我们一般会采用n-gram模型,就是假设一个词只与前n个词有关系,如n=1,就是假设所有的词都是独立的,因此一个分割形式的概率,就是各个分割词的概率乘积,这样前面计算的,后面就不用再计算了,这样就可以用动态规划的方法来做。
在确定一个新节点的状态时,前面所有的节点状态节点均已确定,只需要确定前面那些节点和这个新节点有连接的节点,然后计算所有连接中累积概率最大的一个连接即可。累积概率用新节点的前一个节点的累积概率,和前一个节点与新节点之间夹着的词的乘积即可。计算与新节点的连接前驱节点,就是按照词的最大长度,确定一个范围即可。
算法首先要还保证计算一个节点的时候,其前面的节点状态都计算过了。我们计算节点状态的时候,是从第一个节点开始,依次计算每个节点的,这点当然就可以保证。核心函数,就是计算一个新节点的状态。
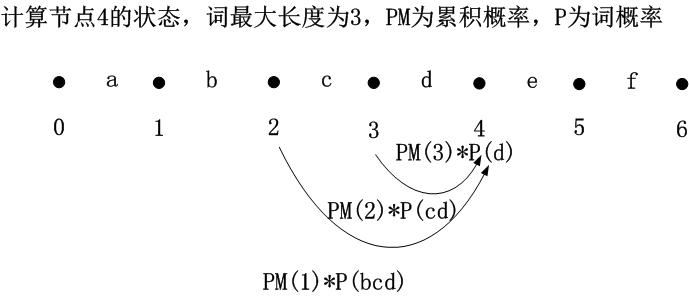
如上图所示,要计算节点4的状态,就是依次向前找3个节点,3就是最大的词的长度,然后这个3个节点就是后续前驱节点,然后计算它们到节点4的累积概率,如PM(2)*P(cd)最大,则该值就是节点4最大的累积概率,而节点2就是节点4的最优的前驱节点。
上代码,还是用的英文字母分词,就是把英文单词空格去掉后,然后再分词,注意,这里词典记录的是每个词的词频,而不是概率,这样一个词的概率就是其词频除以总词频,对未出现的词,采用简单的+a平滑方法。

#!/usr/bin/env python
#coding=utf-8
#############################################################
#function: max probility segment
# a dynamic programming method
#
#input: dict file
#output: segmented words, divide by delimiter " "
#author: wangliang.f AT gmail.com
##############################################################
import sys
import math
#global parameter
DELIMITER = " " #分词之后的分隔符
class DNASegment:
def __init__(self):
self.word_dict = {} #记录概率
self.word_dict_count = {} #记录词频
self.gmax_word_length = 0
self.all_freq = 0 #所有词的词频总和
def get_unkonw_word_prob(self, word):
return math.log(10./(self.all_freq*10**len(word)))
#寻找node的最佳前驱节点
#方法为寻找所有可能的前驱片段
def get_best_pre_node(self, sequence, node, node_state_list):
#如果node比最大词长小,取的片段长度以node的长度为限
max_seg_length = min([node, self.gmax_word_length])
pre_node_list = [] #前驱节点列表
#获得所有的前驱片段,并记录累加概率
for segment_length in range(1,max_seg_length+1):
segment_start_node = node-segment_length
segment = sequence[segment_start_node:node] #获取片段
pre_node = segment_start_node #若取该片段,则记录对应的前驱节点
#获得片段的概率
if (self.word_dict.has_key(segment)): #如果字典包含这个词
segment_prob = self.word_dict[segment]
else: #如果没有这个词,则取一个很小的概率
segment_prob = self.get_unkonw_word_prob(segment)
#当前node一个候选前驱节点到当前node的累加概率值
candidate_prob_sum = pre_node_prob_sum + segment_prob
pre_node_list.append((pre_node, candidate_prob_sum))
#找到最大的候选概率值
(best_pre_node, best_prob_sum) = max(pre_node_list,key=lambda d:d[1])
return (best_pre_node, best_prob_sum)
#最大概率分词
def mp_seg(self, sequence):
sequence = sequence.strip()
#初始化
node_state_list = [] #记录节点的状态,该数组下标对应节点位置
#初始节点,也就是0节点信息
ini_state = {}
ini_state["pre_node"] = -1 #前一个节点
ini_state["prob_sum"] = 0 #当前的概率总和
node_state_list.append( ini_state )
#逐个节点寻找最佳前驱节点
#字符串概率为1元概率,#P(ab c) = P(ab)P(c)
for node in range(1,len(sequence) + 1):
#寻找最佳前驱节点,并记录当前最大的概率累加值
(best_pre_node, best_prob_sum) = \
self.get_best_pre_node(sequence,node,node_state_list)
#记录当前节点信息
cur_node = {}
cur_node["pre_node"] = best_pre_node
cur_node["prob_sum"] = best_prob_sum
node_state_list.append(cur_node)
# step 2, 获得最优路径,从后到前
best_path = []
node = len(sequence) #最后一个点
best_path.append(node)
while True:
pre_node = node_state_list[node]["pre_node"]
if pre_node == -1:
break
node = pre_node
best_path.append(node)
best_path.reverse()
# step 3, 构建切分
word_list = []
for i in range(len(best_path)-1):
word = sequence[left:right]
word_list.append(word)
seg_sequence = DELIMITER.join(word_list)
return seg_sequence
#加载词典,为词\t词频的格式
def initial_dict(self,filename):
dict_file = open(filename, "r")
for line in dict_file:
sequence = line.strip()
key = sequence.split('\t')[0]
value = float(sequence.split('\t')[1])
self.word_dict_count[key] = value
#计算频率
self.all_freq = sum(self.word_dict_count.itervalues()) #所有词的词频
#计算每个词的概率,用log形式
for key in self.word_dict_count:
value = self.word_dict_count[key]
self.word_dict[key] = math.log(value/self.all_freq) #取自然对数
#test
if __name__=='__main__':
myseg = DNASegment()
myseg.initial_dict("count_1w.txt")
sequence = "itisatest"
seg_sequence = myseg.mp_seg(sequence)
print "original sequence: " + sequence
print "segment result: " + seg_sequence
sequence = "tositdown"
seg_sequence = myseg.mp_seg(sequence)
print "original sequence: " + sequence
print "segment result: " + seg_sequence这样就可以正确的将“itisatest” 分为"it is a test"
但第二个序列,"tositdown" 分成了 “to sitdown”,而正确的切分应该是”to sit down“
主要是因为,to sitdown的概率比to sit down搞了一点点,但是如果前面是to的话,一般都会分成
sit down,坐下来,v
而不是sitdown,示威,n
也就是切分形式应该与前一个词有关,这样就应该使用2-gram模型,具体见下一个文章。
字典文件和代码:http://pan.baidu.com/s/1mgJjRde