数据准备
hello,world,hadoop
hive,sqoop,flume,hello
kitty,tom,jerry,world
hadoop
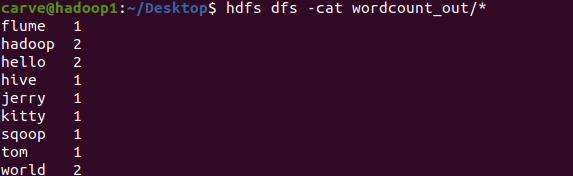
实现结果
文件结构

编程流程



编写代码
JobMain.java
package cn.itcast.mapreduce;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class JobMain extends Configured implements Tool {
// 该方法用于指定一个job任务
public int run(String[] args) throws Exception {
if (args.length != 2){
System.out.println("WordCount <input> <output>");
System.exit(-1);
}
// 1: 创建一个job任务
Job job = Job.getInstance(super.getConf(),"wordcount");
// 2: 配置job任务对象(八个步骤)
// 第一步:指定文件的读取方式和读取路径
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(job,new Path(args[0]));
// 第二步:指定Map阶段的处理方式和数据类型
job.setMapperClass(WordCountMapper.class);
job.setMapOutputKeyClass(Text.class); // 设置Map阶段K2的类型
job.setMapOutputValueClass(Text.class); // 设置Map阶段V2的类型
// 第三,四,五,六 采用默认的方式
// 第七步:指定Reduce阶段的处理方式和数据类型
job.setReducerClass(WordCountReducer.class);
job.setOutputKeyClass(Text.class); // 设置K3的类型
job.setMapOutputValueClass(LongWritable.class); // 设置V3的类型
// 第八步:设置输出类型
job.setOutputFormatClass(TextOutputFormat.class);
// 设置输出的路径
TextOutputFormat.setOutputPath(job,new Path(args[1]));
// 等待任务结束
boolean bl = job.waitForCompletion(true);
return bl ? 0:1;
}
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
// 启动job任务
int run = ToolRunner.run(configuration,new JobMain(),args);
System.exit(run);
}
}
WordCountMapper.java
package cn.itcast.mapreduce;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/*
四个泛型解释:
KEYIN: K1的类型
VALUEIN: V1的类型
KEYOUT: K2的类型
VALUEOUT: V2的类型
*/
public class WordCountMapper extends Mapper<LongWritable,Text,Text,LongWritable>{
// map 方法就是将 K1 和 V1 转为 K2 和 V2
/*
参数:
key : K1 行偏移量
value : V1 每一行的文本数据
context : 表示上下文对象
*/
/*
如何将 K1和V1 转为 K2和V2
K1 V1
0 hello,world,hadoop
17 hdfs,hive,hello
------------------------------
K2 V2
hello 1
world 1
hdfs 1
hadoop 1
hello 1
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
Text text = new Text();
LongWritable longWritable = new LongWritable();
// 1: 将一行的文本数据进行拆分
String[] split = value.toString().split(",");
// 2: 遍历数组,组装 K2 和 V2
for (String word : split){
// 3: 将 K2 和 V2 写入上下文
text.set(word);
longWritable.set(1);
context.write(text,longWritable);
}
}
}
WordCountReducer.java
package cn.itcast.mapreduce;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/*
四个泛型解释:
KEYIN: K2类型
VALUEIN: V2类型
KEYOUT: K3类型
VALUEOUT: V3类型
*/
public class WordCountReducer extends Reducer<Text, LongWritable,Text,LongWritable> {
// reduce 方法作用: 将新的K2和V2转为K3和V3,将K3和V3写入上下文中
/*
参数:
key: 新K2
values: 集合 新V2
context: 表示上下文对象
-----------------------
如何将新的K2和V2转为K3和V3
新 K2 V2
hello <1,1,1>
world <1,1>
hadoop <1>
-----------------------
K3 V3
hello 3
world 2
hadoop 1
*/
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
long count = 0;
// 1: 遍历集合,将集合中的数字相加,得到 V3
for (LongWritable value : values){
count += value.get();
}
// 2: 将K3和V3写入上下文中
context.write(key,new LongWritable(count));
}
}
集群运行
-
将 MapReduce 程序提交给 Yarn 集群,分发到很多的节点上并发执行
-
处理的数据和输出结果应该位于 HDFS 文件系统
-
提交集群的实现步骤:装程序打包成 JAR 包,并上传,然后在集群上用 hadoop 命令启动
hadoop jar hadoop_hdfs_operate-1.0-SNAPSHOT.jar cn.itcast.mapreduce.JobMain wordcount wordcount_out