Rethinking Video Anomaly Detection - A Continual Learning Approach WACV-2022
论文源地址:Rethinking Video Anomaly Detection - A Continual Learning Approach WACV-2022
1,简要概括主旨脉络
先简要概括: 当前的异常视频检测,主要是针对于三大流行数据集中对于设定好的异常帧的检测,当前相关研究存在不足就是只训练模型认识数据集中给出的正常样本特征,那么对于在测试集中未出现的仍旧是正常事件的帧则就可能会被认为是异常。
但是这样的检测方式有些违背现实生活中真实发生的异常活动事件,所以作者团队重新审视视频异常检测,给出了新的数据集和异常检测评价指标,并在此基础上提出了新的检测算法即通过持续学习来实现对异常活动事件的检测。
研究创新点:
1,design a framework for continual learning and propose a new performance metric based on detection delay and alarm precision;
设计了一个持续学习的框架,并提出了一种基于检测延迟和报警精度的新的性能指标;
2,introduce a new comprehensive dataset for continual learning in VAD;
介绍了一个新的基于VAD的持续学习的综合数据集;
3,propose a novel algorithm that significantly outperforms the state-of-the-art methods in online activity detection and continual learning, and provide guidance for future algorithm design.
提出了一种在在线活动检测和持续学习方面显著优于最先进方法的新算法,并为未来的算法设计提供了指导。
2,(Related Work)相关工作
当下的异常检测现在现状:
最近的算法可以广泛分为基于重建的方法以及基于预测的方法,前者通过使用生成对抗网络试图基于重建误差对帧进行分类来实现异常检测;后者试图预测未来的帧在结合实际的groundtruth来实现异常的检测。主要是针对于异常帧的定位检测,缺乏在视频异常检测中时间连续性的考虑,与实际生活中发生的异常事件想差较远。
3,(Continual Video Anomaly Detection)连续的视频异常检测
作者在这一小节提出新的连续的视频异常检测概念。
理想情况下,当一个视频异常检测系统面对新的检测信息时,它应该能够更新其对名义模式/行为(nominal patterns/behaviors)的识别,以避免误报(false alarms)。
然而,这对于现有的算法来说并不容易,因为当前算法广泛依赖于端到端训练的深度神经网络,这些深度神经网络在数据量比较大的基础上训练时容易发生灾难性遗忘 (catastrophic forgetting),在连续训练时,他们往往会忘记以前学到的信息。
因此,在这样的背景下作者团队首先仔细地定义了一个在视频异常检测的背景下的持续学习的框架。然后,作者提出了一种新的评估online activity detection的度量方法,以及一种effective algorithm for continual VAD。
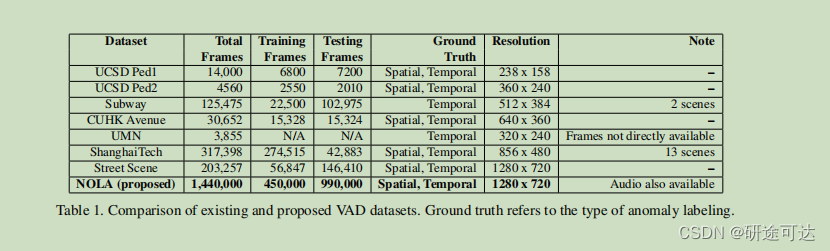
New Dataset: NOLA
作者引入了一个新的数据集,它包括11个片段中的110个训练视频片段和50个测试片段,从美国路易斯安那州新奥尔良一条著名街道的一个移动摄像机上拍摄下来。
数据集链接地址:https://www.earthcam.com/usa/louisiana/neworleans/bourbonstreet/cam=catsmeow2
clipped at 9000 frames, extracted at 30 frames per second.
数据集里面详细的介绍了什么叫异常的定义以及举例,可以直接看原文。

总的来说,该数据集由99万个训练帧和45万测试帧组成,使其明显大于任何其他可用的数据集,如表1所示。该数据集是由作者手动收集、清理和注释的。训练集被分成11个更小的批次,以评估在持续学习方面的性能。其中一个分裂用于初始训练,其余的10个分裂用于评估持续学习性能(图1)。
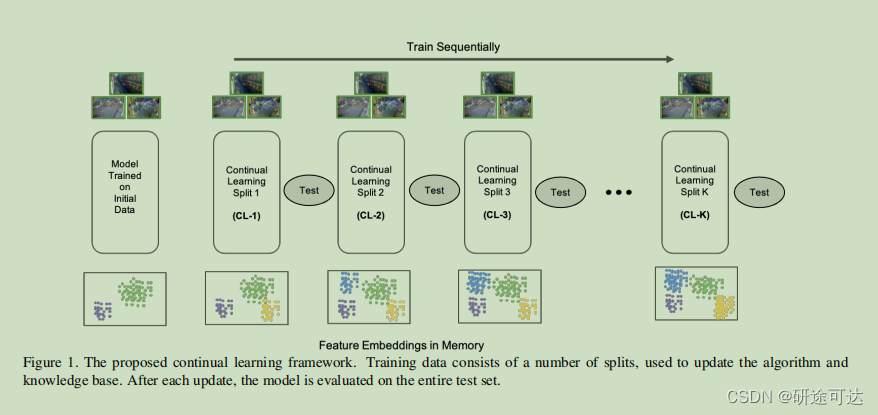
3.1. Problem Formulation
Although a stream of video frames F = {f1, f2, . . . } is a standard data structure for general video processing, for anomaly detection, a video frame is not a natural data unit due to two main reasons: lack of temporal continuity and interpretability.
对于异常检测,视频帧不是一个自然的数据单元,主要有两个原因:缺乏时间连续性和可解释性。
Activities happening in a video are the cause of temporal continuity, e.g., running person, falling object,
即事件的发生应该是一系列的时间连续性。
Therefore,we consider a data structure of streaming video activitiesX = {x1, x2, . . .}.
所以作者团队重新定义数据集,考虑一个流媒体视频活动的数据结构x={x1,x2,…}。
具体的定义可见下图:

需要注意的一点:对于异常检测任务,不需要明确地识别视频中的活动,从而将其与活动识别任务分开。
提出视频异常检测的挑战 ( meaningful and challenging)。
在有数据集的基础上,提出视频异常检测的挑战 ( meaningful and challenging)。
Two competing objectives make VAD a meaningful and challenging problem:raise an alarm as soon as possible when an anomalous activity takes place, and raise an alarm only when it is relevant.
当异常活动发生时,尽快发出警报,只有在相关时才发出警报。
关于新的异常检测指标:
Detection Delay: 就是分配检测延迟的参数δi=Ti−τi。

Alarm Precision: 是只在必要时进行报警,这等同于众所周知的二值分类的精度度量。最大化报警精度意味着最大化真实报警数/所有报警数的比率。
如图:如果警报j在异常活动的相关持续时间内发出,则为真正的警报, i.e., Tj+1 ∈ ∪[τi
, τi + δmax],其余的则视为假警报。
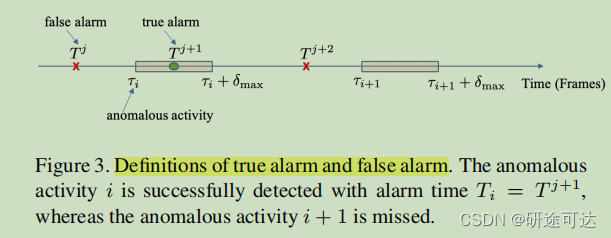
这个是报警精度的公式:

Average Precision Delay: In order to obtain a single metric for conveniently comparing VAD algorithms, we propose a new metric called Average Precision Delay (APD), which combines average detection delay and alarm precision。
平均检测延迟结合了检测延迟和报警精度。

Similar to the way the popular AUC metric summarizes TPR and FPR, APD measures the area under the Precision vs. normalized ADD (NADD) curve。
与流行的AUC度量总结TPR和FPR的方式相似,APD测量了精度与归一化ADD(NADD)曲线下的面积。
因此可以得出,较高的检测精度需要满足:
have high precision and low delay in its alarms.
APD值接近1的算法必须具有较高的精度和低延迟。
持续学习设置的目标是在每个训练分割k时一致地提高APD性能。

一个成功的连续VAD算法将通过更多的训练分割不断提高其APD性能。
3.2. Continual VAD Algorithm
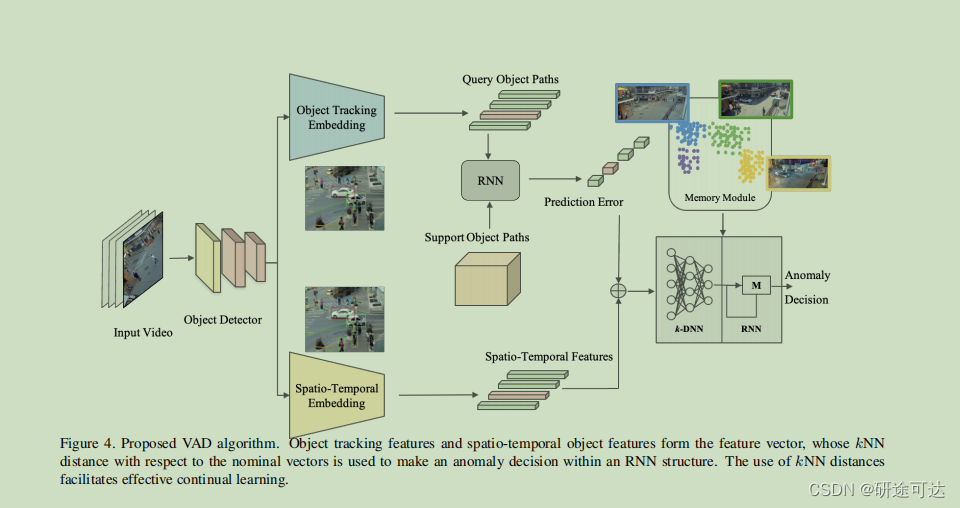
通过两阶段的方法处理持续学习来解决:首先使用端到端深度学习模型为每一帧提取低维特征嵌入,然后使用基于k-最近邻(kNN)的RNN模型来防止灾难性遗忘。
具体的措施有:
- 首先作者使用预先训练过的对象检测器来检测每一帧中的对象,如YOLO-v4[29]。然后,作者利用提取的边界框构建一个特征嵌入来表示在帧中观察到的时空活动( spatio-temporal
activities)。特别是,算法监视每个对象类检测到的对象数量、观察到的对象类的数量、每周的日期和视频帧所属的一天的时间。同时还将时间类型整体上分为周末和工作日、白天、晚上,借以在这个基础上去规划活动的异常归属类型。 - 其次、此外,从每个检测到的对象中提取更复杂的特征,作者也使用一种被称为DeepSORT的重新识别和跟踪算法(re-identification and tracking algorithm),它对每个检测到的对象进行实时路径跟踪。提取的对象路径被提供给一个RNN,以预测未来的路径。然后将所有对象路径的预测误差与时空特征一起叠加成一个特征向量。
- 紧接着、根据存储在存储器模块中的标称特征向量(nominal feature vectors)的集合,计算了特征向量的kNN距离。
To continually update k-DNN, we use experience replay, i.e., in addition to the most recent feature vector and its kNN value, previous feature vectors and kNN values are also used to update k-DNN.
4,Implementation Details:
- 对于kNN回归网络(k-DNN),作者使用一个全连接的深度神经网络,包含3个隐藏层,每层包含20个神经元。作者根据经验选择了最简单的网络,其预测误差明显较低。A single hidden layer LSTM
with a two input time steps is used for the decision RNN. - YOLO对象检测器在包含80个类的MS-COCO数据集上进行训练,而DeepSORT对象跟踪器在MOT16数据集上进行训练。For path prediction, an LSTM with three hidden layers with 20 input time steps is used.
- 作者删除了持续时间小于50帧的轨迹。所有的特征都使用训练后的最大值和最小值进行归一化为[0,1]。
- The entirepipeline is able to run at approximately 18 fps on a RTX 2070 GPU, which can be significantly improved by using a better GPU or more lightweight models.
5,实验结果:

作者按照可持续学习的算法框架,修改并测试了两个公开代码的算法,在新数据集上进行测试并得出了对比结果。可以看出,在持续学习的框架下,其APD精度随着训练批次逐渐升高,可见其可持续性起到的作用。
6,Conclusion
作者提出了一个新的框架和一个新的综合数据集的持续学习在视频异常检测。以及数据集和异常检测的新定义。作者还提出了一种新的视频异常检测器,能够连续学习和经验体验回放(both incrementally and through experience replay.)。
通过对所提出的NOLA数据集和可用的基准数据集的广泛测试,作者表明,所提出的算法在持续学习以及标准帧级AUC度量方面优于两种最先进的方法。
对于未来的工作,作者计划在多模态设置中利用音频和视频来提高检测性能(n leveraging audio and video in a multi-modal setup for improved detection performance.)。