LabelEncoder 和 OneHotEncoder 是什么
- 在数据处理过程中,我们有时需要对不连续的数字或者文本进行数字化处理。
- 在使用 Python 进行数据处理时,用 encoder 来转化 dummy variable(虚拟数据)非常简便,encoder 可以将数据集中的文本转化成0或1的数值。
- LabelEncoder 和 OneHotEncoder 是 scikit-learn 包中的两个功能,可以实现上述的转化过程。
- sklearn.preprocessing.LabelEncoder
- sklearn.preprocessing.OneHotEncoder
复制代码
数据集中的类别数据
在使用回归模型和机器学习模型时,所有的考察数据都是数值更容易得到好的结果。
因为回归和机器学习都是基于数学函数方法的,所以当我们要分析的数据集中出现了类别数据(categorical data),此时的数据是不理想的,因为我们不能用数学的方法处理它们。
例如,在处理男和女两个性别数据时,我们用0和1将其代替,再进行分析。
由于这种情况的出现,我们需要可以将文字数字化的现成方法。
复制代码
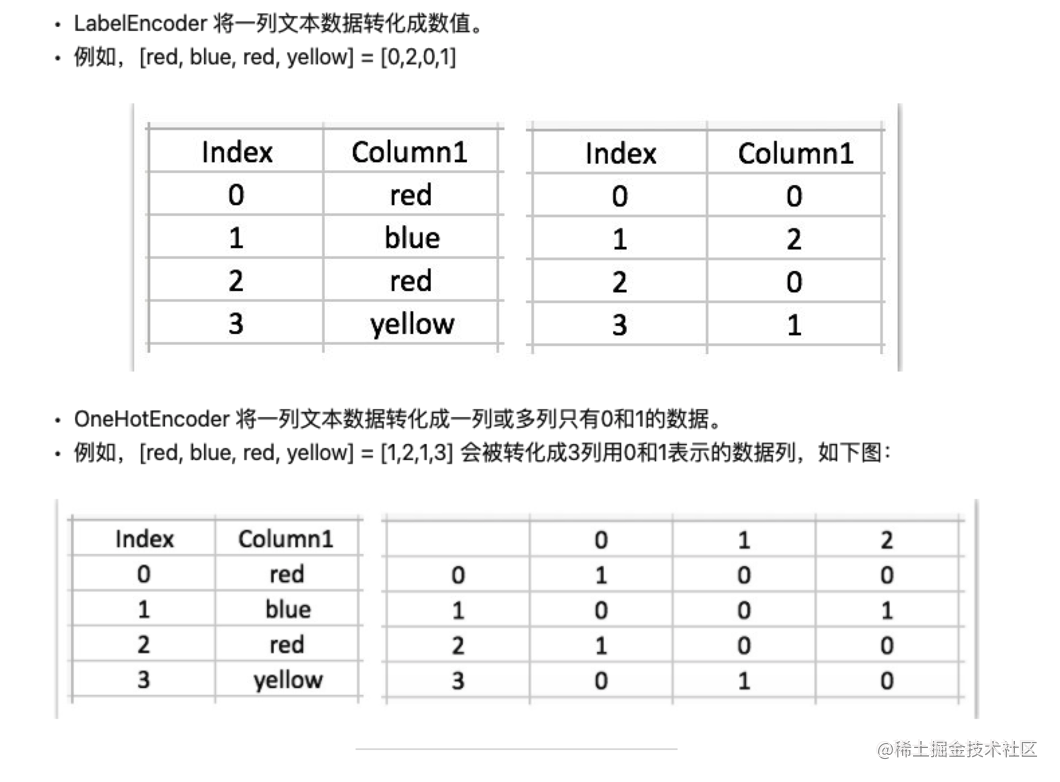
LabelEncoder 和 OneHotEncoder 的区别
具体代码
import pandas as pd
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
from sklearn.cross_validation import train_test_split
data_df = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/'
'breast-cancer-wisconsin/wdbc.data', header=None)
x, y = data_df.values[:, :-1], data_df.values[:, -1]
encoder_x = LabelEncoder()
y = encoder_x.fit_transform( y )
复制代码