一、DATEDIFF(date1,date2)
DATEDIFF() 函数返回两个日期之间的天数。
例1:
SELECT DATEDIFF('2008-12-30','2008-12-29') AS DiffDate结果:1
例2:
SELECT DATEDIFF('2008-12-29','2008-12-30') AS DiffDate结果:-1
例3:编写一个 SQL 查询,来查找与之前(昨天的)日期相比温度更高的所有日期的 id 。
+---------------+---------+
| Column Name | Type |
+---------------+---------+
| id | int |
| recordDate | date |
| temperature | int |
+---------------+---------+
id 是这个表的主键
该表包含特定日期的温度信息
select a.id as id
from weather a join weather w
on DATEDIFF(a.recordDate, w.recordDate) = 1
where a.temperature >w.temperature SELECT w2.Id
FROM Weather w1, Weather w2
WHERE DATEDIFF(w2.RecordDate, w1.RecordDate) = 1
AND w1.Temperature < w2.Temperature二、编写一个 SQL 查询来重新格式化表,使得新的表中有一个部门 id 列和一些对应 每个月 的收入(revenue)列。
+---------------+---------+
| Column Name | Type |
+---------------+---------+
| id | int |
| revenue | int |
| month | varchar |
+---------------+---------+
(id, month) 是表的联合主键。
这个表格有关于每个部门每月收入的信息。
月份(month)可以取下列值 ["Jan","Feb","Mar","Apr","May","Jun","Jul","Aug","Sep","Oct","Nov","Dec"]。
select id,
sum(case month when 'Jan' then revenue end) as Jan_Revenue,
sum(case month when 'Feb' then revenue end) as Feb_Revenue,
sum(case month when 'Mar' then revenue end) as Mar_Revenue,
sum(case month when 'Apr' then revenue end) as Apr_Revenue,
sum(case month when 'May' then revenue end) as May_Revenue,
sum(case month when 'Jun' then revenue end) as Jun_Revenue,
sum(case month when 'Jul' then revenue end) as Jul_Revenue,
sum(case month when 'Aug' then revenue end) as Aug_Revenue,
sum(case month when 'Sep' then revenue end) as Sep_Revenue,
sum(case month when 'Oct' then revenue end) as Oct_Revenue,
sum(case month when 'Nov' then revenue end) as Nov_Revenue,
sum(case month when 'Dec' then revenue end) as Dec_Revenue
from Department
group by id;Department 表:
+------+---------+-------+
| id | revenue | month |
+------+---------+-------+
| 1 | 8000 | Jan |
| 2 | 9000 | Jan |
| 3 | 10000 | Feb |
| 1 | 7000 | Feb |
| 1 | 6000 | Mar |
+------+---------+-------+
查询得到的结果表:
+------+-------------+-------------+-------------+-----+-------------+
| id | Jan_Revenue | Feb_Revenue | Mar_Revenue | ... | Dec_Revenue |
+------+-------------+-------------+-------------+-----+-------------+
| 1 | 8000 | 7000 | 6000 | ... | null |
| 2 | 9000 | null | null | ... | null |
| 3 | null | 10000 | null | ... | null |
+------+-------------+-------------+-------------+-----+-------------+
三、使男女性别交换
+-------------+----------+
| Column Name | Type |
+-------------+----------+
| id | int |
| name | varchar |
| sex | ENUM |
| salary | int |
+-------------+----------+
id 是这个表的主键。
sex 这一列的值是 ENUM 类型,只能从 ('m', 'f') 中取。
本表包含公司雇员的信息。
请你编写一个 SQL 查询来交换所有的 'f' 和 'm' (即,将所有 'f' 变为 'm' ,反之亦然),仅使用 单个 update 语句 ,且不产生中间临时表。
注意,你必须仅使用一条 update 语句,且 不能 使用 select 语句。
update Salary set sex=case sex when "f" then "m" else "f" end
update Salary set sex=if(sex='m','f','m')
update salary set sex = char(ascii('m') + ascii('f') - ascii(sex));四、实现排名(有间隔和无间隔)
编写一个 SQL 查询来实现分数排名。
如果两个分数相同,则两个分数排名(Rank)相同。请注意,平分后的下一个名次应该是下一个连续的整数值。换句话说,名次之间不应该有“间隔”。
+----+-------+
| Id | Score |
+----+-------+
| 1 | 3.50 |
| 2 | 3.65 |
| 3 | 4.00 |
| 4 | 3.85 |
| 5 | 4.00 |
| 6 | 3.65 |
+----+-------+
select a.score,
(select count(DISTINCT s.score)
from Scores s where s.score >= a.score
) as 'Rank'
from Scores a
order by a.score desc名次之间有“间隔”
select a.id,a.score,count(b.score)+1 as `Rank`
from Scores a left join Scores b
on a.score<b.score
group by a.Id,a.score order by `Rank` asc脑壳疼/(ㄒoㄒ)/~~
扩展:
题目:按各科成绩进行排序,并显示排名
SELECT a.courseid,a.studentid,a.score,COUNT(b.score)+1 AS `rank`
FROM student_score a
LEFT JOIN student_score b
ON a.score < b.score AND a.courseid = b.courseid
GROUP BY a.courseid, a.studentid,a.score
ORDER BY a.courseid,`rank` ASC;
可以在博客园看这个博主写的更多sql
【sql:练习题16】查询学生的总成绩,并进行排名 - 初学者,方圆几里 - 博客园
五、rank() over,dense_rank() over,row_number() over的区别
1、rank() over(业务逻辑)
作用:查出指定条件后的进行排名,条件相同排名相同,排名间断不连续。
说明:例如学生排名,使用这个函数,成绩相同的两名是并列,下一位同学空出所占的名次。即:1 1 3 4 5 5 7
SELECT id, name, score, rank() over(ORDER BY score DESC) AS 'rank' FROM student
select name,subject,score,rank() over(partition by subject order by score desc) `rank`
from student_score; 
注意:使用rank() over的时候,空值是最大的,如果排序字段为null,可能造成null字段排在最前面,影响排序结果。可以这样:rank() over(partition by course order by score desc nulls last)来规避这个问题。
select name,subject,score
,rank() over(partition by subject order by score desc nulls last) `rank`
from student_score;
2、partition by 和 group by 的区别
因为over是开窗函数,mysql不支持开窗函数,其他如oracle,sql server,db2...等新版本都支持
group by
SELECT EmpDepartment,SUM(EmpSalary) sum_sala
FROM Employee GROUP BY EmpDepartment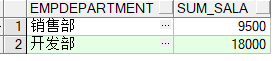
partition by
SELECT EmpSalary,EmpDepartment,SUM(EmpSalary) OVER(PARTITION BY EmpDepartment) sum_sala
FROM Employee
总结: group by 和 partition by 都有分组统计的功能,但是partition by并不具有group by的汇总功能。partition by统计的每一条记录都存在,而group by将所有的记录汇总成一条记录(类似于distinct EmpDepartment 去重)。partition by可以和聚合函数结合使用,同时具有其他高级功能。
3、dense_rank() over(业务逻辑)
作用:查出指定条件后的进行排名,条件相同排名相同,排名间断不连续。
说明:和rank() over 的作用相同,区别在于dense_rank() over 排名是密集连续的。例如学生排名,使用这个函数,成绩相同的两名是并列,下一位同学接着下一个名次。即:1 1 2 3 4 5 5 6
SELECT id, name, score, dense_rank() over(ORDER BY score DESC) AS 'rank' FROM student 
select name,subject,score,dense_rank() over(partition by subject order by score desc) `rank`
from student_score;
4、row_number() over(业务逻辑)
作用:查出指定条件后的进行排名,条件相同排名也不相同,排名间断不连续。
说明:这个函数不需要考虑是否并列,即使根据条件查询出来的数值相同也会进行连续排序。即:1 2 3 4 5 6
SELECT id, name, score, row_number() over(ORDER BY score DESC) AS 'rank' FROM student 
select name,subject,score,row_number() over(partition by subject order by score desc) `rank`
from student_score; 