目录

一 介绍
Elasticsearch 是一个分布式全文搜索引擎,简称es
全文搜索过程:
分词 → 通过分词查到数据的ID → 通过id得到部分数据

特征:
1 倒排索引:由数据到ID
2 要想用全文搜索技术,需要先创建文档,,再使用文档
二 下载
官方下载地址:
Elasticsearch 7.16.2 | Elastic
(我运行最新的8版本有问题,后来使用7.16版本就没有问题)

链接:https://pan.baidu.com/s/1joFKYSMtCK8nr3UWnwrh-w
提取码:0629
默认提供了一个jdk17的版本
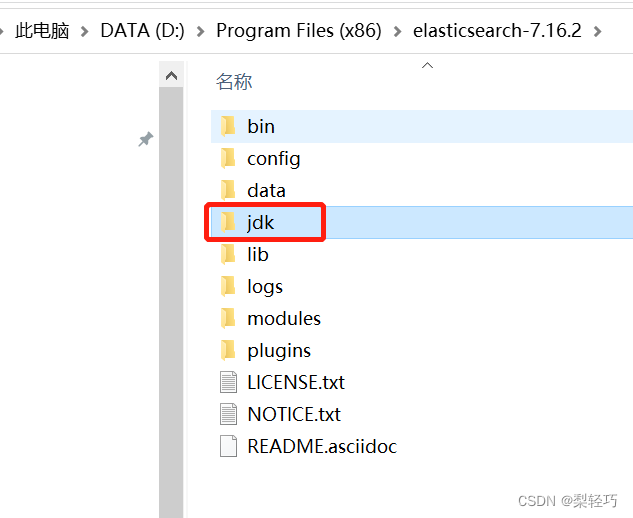

三 开启服务端


有两个端口9300和9200,其中9200是对外提供服务的端口
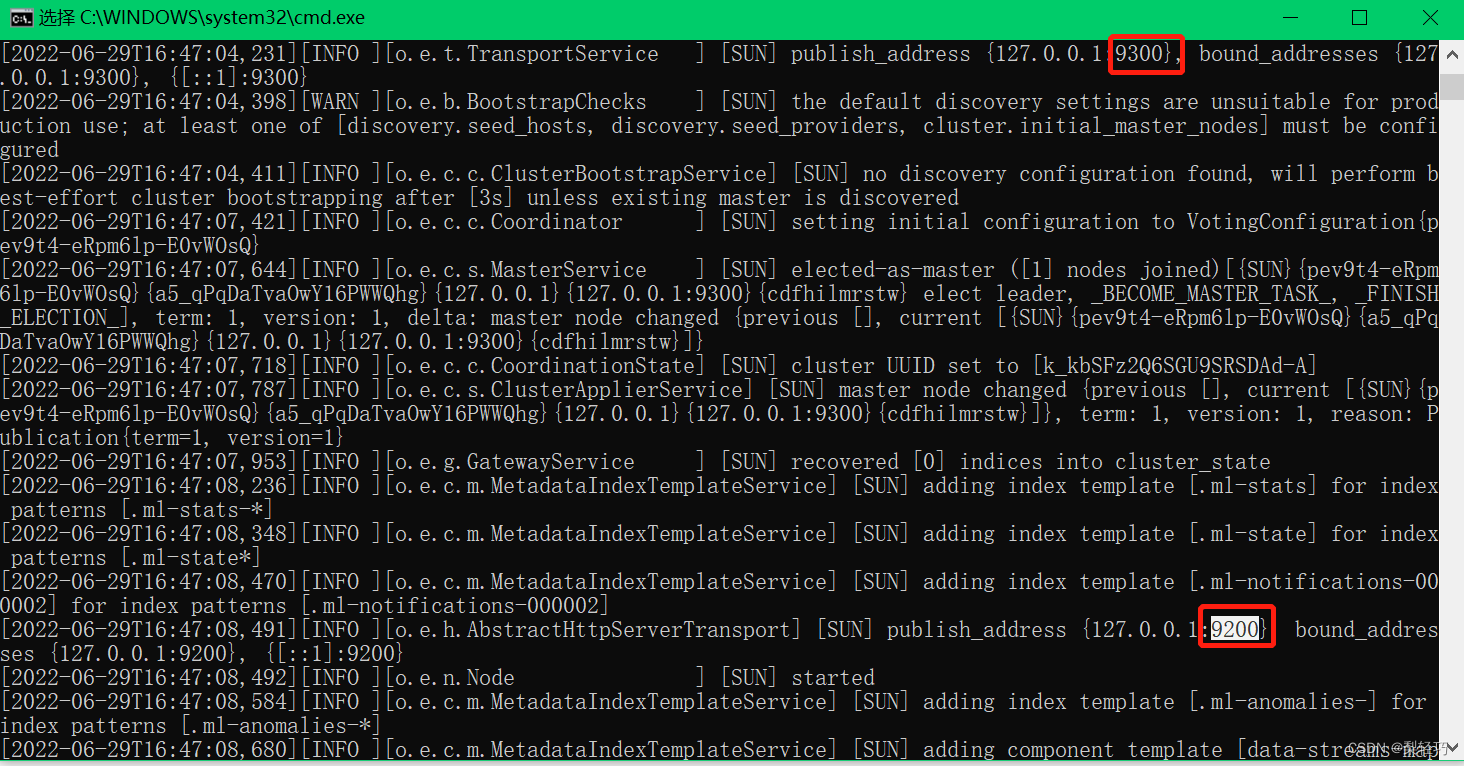
能访问到9200

四 索引操作
在postman里操作
4.1 不使用分词器创建索引
put
创建books的索引

4.2 查询索引
get
查询books的索引

4.3 删除索引
delete
删除books的索引

*4.4 使用分词器创建索引
分词:就是把一条数据提取出不同的搜索关键字,方便检索的时候 根据分出的关键字 就能检索到这条数据
打开es的plugins文件夹,在下面创建ik文件夹: 把下载的分词器解压放在这里
分词器插件放好后,需要重新启动es服务端
使用分词器创建索引

body里添加的完整json数据如下图:
其中id 和 type属性类型是keyword,直接是关键字,直接检索id/type就能找到这条数据
其中name和description属性类型是text,需要分词得到关键字,根据分词后的关键字能检索到这条数据
同时,这里设计了一个虚拟的属性:all,all这个属性从name 和 description 复制而来,目的是搜索某一个关键字,不管它是在name里还是在 description里都要能检索到这条数据,所以设置了一个name和description合并的属性all

备注:因为之前创建了books索引,如果此处想用分词器重新创建索引,需要先把body清空执行一下delete
重新get

总结

其中all是设计的字段,来自于name和description 的拷贝字段
五 文档操作(数据操作)
postman操作



六 SpringBoot整合ES
6.1 未使用分词器的整合
1 导入高版本的依赖

2 客户端

2 客户端(改进)

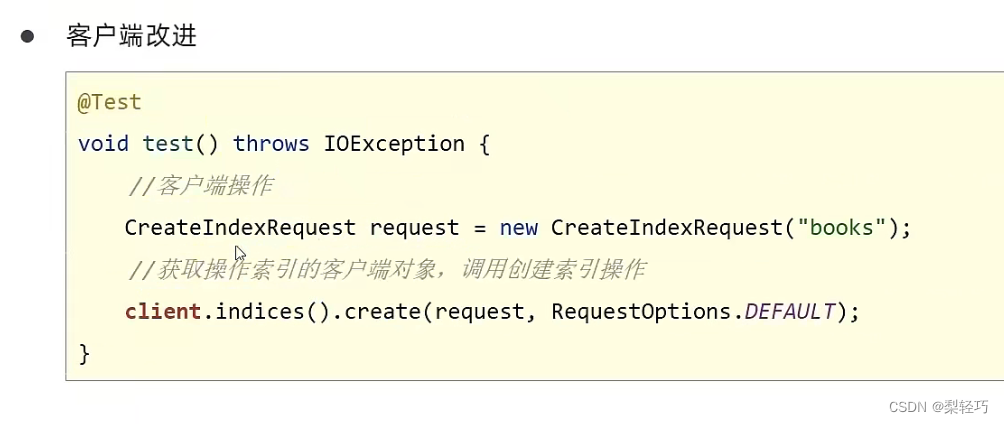
6.2 使用分词器整合
和6.1的区别

6.3 添加文档

6.4 查询文档

Query里的all就是前面设计的all = name + description
hit就是得到的里面的一条数据

getSourceAsString 就是 下面的这个_source数据