SparkSql入门(基本信息的调用)
package sql
import org.apache.avro.ipc.specific.Person
import org.apache.spark
import org.apache.spark.rdd.RDD
import org.apache.spark.sql
import org.apache.spark.sql.catalyst.InternalRow
import org.apache.spark.sql.{
DataFrame, Dataset, Row, SparkSession}
import org.junit.Test
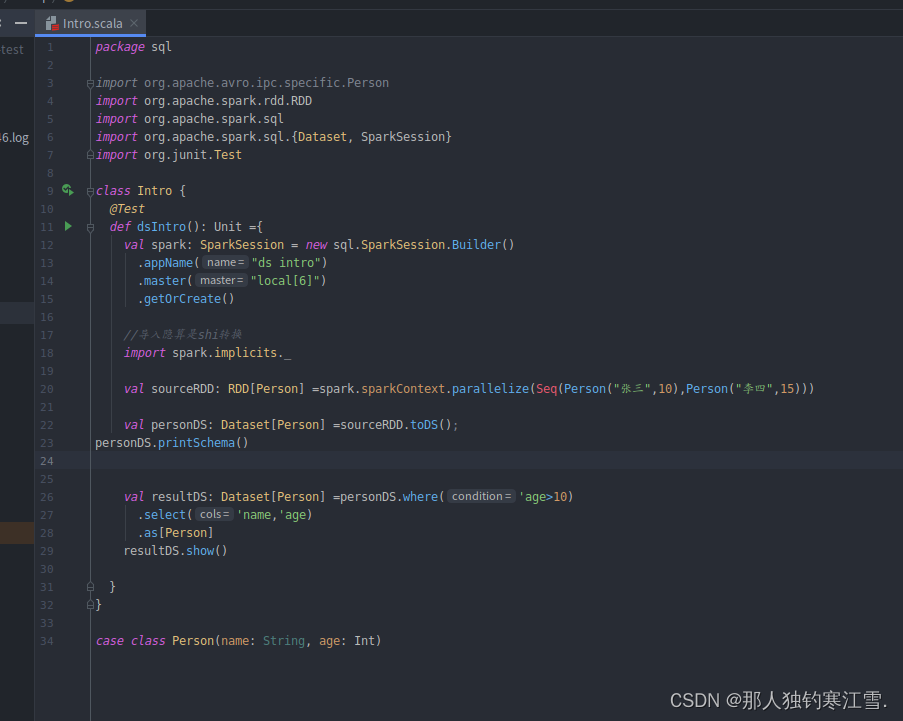
class Intro {
@Test
def dsIntro(): Unit ={
val spark: SparkSession = new sql.SparkSession.Builder()
.appName("ds intro")
.master("local[6]")
.getOrCreate()
//导入隐算是shi转换
import spark.implicits._
val sourceRDD: RDD[Person] =spark.sparkContext.parallelize(Seq(Person("张三",10),Person("李四",15)))
val personDS: Dataset[Person] =sourceRDD.toDS();
//personDS.printSchema()打印出错信息
val resultDS: Dataset[Person] =personDS.where('age>10)
.select('name,'age)
.as[Person]
resultDS.show()
}
@Test
def dfIntro(): Unit ={
val spark: SparkSession =new SparkSession.Builder()
.appName("ds intro")
.master("local")
.getOrCreate()
import spark.implicits._
val sourceRDD: RDD[Person] = spark.sparkContext.parallelize(Seq(Person("张三",10),Person("李四",15)))
val df: DataFrame = sourceRDD.toDF()//隐shi转换
df.createOrReplaceTempView("person")//创建表
val resultDF: DataFrame =spark.sql("select name from person where age>=10 and age<=20")
resultDF.show()
}
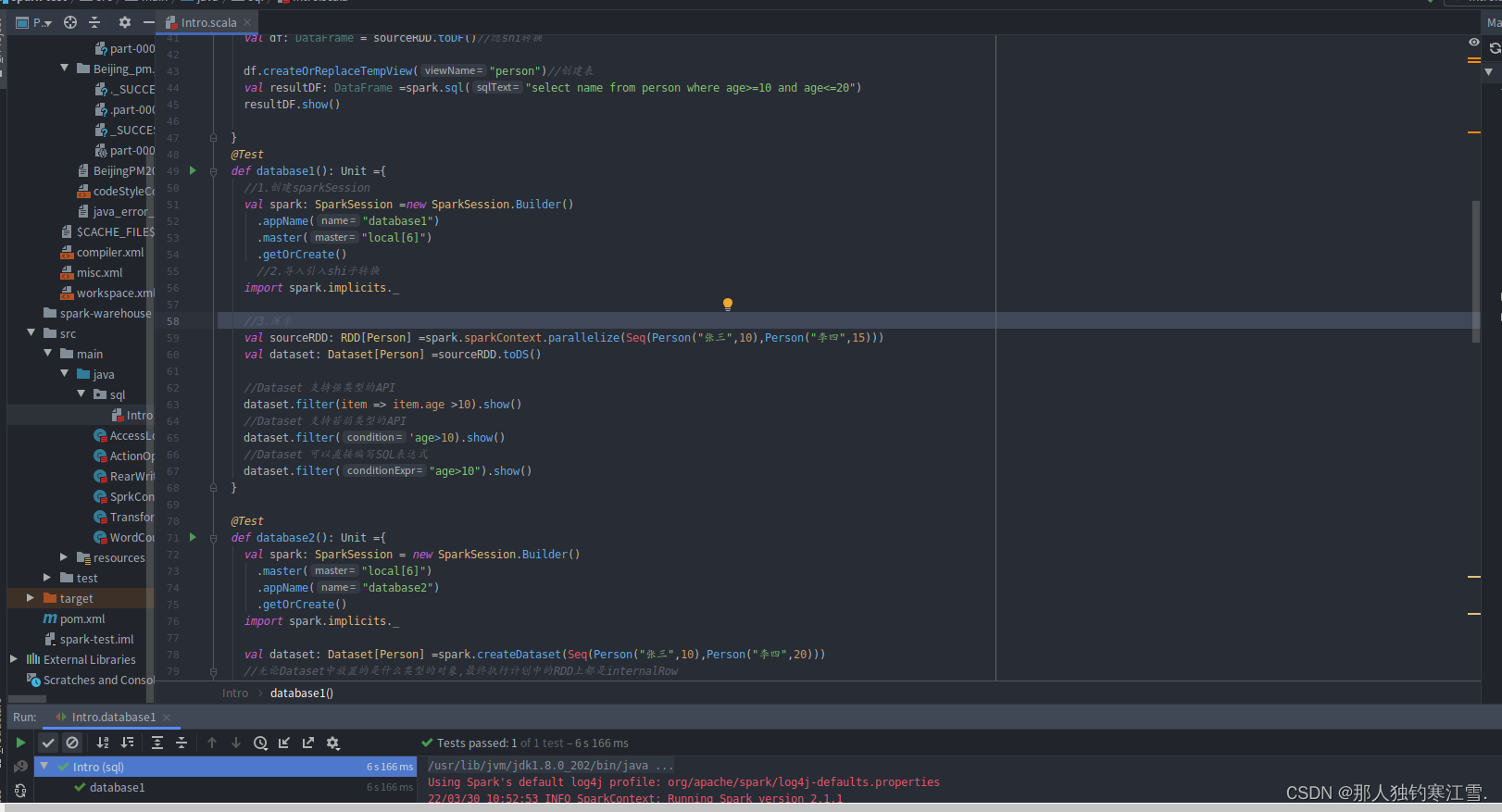
@Test
def database1(): Unit ={
//1.创建sparkSession
val spark: SparkSession =new SparkSession.Builder()
.appName("database1")
.master("local[6]")
.getOrCreate()
//2.导入引入shi子转换
import spark.implicits._
//3.演示
val sourceRDD: RDD[Person] =spark.sparkContext.parallelize(Seq(Person("张三",10),Person("李四",15)))
val dataset: Dataset[Person] =sourceRDD.toDS()
//Dataset 支持强类型的API
dataset.filter(item => item.age >10).show()
//Dataset 支持若弱类型的API
dataset.filter('age>10).show()
//Dataset 可以直接编写SQL表达式
dataset.filter("age>10").show()
}