AI框架部署方案:模型量化概述

文 @ 不愿透露姓名的小 P 同学
前言
随着深度学习的发展,一方面深度学习模型的规模和表达能力不断提升,另一方面业务场景和需求也不断丰富。
如何在业务场景下实现模型的高性价比部署,是一个重要且亟待解决的问题。
一般地说,模型部署面临内存和性能的双重挑战,我们往往需要在有限的内存限制下,达成业务需要的吞吐量或者延时指标。
这就需要进行部署优化。目前主要的部署优化方案包括剪枝、量化、稀疏、蒸馏等,本文先针对最简便的部署优化方案——量化进行一些讨论,主要内容包括:
- 模型量化的原理
- 模型量化的优势
- 模型量化的落地问题
模型量化的原理
量化是指将信号的连续取值(或者大量可能的离散取值)近似为有限多个(或较少的)离散值的过程。量化显然会降低数据的精度,那么模型量化一定会降低模型推理的精度么?
答案是 NO!或者说,存在可接受范围内的少量精度损失。
这得益于深度学习模型自身的泛化性:深度学习模型往往具备非常大的参数量,模型参数所能表达的特征空间会大于业务模型所需要表达的特征空间。
因此,剪枝、量化、稀疏、蒸馏等部署优化方案可以在很小的推理精度损失的前提下实现模型轻量化。
基于同样的原理,深度学习模型也会有一定的抗噪声干扰能力[1],感兴趣的同学,可以尝试对神经网络计算随机加噪声,在一定的可接受噪声下,网络模型仍可保持一定的准确性。
关于量化方案,有多种分类方法,这里介绍一种常用的分类方法:线性量化与非线性量化。
在实际部署场景中,线性量化主要以均匀量化为典型,非线形量化主要以 LOG 量化为典型。
这里首先给出一个均匀量化的例子:
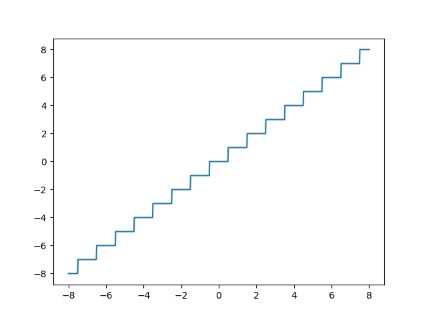
如上图所示,\(x\) 进行 8bit 对称量化,量化范围为 \((-\alpha,\alpha)\)。 其具体表达形式可展开为:
\(Q(x) = clamp(round(\frac{x}{s}), \min=-128.0, \max=127.0),\ s = \frac{\alpha}{127.0}\)
基于上述形式分析,其量化噪声主要分为表达范围内的随机噪声和表达范围外的截断噪声,也就是长尾分布导致数据溢出。
再来看一个 LOG 量化的例子:
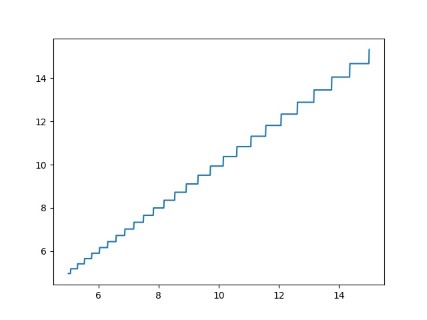
如上图所示,量化范围与均匀量化的例子相同,
\(Q(x) = \text{sgn}(x)(clamp(round(2^{k}\log_{2}(\text{abs}(x)), \min= base) - base) \)
不同的量化方式对数据分布是有选择性的。
对于均匀量化,假设数据在整个表达空间内均匀分布,在均匀分布下,线性量化是一种较好的量化方式。
LOG 量化则主要可以保证数值空间内的相对误差最优化,其采样特征原则为小数采样密集,大数保证轮廓特征。
这是目前大部分非线性量化的目标:通过对数据分布的分析,提升高密度数据区域的表达能力。
模型量化的优势
在模型业务部署过程中,往往会把模型部署到芯片上。这时候采用量化方案来进行模型部署优化有以下三个方面优势:存储优势、计算优势、通信优势。
存储优势
芯片的内存大小是影响模型能否正常部署的重要因素之一。
深度学习模型通常具有较大参数规模,这带来了部署过程的一大典型问题——存储空间不足。
INT8 量化的数据表达空间是常见浮点表示的 1/4,在实际工程落地中,可以根据量化方案采取更低比特的模型表示。
这就可以降低计算过程中的存储开销。
具体案例常见于嵌入式 MCU 芯片,其内存空间有限导致大模型无法部署。目前常见的深度学习 CV 领域 MCU 芯片存储空间一般仅有几百兆,若浮点网络原存储空间为 1G,那么定点化部署后存储表示空间可压缩至 250M 左右,这样就可以让原本不支持大模型部署的芯片具备支持大模型部署的能力。
计算优势
从目前的市场上芯片成本来看,只能抛砖引玉给一个粗浅的观点:量化芯片每 T 算力具备更高的性价比。
以 GPU 为例,一个 cuda core 带有相比 FP32 计算单元 4 倍的 INT8 计算单元。
另一方面,寄存器也是限制芯片计算成本的重要因素。因此,INT8 的寄存器单元需求相比 FP32 同样减小到 1/4。
综上所述,在目前的定制 TPU 芯片上,定点化算力成本相比 FP32 算力成本有较大优势。
但是,不可避免的,FP32 算子已经经过了长期的技术优化(比如 wingorad、FFT 等),而这些优化在定点化算子中仍旧处于考虑结合阶段。
事实上,定点化算力优势主要体现在卷积等常见计算密集型算子。因此,定点化算力的实际使用还是需要算子的适配性。
对于常见算子,INT8 相比 FP32 更具算力优势。以 ResNet50 为例, 在单卡 Nvidia T4 显卡环境使用 TensorRT 7.0 作为推理引擎,以 FP32 为计算精度,模型的峰值推理能力为 1632 imgs/s,若以 INT8 为计算精度,则吞吐量可以提升到 5217 imgs/s [2]。对于以上场景,INT8 带来了巨大的计算性能提升。
通信优势
在 NN 计算芯片内部,数据的流动过程可以抽象为一个小型网络,通过多层存储结构实现数据缓存,在计算单元完成计算后,结果需要流动到系统内存。
在 FP32 计算中,当计算网络超过存储通信限制时,会出现计算单元等待数据的访存瓶颈。
定点化计算可以通过低比特量化对数据进行压缩,从而降低芯片的通信开销。
TPU 芯片设计过程中,从经验上来说,算力的提升速度往往会超越带宽的提升速度。此时,通过算法与编译器的结合,可以实现计算换取通信,从而使得片上算力被有效利用。
在部署领域,定点化可以改善部分算子的通信,从而带来通信优势。
以一个常见的 InnerProduct 算子为例,假设算力为 100G ops/s,片上 DDR 通信能力为 50G Byte/s,即 MCU 芯片常见配置,X 计算形状为 1 * 28000,weight为 28000 * 1000,此时计算延时为 0.28 ms,通信 DDR 延时为 2.24 ms,该算子主要耗时为通信延时,此时若对该算子进行量化,可以大幅降低其通信延时(减小到原来的 1/4), 从而提供更高的网络计算性能。
量化的落地问题
基于实际的部署经历, 量化过程中出现的问题, 可以概括为以下三大难点:
- 多后端难点
- 硬件黑盒难点
- 量化误差分析难点
多后端难点
不同芯片后端的量化算法实现具有不同的特点。
目前,量化算子在实际落地过程中有着不同实现,这就带来了一个生产问题:对于不同的硬件,用户需要针对硬件研究不同的量化方案。这同时也会导致量化方案的硬件泛化性受到限制。
所谓硬件泛化性,主要是指量化模型在泛硬件平台的迁移能力。
这个问题,在此我们留个坑,待后续介绍。
此处先介绍一些基于本问题的简单思考:我们一般会希望通过对常见芯片的量化表达形式总结,并进行量化建模;同时,在一定约束下,对应不同的芯片平台,将模型进行跨硬件的有损转换,以实现芯片和量化算法的解耦。
硬件黑盒难点
个人经验来看,模型的量化部署往往伴随着复杂的模型精度修复工作,特别是在第三方硬件下,需要解决如何与第三方硬件对齐的问题。
但在实际服务过程中,硬件的比特级对齐方案又是部署服务的重中之重。可以通过提供量化算法的模拟环境,使得精度修复算法能够在硬件上复现。
在此,本文先抛砖引玉,给出几个硬件差异的常见来源,在后续系列技术分享中,将会介绍我们是如何进行第三方硬件对齐,并挖掘芯片的计算特性。
个人认为,常见的硬件差异主要源于非计算算子(Concat, Eltwise)的量化处理、累加器的重采样和取整方式的不同。
由于不同硬件在这三点的处理方案不同,引入的噪声形态亦有差别。这里主要将噪声非为随机噪声和非随机噪声两类。
实际操作过程中,需要重点关注硬件未对齐导致的非随机噪声。
可以简单理解为,量化噪声为有一定强度的随机噪声,在网络分析中主要关心其噪声强度对网络信息量的影响。
但若是一个非随机噪声或常数偏移,由于误差的同向特性,NN 计算传递过程中噪声将容易被累加放大。
量化误差定位难点
量化可以提供性能收益,但不可规避的是,量化在计算过程中会引入误差,导致网络部署精度相对于 FP32 会损失部分表达。
在实际业务中,部署的一大挑战在于,如何去保证量化模型的精度,通过降低误差,以保证模型速度和精度的收益平衡。
接下来将简单介绍线形量化方案下量化噪声建模,以及基于建模方案的实际噪声定位问题。
只有了解量化噪声的来源, 才能去定位模型的主要噪声。
本文将对一个简化矩阵乘计算 \(y = wx + b\) 进行量化建模,先对于网络噪声来源进行归类:
- \(x\) 的噪声 \({x_{n}}\);
- \(w\) 的噪声 \({w_{n}}\);
- bias 噪声 \({b_{n}}\);
- 累加器噪声 \(acc_{n}\)。
可以对该计算的量化进行如下建模:
\(y_{q} = clamp(round([Q(x, s_{x}, 8) * Q(w, s_{w}, 8) + Q(b, s_{x}s_{w}, bit)] \frac{s_{x} s_{w}}{s_{y}}), min=-128, max=127)\)
我们基于以上量化建模方式,结合硬件中实际的近似计算方式,进行四大项损失分析:
- \(x\) 噪声,\({x_{n}} = x_{f} - x_{q} s_{x} + n_{round}\),该误差主要来源于两方面:
- 量化建模误差,也就是量化函数 \(Q\) 导致的误差;
- 取整误差,主要来源于不同硬件对于 round 操作的实现差异。
- \(w\) 噪声,\({w_{n}} = w_{f} - w_{q} * s_{w}\),对于 weight 的量化一般可以不用考虑硬件差异误差,只需要考虑量化建模误差,其对于量化 weight 数值是可控的。
- \(b\) 噪声, \({b_{n}} = b_{f} - b_{q} * s_{w} s_{x}\),bias 的误差来源也可以理解为与 \(w\) 同源。
- \(acc\) 噪声, \({acc_{n}} = n_{resample} + n_{round}\),两类误差主要来自于两项计算误差, \(n_{resample}\) 的参数主要源于定点化计算芯片不具备 FP32计算能力, \(\frac{s_{x}s_{w}}{s_{y}} \asymp \frac{k}{2^{m}}\)。需要注意,该误差是一个典型的非随机噪声,同时还存在取整误差。
根据上述定义,\(y_{n}\) 的噪声可以定义为:
\( y_{n} = w * x_{n} + x * w_{n} + b_{n} + acc_{n}\)
上述简单介绍了一个矩阵乘计算可能出现的误差来源。
表达形式中,可以发现对于 \(x\) 和 \(w\) 的噪声还会被交叉放大。
在实际的网络中,网络一般具有多层,误差就会出现多层累积的现象。
基于以上对单层网络的误差建模,我们可以在算法层面对网络在硬件芯片上的计算进行高仿真建模,从而模拟其量化误差。其中包括实际部署过程中芯片的真实误差。
通过对网络误差的分析,定位并对网络整个输出的主要误差进行修正,可以满足部署对于速度和精度的双重追求。
以上仅对单层情况下误差进行简单建模,后续分享中我们将有序的针对不同误差的来源进行分析。
误差来源于不同方面,从数据分布多样性考虑,常见的误差来源主要有数据在不同信道分布不同的量化误差,数据满足多峰分布情况下的误差。
从网络表达能力层面,不同计算层代表的网络信息量不同,其噪声其在网络中的重要性也不同,对应参数的抗干扰能力亦有所不同。
从误差的观察矩阵角度来看,常见衡量方案为矩阵的绝对误差或相似度,但在实际情况下,对于不同的数据,其观察矩阵有所不同,一般需要根据网络的损失函数进行分解建模,如关注数值精度的观察矩阵和关注最大值的轮廓表达特性在信息量的表达,亦是不同的考虑范畴。
以及在多后端多硬件情况下,还需要解决如何实现量化的鲁棒性以降低网络中来自于硬件的非随机噪声的问题。
当然,更为关键的,是如何根据量化损失去选择合适的量化算法,包括基于重训练方式的 QAT 方案,或者基于网络数值近似情况的离线量化等方案, 以及网络的数值变形获得对于量化硬件鲁棒性高的模型表达。以上种种问题,还请继续关注 AI 框架技术分享模型部署专题系列。
大家如果有感兴趣的技术内容和难点欢迎随时指出,可以在评论区给我们留言~
References
[1]: Gupta S, Agrawal A, Gopalakrishnan K, et al. Deep learning with limited numerical precision[C], International conference on machine learning. PMLR, 2015: 1737-1746.
关注 公众号「SenseParrots」,获取人工智能框架前沿业界动态与技术思考:
