/endogeneity/ is daunting. Above I illustrated how to estimate the parameters of such models using commands in Stata that were created for such a purpose and also illustrated how you can use gmm and sem to estimate these models.
需要PDF版本的,请看文末最后一句话。