every blog every motto: Just live your life cause we don’t live twice.
0. 前言
深度学习加速之自动混合精度
1. 正文
总共两种方法
1.1. 方法一:NVIDIA第三方包
需求:pytorch1.5之前的版本(包括1.5)
使用方法:
from apex import amp
model,optimizer = amp.initial(model,optimizer,opt_level="O1") #注意是O,不是0
with amp.scale_loss(loss,optimizer) as scaled_loss:
scaled_loss.backward()取代loss.backward()
其中,opt_level配置如下:
-
O0:纯FP32训练,可作为accuracy的baseline;
-
O1:混合精度训练(推荐使用),根据黑白名单自动决定使用FP16(GEMM,卷积)还是FP32(softmax)进行计算。
-
O2:几乎FP16,混合精度训练,不存在黑白名单 ,除了bacthnorm,几乎都是用FP16计算;
-
O3:纯FP16训练,很不稳定,但是可以作为speed的baseline;
1.2 方法二:pytorch1.6自带的torch.cuda.amp
有两个接口
1. autocast
from torch.cuda.amp import autocast as autocast
model=Net().cuda()
optimizer=optim.SGD(model.parameters(),...)
for input,target in data:
optimizer.zero_grad()
with autocast():
output=model(input)
loss = loss_fn(output,target)
loss.backward()
optimizer.step()
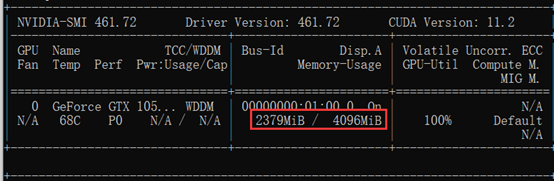
说明: 参考文献2中指出,需要GPU支持Tensor core才可以使用,笔者笔记本GPU为GTX 1050Ti,按理说是不支持的,但实验发现占用显存情况确有明显降低,具体如下:
没有使用:

使用以后:
2. GradScaler
from torch.cuda.amp import autocast as autocast
model=Net().cuda()
optimizer=optim.SGD(model.parameters(),...)
scaler = GradScaler() #训练前实例化一个GradScaler对象
for epoch in epochs:
for input,target in data:
optimizer.zero_grad()
with autocast(): #前后开启autocast
output=model(input)
loss = loss_fn(output,targt)
scaler.scale(loss).backward() #为了梯度放大
#scaler.step() 首先把梯度值unscale回来,如果梯度值不是inf或NaN,则调用optimizer.step()来更新权重,否则,忽略step调用,从而保证权重不更新。 scaler.step(optimizer)
scaler.update() #准备着,看是否要增大scaler
参考文献
[1] https://www.cnblogs.com/jimchen1218/p/14315008.html
[2] https://zhuanlan.zhihu.com/p/295468659