这学期在上操作系统课,做了两次上机实验,都是与Fibonacci数列生成有关,且涉及到了两个重要的知识点——父子程序的建立与联系、共享内存的使用。在本篇博客中将两种方法具体讲解一下,为有需求的同志们提供参考。
目录
3、交互输入Fibonacci数列个数并进行父程序和子程序的创建
fork()概念理解
在讲解程序实现之前,还是要跟大家通一下fork()的概念,因为在和同辈人交流的时候发现大家对于这个概念还是有些模糊的,不少人不理解这个fork()到底是怎么fork()的,在此笔者用一个程序来演示一下。
int main(){
int a=5, b=7;
pid_t pid;
pid = fork(); /* fork another process */
if (pid < 0) { /* error occurred */
fprintf(stderr, "Fork Failed");
exit(-1);
}
else if (pid == 0) { /* child process */
a=a*2;
printf (“this is Child process, a=%d, b=%d\n”,a,b);
}
else { /* parent process */
printf (“this is parent process, a=%d, b=%d\n”,a,b);
wait (NULL);/* parent will wait for the child to complete */
a=a+1; b=b+3;
printf (“Child Complete, a=%d, b=%d\n”,a,b);
exit(0);
} }首先,父进程在创建子进程时必须首先定义一个pid_t类型的变量,在上述程序中我们将该变量命名为pid,该变量的作用在于——区分谁是父进程,谁是子进程。
fork()函数的功能在于创建一个子进程,同时返还一个pid_t类型的值,因此在上述程序中有
pid = fork();该操作将创建一个与父进程一模一样的进程,也就是我们说的子进程。此时,pid值就发挥作用了。
因为在父子进程中都有pid,那么——
如果pid为0,就说明该进程为子进程;如果pid不为0,而是某一个正整数,那么就说明该进程是父进程,该整数其实就是子进程的标识符,父进程需要获取子进程的标识符才能知道哪个是自己的儿子对吧(嘿嘿)。
确定好了pid的值之后,我们就可以按照程序中的分支语句进行运行了。子进程就运行pid = 0的代码段,父进程就运行pid > 0的代码段,按部就班地来。
此时!必须牢记一句话!——
子进程和父进程是两个独立的进程空间!
子进程和父进程是两个独立的进程空间!
子进程和父进程是两个独立的进程空间!
也就是说,子进程干子进程的任务,父进程干父进程的任务,两者互不影响。子进程的操作不会影响到父进程,生成的值也不会返还给父进程;同理,父进程的操作也不会影响到子进程。
对于父进程(标红段为父进程的运行代码):
int main(){
pid_t pid; int a=5, b=7;
pid = fork(); /* fork another process */
if (pid < 0) { /* error occurred */
fprintf(stderr, "Fork Failed");
exit(-1);
}
else if (pid == 0) { /* child process */
a=a*2;
printf (“this is Child process, a=%d, b=%d\n”,a,b);
}
else { /* parent process */
printf (“this is parent process, a=%d, b=%d\n”,a,b);
wait (NULL);/* parent will wait for the child to complete */
a=a+1; b=b+3;
printf (“Child Complete, a=%d, b=%d\n”,a,b);
exit(0);
}
}
父程序的运行代码中有一行代码为wait(NULL),该行操作的作用在于等待子程序的完成。也就是说,只有当子程序运行完毕后,父程序才会进行wait(NULL)语句之后的操作。
对于子进程(标红段为子进程的运行代码):
int main(){
pid_t pid; int a=5, b=7;
pid = fork(); /* fork another process */
if (pid < 0) { /* error occurred */
fprintf(stderr, "Fork Failed");
exit(-1);
}
else if (pid == 0) { /* child process */
a=a*2;
printf (“this is Child process, a=%d, b=%d\n”,a,b);
}
else { /* parent process */
printf (“this is parent process, a=%d, b=%d\n”,a,b);
wait (NULL);/* parent will wait for the child to complete */
a=a+1; b=b+3;
printf (“Child Complete, a=%d, b=%d\n”,a,b);
exit(0);
}
}
那么在wait(NULL)之前,子程序将会进行的操作是打印“this is Child process, a=10, b=7”,父进程将会进行的操作是打印“this is parent process, a=5, b=7”。
在这里我们需要注意——子进程和父进程打印的内容,在时间尺度上是不确定先后的。也就是说,可能父进程先打印,子进程后打印,也可能子进程打印,父进程后打印。
所以在这里程序运行会产生不同结果,差异就在打印的先后顺序上!
所以对于该程序来说,最终生成的结果会有三种:
- Fork Failed
- this is Child process, a=10, b=7
this is parent process, a=5, b=7
Child Complete, a=6, b=10
- this is parent process, a=5, b=7
this is Child process, a=10, b=7
Child Complete, a=6, b=10
总的来说,fork的考察点就是在于输出结果的差异,当然在实际运行的时候可能因为系统本身的性质确定了生成的顺序,所以最后输出的结果可能只有一种,但是这是实际系统运行的情况,我们在以上分析的是所有的可能情况,大家清楚即可。
之后就进入到代码环节啦~
(注意,代码需要在linux环境中编译生成,在vs中编译时,vs不包含某些头文件,无法编译,需要手动添加一些头文件,在这里不做展开,可以自行查阅博客)
父子程序fork()纯享版
此种方法借助fork()指令生成父子程序,在子程序中对Fibonacci数列进行生成和打印,父程序只需等待子程序的完成即可。
在实际实现的时候其实有多种方案可以选择,在这里简单列一下两个思路——
思路一:在main()函数外部定义函数进行父子程序的创建并且添加一个迭代,使得子程序创建自己的子程序,子程序的子程序在创建属于自己的子程序,层层嵌套,每个子程序只打印属于自己应该管辖的一个Fibonacci数。
思路二:预先定义一个全局变量vector<int>数组,只定义一个父程序,只生成一个子程序,子程序不断根据递推公式不断迭代生成Fibonacci数并存入全局变量的数组中,父程序将全局变量的数组打印出来即可。
好像第二种思路更容易想到一些,毕竟只有一对父子程序,结构上没有那么复杂;对于方法一来说,可能父子父子父子程序的层层嵌套有点绕,但是想明白之后还是挺有意思的(我一开始想的是第一种,后来才发现第二种思路,u1s1第二种真的要简单一些)。
思路一
-----------------------------------------------------简单描述----------------------------------------------------------------
在main()函数外部定义函数进行父子程序的创建并且添加一个迭代,使得子程序创建自己的子程序,子程序的子程序再创建属于自己的子程序,层层嵌套,每个子程序只打印属于自己应该管辖的一个Fibonacci数。
---------------------------------------------------------------------------------------------------------------------------------
我们需要确定的任务就是:
1、确定父程序应该干什么
2、确定子程序应该干什么
那么对于父程序来说,其实在该程序里真不需要干什么事,只需要等待子程序完成打印即可。
那么对于子程序来说,首先我们要得出自己要打印的Fibonacci数,并且打印出来,然后再进入到下一层嵌套中即可。
这种思路可能用语言不好描述,所以我们借助代码来看一看。
在该程序中,笔者在main()函数外部定义了一个函数ForkProcess,内容如下:
void ForkProcess(int n, int fib0, int fib1) {
//如果Fibonacci的级数小于三,就不需要再生成了,因为初始的两个Fibonacci数我们都已知.
if(n < 3) return;
else {
pid_t pid;
pid = fork();
if(pid < 0) {
cout << "Error! Fork Failed!" << endl;
exit(-1);
}
else if(pid == 0) {
int temp = fib1;
fib1 = fib1 + fib0;
fib0 = temp;//获取到该级子程序应该打印的Fibonacci数.
cout << fib1 << endl;
//再生成下一级子程序并打印Fibonacci数.
ForkProcess(--n, fib0, fib1);
}
else wait(NULL);//父程序的操作,等待子程序完成.
}
}该函数已经把生成Fibonacci数列的所有操作都做好了,我们唯一需要做的就是在main函数中引用该函数并且向其中传入级数n和初始的Fibonacci数列fib0和fib1。
大家可以对着上面的这一个函数进行剖析,理解嵌套和父子程序生成。
整体代码实现如下:
#include<iostream>
#include<sys/types.h>
#include<unistd.h>
#include<sys/wait.h>
using namespace std;
void ForkProcess(int n, int fib0, int fib1){};
//这里笔者偷个懒简写了一下,为了方便阅读main函数代码
//运行的时候把上面的代码copy过来就好
int main() {
cout << "请输入想要生成的Fibonacci数列的数字个数" << endl;
int n;
int fib0 = 0;
int fib1 = 1;
cout << "Fibonacci数列为:" << endl;
if(n == 1) {//如果级数为1,直接打印一个数然后退出程序
cout << fib0 << endl;
return 0;
}
else if(n == 2) {//如果级数为2,直接打印两个数然后退出程序
cout << fib0 << endl;
cout << fib1 << endl;
return 0;
}
else {//否则,运行ForkProgress程序
cout << fib0 << endl;
cout << fib1 << endl;
ForkProcess(n, fin0, fib1);
return 0;
}
}至此,思路一的第一种方案实现完毕,是不是感觉也还能吃透?当然笔者认为这个稍微有点难度,不太容易想到+吃透。所以我们不妨采用更简单的方法——思路二。
思路二
-----------------------------------------------------简单描述----------------------------------------------------------------
预先定义一个全局变量vector<int>数组,只定义一个父程序,只生成一个子程序,子程序不断根据递推公式不断迭代生成Fibonacci数并存入全局变量的数组中,父程序将全局变量的数组打印出来即可。
---------------------------------------------------------------------------------------------------------------------------------
这种方法只涉及到一对父子程序,比较好理解了吧~
首先明晰父进程干什么,子进程干什么
父进程——打印全局变量数组中的所有值
子进程——将生成的Fibonacci数存入到全局变量数组中
代码如下:
#include<iostream>
#include<sys/types.h>
#include<unistd.h>
#include<sys/wait.h>
#include<vector>
using namespace std;
vector<int> result;
int main() {
int fib0 = 0;
int fib1 = 1;
int n;
cout << "请输入想要生成的Fibonacci数列的级数:" << endl;
cin >> n;
//对两种特殊情况进行处理,即n=1和n=2的情况.
if(n == 1) {
cout << fib0 << endl;
return 0;
}
if(n == 2) {
cout << fib0 << endl;
cout << fib1 << endl;
return 0;
}
//如果n>3,则调用父子程序生成Fibonacci数列.
pid_t pid;
pid = fork();
if(pid < 0) {
cout << "Fork Failed" << endl;
return 0;
}
else if(pid == 0) {//子程序操作
result.push_back(fib0);
result.push_back(fib1);
while(n >= 3) {
//获取下一个Fibonacci数并将其放入数组
int temp = fib1;
fib1 = fib0 + fib1;
fib0 = temp;
result.push_back(fib1);
--n;
}
}
else {//父程序操作
wait(NULL);//等待子程序完成
int num = result.size();
for(int i = 0; i < num; i++) {
cout << result[i] << " ";//将所有Fibonacci数打印出来
}
cout << endl;
}
return 0;
}
这段代码中的重点在于子程序的操作,即不断使用fib0和fib1作为Fibonacci数列的生成中转站来生成数组,既减小了生成过程中的空间复杂度,又简单方便,大家可以学习一下这种思路。
至此,父子程序fork()纯享版代码就结束啦!
不懂之处大家多多留言交流,接下来分享共享内存的实现方法~
---------------------------------------------------------------------------------------------------------------------------------
其实中间真的托更了好久,一致没有更新这一部分内容,要不然这篇文章早就发出去了嘤嘤嘤,
接着来!
---------------------------------------------------------------------------------------------------------------------------------
共享内存版
题目描述大概是这样的:

读完题目描述我们应该清楚,这里只需要进行一次父子程序的创建就可以啦!
子程序负责将生成的对应个数的Fibonacci数列写入到共享内存中,而父程序负责将Fibonacci数列从共享内存中打印出来,题目结束!
所以,重点在于,如何进行共享内存的创建。
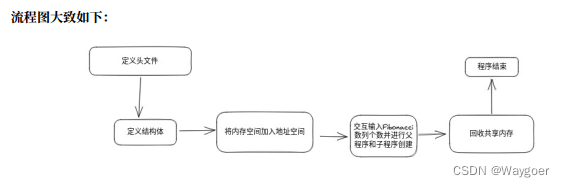
那么我们首先捋一下思路,有关共享内存的创建,大概分为以下几步:
1、定义结构体(目的在于明确父子程序的共享内存段的存储形式。如果存储形式就是简单的int类型或者char类型变量,那显然就不需要定义结构体啦~)
2、创建共享内存
- 创建共享内存的整数标识值(标序号,做标记)
- 将共享内存加入地址空间(做好标记再进入)
3、回收共享内存
- 从内存空间中分离共享内存段
- 彻底删除共享内存段
明确了大致的框架后,接下来我们来关注框架实现的具体细节就好啦,下面我会按照程序代码的实现顺序来一步一步地剖析代码思路——
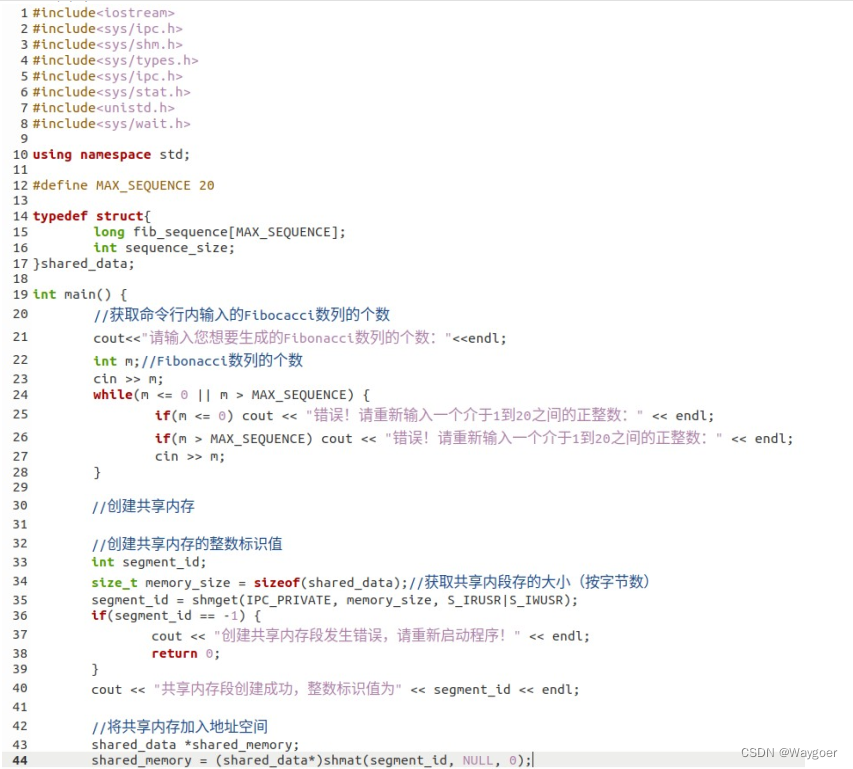
1、定义结构体
实现结构体即定义子程序与父程序的共享内存段的存储形式,在这里我们采用课本上给出的结构体形式进行实验。
typedef struct{
long fib_sequence[MAX_SEQUENCE];
int sequence_size;
}shared_data;其中,MAX_SEQUENCE预先定义为20,采用的命令为
#define MAX_SEQUENCE 202、创建共享内存
2.1 创建共享内存的整数标识值
涉及到的命令为
segment_id = shmget(IPC_PRIVATE, size, S_IRUSR | S_IWUSR)第一个参数指的是共享内存段关键字(标识符),若将其赋为IPC_PRIVATE,则生成一个新的共享内存段。第二个参数指的是共享内存段的大小(注意是按照字节数来算的大小,这里需要定义size_t类型的变量进行传参)。最后第三个参数用于标识模式,它明确了如何使用共享内存段,即用来读、用来写或者两者都包括。
该指令需要的头文件有
#include<sys/ipc.h>
#include<sys/shm.h>如果创建共享内存的整数标识值成功,则segmeng_id中会获取到shmget()函数返回的一个共享内存段整数标识值;如果失败,则返回-1。根据这一特性执行错误检查和报错提醒、处理。
2.2 将共享内存加入地址空间
涉及到的命令为
shared_memory = (变量类型强转)shmat(segment_id, NULL, 0); 该命令中划横线的部分根据具体情况进行调整。在这里我们需要在括号里填shared_data*,具体解释在于,如果 shmat()函数成功执行,则会返回一个指向附属的共享内存区域的内存中初始位置的指针,因为我们事先定义了共享内存为 shared_data类型,所以这里的指针强转为 shared_ data*类型,同理定义 shared_memory 时数据类型也规定为shared_data*。
在 shmat()函数中,调用需要三个参数——
- 第一个是希望加入的共享内存段的整数标识值,即segment _id;
- 第二个是内存中的一个指针位置,他表示将要加入的共享内存所在,如果传递一个值 NULL,操作系统则为用户选择位置(因而一般选择 NULL);
- 第三个参数表示一个标志,它指定加入到的共享内存区域是只读模式还是只写模式,通过传递一个参数 0,表示向共享内存区域进行读或写操作均可。
该命令创建所需的头文件有
#include <sys/types.h>
#include <sys/shm.h>同理,若失败则返回-1。根据这一性质执行错误检查和报错提醒、处理。
至此,共享内存创建完毕。
3、交互输入Fibonacci数列个数并进行父程序和子程序的创建
首先进行交互让程序运行者手动输入想要生成的数列的数字个数。
如果超出 1~MAX_SEQUENCE 的范围,则提示重新输入。定义 pid_t 类型的 pid 变量。
令 pid = fork()进行子程序的创建。
根据 pid 值进行父、子程序的判定——若为子程序,则 pid 值为 0;若为父程序,则 pid 值大于 0;若程序创建失败,则 pid 值为负。
子程序需要进行 Fibonacci 序列的生成并将内容写入共享内存中。父程序在子程序完成后将共享内存中的 Fibonacci 数列打印显示。
4、回收共享内存
4.1 从内存空间中分离共享内存段
涉及到的命令为:
shmdt(shared_memory)该命令需要的头文件有:
#include <sys/types.h>
#include <sys/shm.h>同理,若失败则返回-1。根据这一性质执行错误检查和报错提醒、处理。
4.2 彻底删除共享内存段
涉及到的命令为:
shmctl(segment_id, IPC_RMID, NULL);该命令涉及到的头文件有:
#include <sys/types.h>
#include <sys/shm.h>同理,若失败则返回-1。根据这一性质执行错误检查和报错提醒、处理。
至此,共享内存回收完毕。
有关共享内存的几个操作的详细信息,大家可以直接百度百科,真的很全面!
给来个传送门吧——https://baike.baidu.com/item/shmget/6875075
流程图
源代码
希望大家看明白思路之后能动手写一写,所以在这里我就浅浅贴一下图片了,哪怕照着敲一遍也比直接Ctrl+C、V来的好呀~



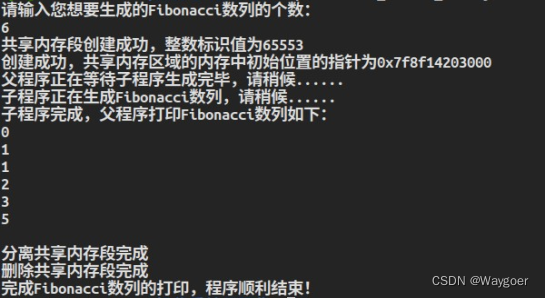
运行结果如下所示
(注意,代码无法在vs下运行,只能在linux环境下进行g++编译运行偶)
--------------------------------------------------------------------------------------------------------------------------------
总结
终于结束啦!
这一部分其实理解起来不难的,关键在于要练练手。明白fork的使用、父子程序的关系、共享内存的创建后,剩下的就是组织代码的问题啦!
大家有问题就来交流!之后我还会不定期的出一些操作系统有关的内容,欢迎大家关注!