参考https://zhuanlan.zhihu.com/p/41201441
问题1

假设你的训练样本是句子(单词序列)。下面哪个选项指的是第i个训练样本中的第j个词?
- x ( i ) < j > x^{(i)<j>} x(i)<j>。正确
- x < i > ( j ) x^{<i>(j)} x<i>(j)
- x ( j ) < i > x^{(j)<i>} x(j)<i>
- x < j > ( i ) x^{<j>(i)} x<j>(i)

首先获取第i个训练样本(用括号表示),然后到 j列获取单词(用括尖括号表示)。
=============================================================
问题2

在下面的条件中,满足上图循环神经网络中的网络结构的参数是:
- Tx=Ty。正确
- Tx<Ty
- Tx>Ty
- Tx=1

上图中每一个输入都与输出相匹配。
=============================================================
问题3

以下这些任务中的哪一个会使用多对一的RNN体系结构?

-
语音识别(输入语音,输出文本)。

-
情感分类(输入一段文字,输出0或1表示正面或者负面的情绪)。正确

-
图像分类(输入一张图片,输出对应的标签)。

-
人声性别识别(输入语音,输出说话人的性别)。正确

=============================================================
问题4


假设你现在正在训练上面这个RNN的语言模型:
在t时,这个RNN在做什么?
- 计算 P ( y < 1 > , y < 2 > , … , y < t − 1 > ) P(y^{<1>},y^{<2>},…,y^{<t−1>}) P(y<1>,y<2>,…,y<t−1>)
- 计算 P ( y < t > ) P(y^{<t>}) P(y<t>)
- 计算 P ( y < t > ∣ y < 1 > , y < 2 > , … , y < t − 1 > ) P(y^{<t>}∣y^{<1>},y^{<2>},…,y^{<t−1>}) P(y<t>∣y<1>,y<2>,…,y<t−1>)。正确
- 计算 P ( y < t > ∣ y < 1 > , y < 2 > , … , y < t > ) P(y^{<t>}∣y^{<1>},y^{<2>},…,y^{<t>}) P(y<t>∣y<1>,y<2>,…,y<t>)
=============================================================
问题5

你已经完成了一个语言模型RNN的训练,并用它来对句子进行随机取样,如下图:

在每个时间步t都在做什么?
- (1) 使用RNN输出的概率,选择该时间步的最高概率单词作为 y ^ < t > \hat y^{<t>} y^<t>,(2) 然后将训练集中的正确的单词传递到下一个时间步。

- (1) 使用由RNN输出的概率将该时间步的所选单词进行随机采样作为 y ^ < t > \hat y^{<t>} y^<t>,(2) 然后将训练集中的实际单词传递到下一个时间步。

- (1)使用由RNN输出的概率来选择该时间步的最高概率词作为 y ^ < t > \hat y^{<t>} y^<t>,(2)然后将该选择的词传递给下一个时间步。

- (1)使用RNN该时间步输出的概率对单词随机抽样的结果作为 y ^ < t > \hat y^{<t>} y^<t>,(2)然后将此选定单词传递给下一个时间步。正确

=============================================================
问题6

你正在训练一个RNN网络,你发现你的权重与激活值都是“NaN”,下列选项中,哪一个是导致这个问题的最有可能的原因?
- 梯度消失

- 梯度爆炸。正确

- ReLU函数作为激活函数g(.),在计算g(z)时,z的数值过大了

- Sigmoid函数作为激活函数g(.),在计算g(z)时,z的数值过大了

课程链接
=============================================================
问题7

假设你正在训练一个LSTM网络,你有一个10,000词的词汇表,并且使用一个激活值维度为100的LSTM块,在每一个时间步中,Γu的维度是多少?
- 1
- 100。正确
- 300
- 10000
Correct, Γu is a vector of dimension equal to the number of hidden units in the LSTM.
Γu的向量维度等于LSTM中隐藏单元的数量。
=============================================================
问题8

这里有一些GRU的更新方程:

Alice建议通过移除 Γu来简化GRU,即设置Γu=1。
Betty提出通过移除Γr来简化GRU,即设置Γr=1。
哪种模型更容易在梯度不消失问题的情况下训练,即使在很长的输入序列上也可以进行训练?
- Alice的模型(即移除Γu),因为对于一个时间步而言,如果Γr≈0,梯度可以通过时间步反向传播而不会衰减。
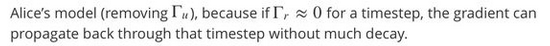
- Alice的模型(即移除Γu),因为对于一个时间步而言,如果Γr≈1,梯度可以通过时间步反向传播而不会衰减。

- Betty的模型(即移除Γr),因为对于一个时间步而言,如果Γu≈0,梯度可以通过时间步反向传播而不会衰减。正确

- Betty的模型(即移除Γr),因为对于一个时间步而言,如果Γu≈1,梯度可以通过时间步反向传播而不会衰减。
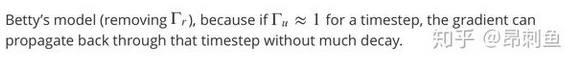
课程链接
=============================================================
问题9


这里有一些GRU和LSTM的方程: 从这些我们可以看到,在LSTM中的更新门和遗忘门在GRU中扮演类似 –––––与–––––的角色,空白处应该填什么?
- Γu 与 1−Γu。正确
- Γu 与 Γr
- 1−Γu 与 Γu
- Γr 与 Γu
=============================================================
问题10

你有一只宠物狗,它的心情很大程度上取决于当前和过去几天的天气。你已经收集了过去365天的天气数据x<1>,…,x<365>,这些数据是一个序列,你还收集了你的狗心情的数据y<1>,…,y<365>,你想建立一个模型来从x到y进行映射,你应该使用单向RNN还是双向RNN来解决这个问题?
- 双向RNN,因为在t日的情绪预测中可以考虑到更多的信息。
- 双向RNN,因为这允许反向传播计算中有更精确的梯度。
- 单向RNN,因为y的值仅依赖于x<1>,…,x,而不依赖于x<t+1>,…,x<365>。正确
- 单向RNN,因为y的值只取决于x,而不是其他天的天气。
关于双向RNN,参见链接