转载博客
一.Stream流
stream流,是在java8中,由lambda表达式所带来的一种新的函数是编程模式,可以用来解决一些已有的集合类型的弊端
1.stream流与传统集合的便利方式的区别
传统遍历方式
public static void main(String[] args) {
//遍历输出名字中含有七的并且名字长度为3的人
List<String> list = List.of("乔七七","韩七岁","零零七","鲁班七号","上官婉儿");
List<String> newList = new ArrayList<>();
//遍历list挑选出名字中带有七的
for (String s : list) {
if (s.contains("七")){
newList.add(s);
}
}
//遍历出名字长度为3的
for (String s : newList) {
if (s.length()==3){
System.out.println(s);
}
}
}stream方式(串行)
parallelStream方式(并行)
public static void main(String[] args) {
List<String> list = List.of("乔七七","韩七岁","零零七","鲁班七号","上官婉儿");
//筛选带七的且名字长度为3的人
list.stream().filter(s -> s.contains("七"))
.filter(s -> s.length()==3)
.forEach(System.out::println);
}2.stream流思想原理
当对集合中的元素需要进行一系列的操作,我们可已按照需要的规则来进行处理这些集合中的数据。
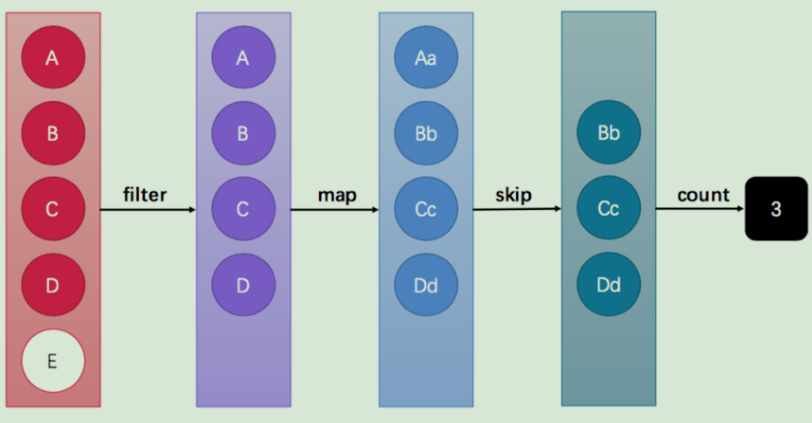
在这个图中显示了过滤,映射,跳过,计数等多个环节,将这些步骤都放在一起进行一个流水线一样的操作,整个过程在一个管道中完成,将数据又由原始状态转变为需要的状态。
filter、map、skip都是在对函数模型进行操作,集合元素并没有真正被处理。只有当终结方法count执行的时候,整个数据才会按照指定要求执行操作。
3.stream流中常用的方法
stream流中方法可分为两类,一种为终结方法,另外一种为非终结方法。
-
终结方法:返回值类型不再是
Stream接口自身类型的方法。 -
非终结方法:返回值仍然是stream接口的方法,支持链式调用。
| 方法名称 | 作用 | 方法种类 | 是否支持链式调用 |
|---|---|---|---|
| count | 统计个数 | 终结 | 否 |
forEach |
遍历逐一处理 | 终结 | 否 |
| filter | 过滤 | 函数拼接 | 支持 |
| limit | 取前几个 | 函数拼接 | 支持 |
| skip | 跳过几个 | 函数拼接 | 支持 |
| map | 映射 | 函数拼接 | 支持 |
concat |
组合 | 函数拼接 | 支持 |
| sorted |
排序 | 函数拼接 | 支持 |
过滤:filter
filter方法将一个流转换为另外一个子集流。
Stream<T> filter(Predicate<? super T> predicate);该接口接收一个Predicate函数式接口参数(可以是一个Lambda或方法引用)作为筛选条件。
public static void main(String[] args) {
Stream<String> stream = Stream.of("鲁班七号", "老夫子", "公孙离", "南宫", "甄姬");
stream.filter(s -> s.length() == 2).forEach(System.out::println);
}截取:limit
limit方法可以对流进行截取,只取用前n个。
Stream<T> limit(long maxSize);参数是一个long型,如果集合当前长度大于参数则进行截取;否则不进行操作
public class StreamLimit {
public static void main(String[] args) {
Stream<String> stream = Stream.of("鲁班七号", "老夫子", "公孙离", "南宫", "甄姬");
//limit截取前几个元素
stream.limit(3).forEach(System.out::println);
}
}跳过:skip
skip方法可以跳过前几个元素,从而获取之后的元素作为一个新的流。
Stream<T> skip(long n);如果流的当前长度大于n,则跳过前n个;否则将会得到一个长度为0的空流。
public class StreamSkip {
public static void main(String[] args) {
//skip跳过几个元素
Stream<String> stream = Stream.of("鲁班七号", "老夫子", "公孙离", "南宫", "甄姬");
stream.skip(2).forEach(System.out::println);
}
}映射:map
map方法可以将需要的元素映射到另外一个集合中。
<R> Stream<R> map(Function<? super T, ? extends R> mapper);该接口需要一个Function函数式接口参数,可以将当前流中的T类型数据转换为另一种R类型的流。
public class StreamMap {
public static void main(String[] args){
Stream<String> oldStream = Stream.of("1.2", "1.3", "3.5", "12.5", "65.8");
Stream<Double> newStream = oldStream.map(Double::parseDouble);
newStream.forEach(System.out::println);
}
}联合:concat
如果有两个流,希望合并成为一个流,那么可以使用Stream接口的静态方法concat
static <T> Stream<T> concat(Stream<? extends T> a, Stream<? extends T> b)基本使用:
public static void main(String[] args) {
//concat,合并流
Stream<String> wurenxiaofendui = Stream.of("孙悟空", "猪八戒", "沙和尚", "小白龙", "唐僧");
Stream<String> yaojingwurenzu = Stream.of("紫霞","嫦娥","小侍女","四公主","女儿国国王");
Stream<String> stringStream = Stream.concat(wurenxiaofendui, yaojingwurenzu);
stringStream.forEach(System.out::println);
}计数:count
count方法用来统计个数
long count();使用:
public class ListDemo {
public static void main(String[] args) {
List<String> list = List.of("乔七七","韩七岁","零零七","鲁班七号","上官婉儿");
//筛选带七的且名字长度为3的人,统计个数
long count = list.stream().
filter(s -> s.contains("七")).
filter(s -> s.length() == 3).count();
System.out.println(count);
}
}遍历处理:forEach
forEach,但是与for循环中的“for-each”昵称不同,该方法并不保证元素的逐一消费动作在流中是被有序执行的。
void forEach(Consumer<? super T> action);该方法接收一个Consumer接口函数,会将每一个流元素交给该函数进行处理。
import java.util.stream.Stream;
public class StreamForEach {
public static void main(String[] args) {
Stream<String> stream = Stream.of("孙悟空", "猪八戒", "沙和尚", "小白龙", "唐僧");
stream.forEach(System.out::println);
}
}排序:sorted
按自然升序对集合进行排序
list.stream().sorted() .stream().sorted();自然序降序使用Comparator提供reverseOrder()方法
list.stream().sorted(Comparator.reverseOrder()) .stream().sorted(Comparator.reverseOrder());使用Comparator来对列表进行自定义升序。
list.stream().sorted(Comparator.comparing(Student::getAge));二.collect方法
collect方法也是使用的比较多的方法,它可以将stream流整合成我们需要的集合格式然后返回
1.转换成List/Set
Collectors.toList():转换成List集合。/ Collectors.toSet():转换成set集合。
System.out.println(Stream.of("a", "b", "c","a").collect(Collectors.toSet()));2.转换成特定的set集合
Collectors.toCollection(TreeSet::new)
TreeSet<String> treeSet = Stream.of("a", "c", "b", "a").collect(Collectors.toCollection(TreeSet::new));
System.out.println(treeSet);3.转换成Map
Collectors.toMap(keyMapper, valueMapper, mergeFunction)
Map<String, String> collect = Stream.of("a", "b", "c", "a").collect(Collectors.toMap(x -> x, x -> x + x,(oldVal, newVal) -> newVal)));
collect.forEach((k,v) -> System.out.println(k + ":" + v));当toMap中没有用合并函数时,出现key重复时,会抛出异常 : Exception in thread "main" java.lang.IllegalStateException: Duplicate key aa
当使用合并函数时,可通过Labmda表达式,对重复值进行处理
4.Collectors.minBy(Integer::compare):求最小值,相对应的当然也有maxBy方法。
5.Collectors.averagingInt(x->x):求平均值,同时也有averagingDouble、averagingLong方法。
6.Collectors.summingInt(x -> x)):求和。
7.Collectors.summarizingDouble(x -> x):可以获取最大值、最小值、平均值、总和值、总数。
DoubleSummaryStatistics summaryStatistics = Stream.of(1, 3, 4).collect(Collectors.summarizingDouble(x -> x));
System.out.println(summaryStatistics .getAverage());8. Collectors.groupingBy(x -> x):有三种方法,查看源码可以知道前两个方法最终调用第三个方法,
第二个参数默认HashMap::new 第三个参数默认Collectors.toList()
Map<Integer, List<Integer>> map = Stream.of(1, 3, 3, 2).collect(Collectors.groupingBy(Function.identity()));
System.out.println(map);
Map<Integer, Integer> map1 = Stream.of(1, 3, 3, 2).collect(Collectors.groupingBy(Function.identity(), Collectors.summingInt(x -> x)));
System.out.println(map1);
HashMap<Integer, List<Integer>> hashMap = Stream.of(1, 3, 3, 2).collect(Collectors.groupingBy(Function.identity(), HashMap::new, Collectors.mapping(x -> x + 1, Collectors.toList())));
System.out.println(hashMap);
//根据班级分类学生列表
Student stuI = new Student();
stuI.setClass("一年级");
stuI.setName("小明");
Student stuII = new Student();
stuII.setClass("二年级");
stuII.setName("小红");
Map<String, List<Student>> collect = Stream.of(stuI,stuII ).collect(Collectors.groupingBy(com.activiti.domain.Student::getClass));
补充: identity()是Function类的静态方法,和 x->x 是一个意思,
当仅仅需要自己返回自己时,使用identity()能更清楚的表达作者的意思.
写的复杂一点,绕一点,对理解很有好处.下边是运行结果: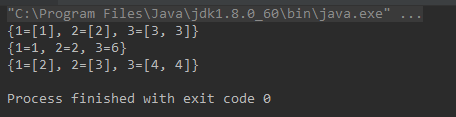
9.Collectors.partitioningBy(x -> x > 2),把数据分成两部分,key为ture/false。第一个方法也是调用第二个方法,第二个参数默认为Collectors.toList()
Map<Boolean, List<Integer>> map = Stream.of(1, 3, 3, 2).collect(Collectors.partitioningBy(x -> x > 2));
Map<Boolean, Long> longMap = Stream.of(1, 3, 3, 2).collect(Collectors.partitioningBy(x -> x > 1, Collectors.counting()));10.Collectors.joining(","):拼接字符串。
System.out.println(Stream.of("1", "3", "3", "2").collect(Collectors.joining(",")));11.Collectors.collectingAndThen(Collectors.toList(), x -> x.size()):先执行collect操作后再执行第二个参数的表达式。这里是先塞到集合,再得出集合长度。
Integer integer = Stream.of("1", "2", "3").collect(Collectors.collectingAndThen(Collectors.toList(), x -> x.size()));12.Collectors.mapping(...):跟Stream的map操作类似,只是参数有点区别
System.out.println(Stream.of(1, 3, 5).collect(Collectors.mapping(x -> x + 1, Collectors.toList())));