表示人类造出的词:
(1)从语料中提取出含义表达。
(2)从文字到数值向量
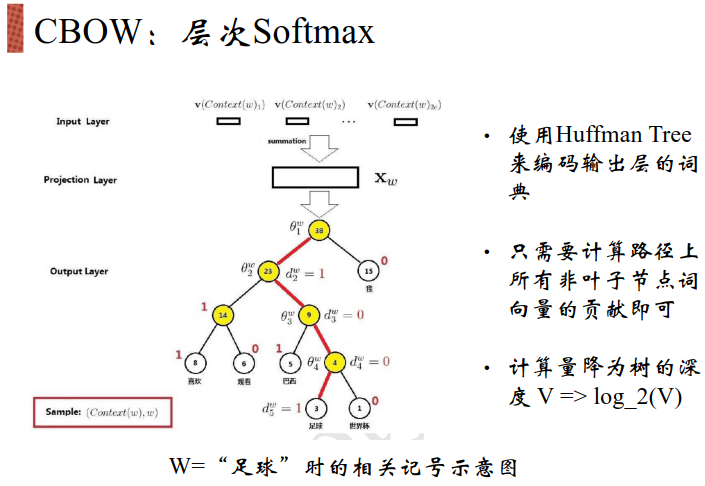
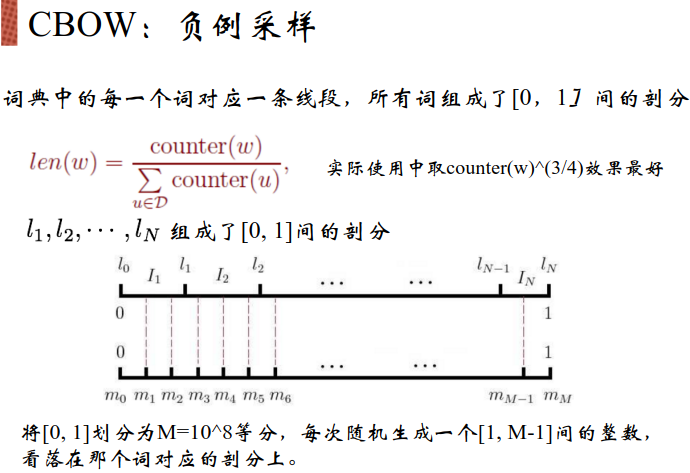
词编码的方式:N-gram,TF-IDF——Word2vec(对于多义词会转化到同一个数值向量,从而导致不准确)——sense2vec(区分在不同语境下某些单词的具体含义)
·


给每个词一个索引,每个词都编码一个下标,但是由于词与词之间有一些隐含的关系,这样做会破坏这个关系。近义词,同一类。
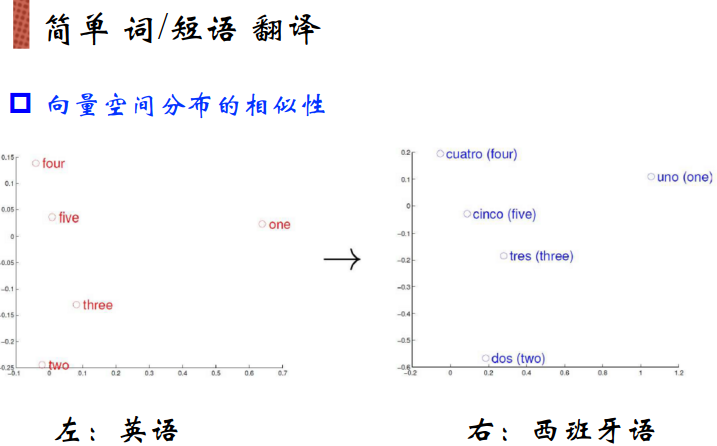
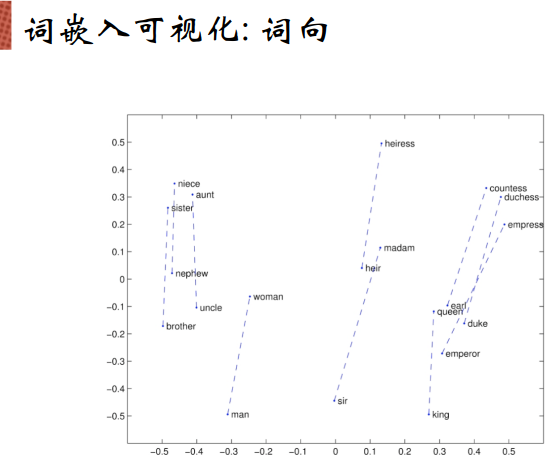
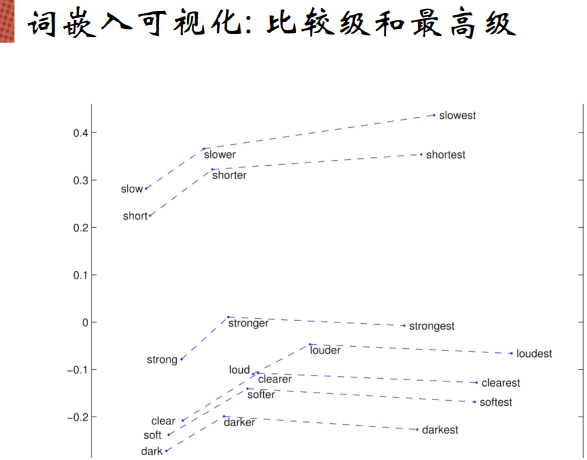
绘制到一个二维空间中,希望保证向量空间的相似度,即含义上相近的词绘制到二维空间中之后仍然是相近的。




词典:给每个不同的词一个下标
one-hot方法非常耗费内存,很稀疏的表示。数组会很长。
优化方法是只从这么多词当中取出最常用的几千个词,其余超出这些词的全部用一个下标来表示。

由于每个词在本文档中的重要性不一样。如果某个词在所有文档集合中出现频次都很高,那这个词可能就是一个烂大街的词。
但如果这个词仅仅是在本文档中出现高的话,那它就是很重要的一个词,需要适当利用TF-IDF来提高它的重要性。

语言模型:Bi-gram和N-gram


没有办法捕捉到背景知识,例如:词语之间的相近度。

由于句子结构都是这三个类型组成的,因此将乘法变加,大大减少了复杂度

计算机可以看很多文本,可能发现banking这个词老是和某些词一起出现,所有这个词可以用与它相近的词进行表示。

local window局域窗口
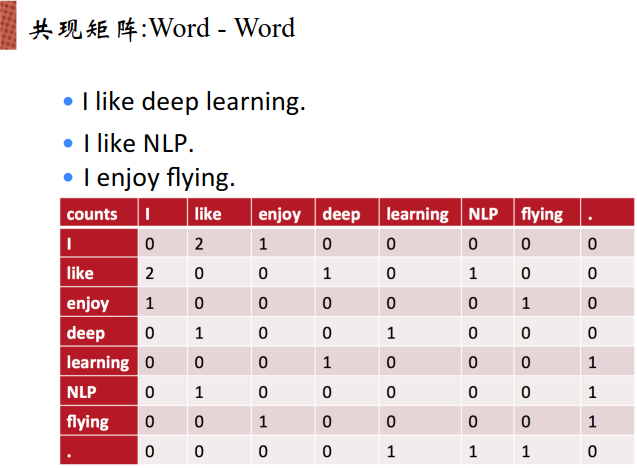
表中未计数。矩阵为对称矩阵。当列出共现矩阵的时候,可以通过某一行某一列进行表示。

欠稳定的原因:维度太高,太稀疏
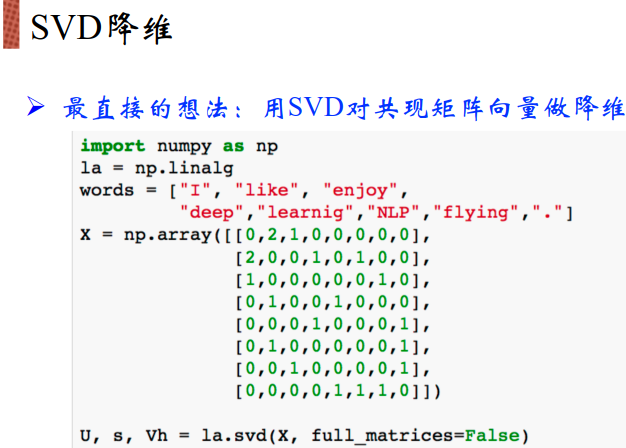
SVD会分解为三个矩阵,取前两个矩阵构成二维空间表示到2D图中:
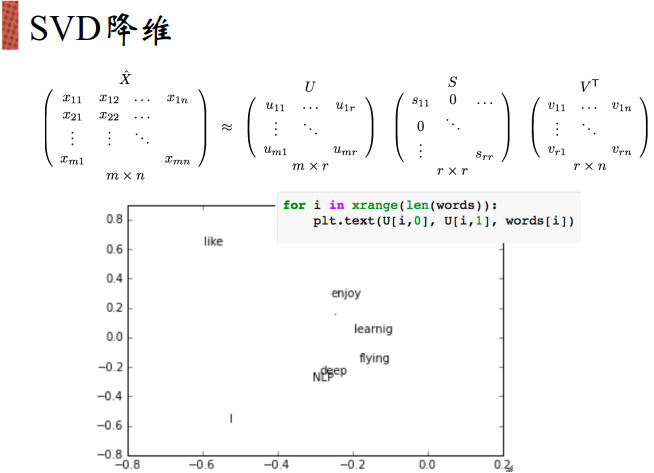
同样,随着语料库的增加,学习的文本数目越多,共现矩阵的维度也就越大。
此时依旧需要对词进行TF-IDF的词频统计,在周边的共现窗中只考虑高频词汇、有直接实际含义的、重要的词。
由于汉语本来丰富度就很高,如果说要挑选出几千个词就能表示所有常见词显然是一件很难很不实际的事情。
线性模型如果稀疏的话,如L2这一类的,由于这类模型的每个维度的输入会对最后的结果有一个共现。如果当前维度上的input会非常大,那最后结果影响肯定也会很大。
稀疏的坏处就是最后只会有几个有数值的位置会决定最后的结构

如果新加入了词的话,可能需要对共现矩阵重新全部做一遍统计。
DL是对原始特征进行变换然后做特征的抽取。SVD利用数学的方式进行降维不一定是DL想要的方式。
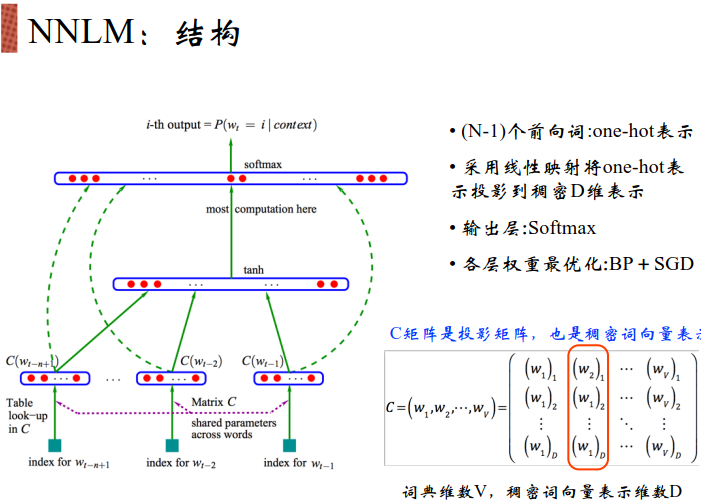
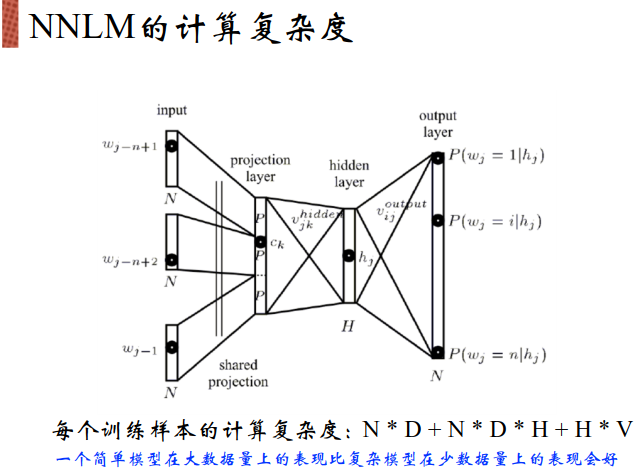
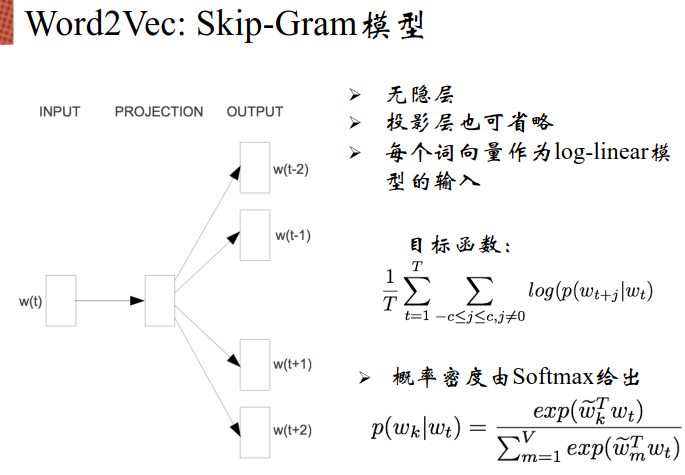
2003年提出了NNLM:

遍历整个语料库,将所有对的词都取出来,将所有正确的概率都加到一起,希望结果尽量大。