作者 | 王建周 编辑 | 汽车人
原文链接:https://zhuanlan.zhihu.com/p/607117094
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心【AIGC】技术交流群
一.前言
AIGC目前是一个非常火热的方向,DALLE-2,ImageGen,Stable Diffusion的图像在以假乱真的前提下,又有着脑洞大开的艺术性,以下是用开源的Stable Diffusion生成的一些图片。

这些模型后边都使用了Diffusion Model的技术,但是缺乏相关背景知识去单纯学习Diffusion Model门槛会比较高,不过沿着AE、VAE、CVAE、DDPM这一系列的生成模型的路线、循序学习会更好的理解和掌握,本文将从原理、数学推导、代码详细讲述这些模型。
二. AE (AutoEncoder)
AE模型作用是提取数据的核心特征(Latent Attributes),如果通过提取的低维特征可以完美复原原始数据,那么说明这个特征是可以作为原始数据非常优秀的表征。
AE模型的结构如下图

训练数据通过Encoder得到Latent,Latent再通过Decoder得到重建数据,通过重建数据和训练的数据差异来构造训练Loss,代码如下(本文所有的场景都是mnist,编码器和解码器都用了最基本的卷积网络):
class DownConvLayer(tf.keras.layers.Layer):
def __init__(self, dim):
super(DownConvLayer, self).__init__()
self.conv = tf.keras.layers.Conv2D(dim, 3, activation=tf.keras.layers.ReLU(), use_bias=False, padding='same')
self.pool = tf.keras.layers.MaxPool2D(2)
def call(self, x, training=False, **kwargs):
x = self.conv(x)
x = self.pool(x)
return x
class UpConvLayer(tf.keras.layers.Layer):
def __init__(self, dim):
super(UpConvLayer, self).__init__()
self.conv = tf.keras.layers.Conv2D(dim, 3, activation=tf.keras.layers.ReLU(), use_bias=False, padding='same')
# 通过UpSampling2D上采样
self.pool = tf.keras.layers.UpSampling2D(2)
def call(self, x, training=False, **kwargs):
x = self.conv(x)
x = self.pool(x)
return x
# 示例代码都是通过非常简单的卷积操作实现编码器和解码器
class Encoder(tf.keras.layers.Layer):
def __init__(self, dim, layer_num=3):
super(Encoder, self).__init__()
self.convs = [DownConvLayer(dim) for _ in range(layer_num)]
def call(self, x, training=False, **kwargs):
for conv in self.convs:
x = conv(x, training)
return x
class Decoder(tf.keras.layers.Layer):
def __init__(self, dim, layer_num=3):
super(Decoder, self).__init__()
self.convs = [UpConvLayer(dim) for _ in range(layer_num)]
self.final_conv = tf.keras.layers.Conv2D(1, 3, strides=1)
def call(self, x, training=False, **kwargs):
for conv in self.convs:
x = conv(x, training)
# 将图像转成和输入图像shape一致
reconstruct = self.final_conv(x)
return reconstruct
class AutoEncoderModel(tf.keras.Model):
def __init__(self):
super(AutoEncoderModel, self).__init__()
self.encoder = Encoder(64, layer_num=3)
self.decoder = Decoder(64, layer_num=3)
def call(self, inputs, training=None, mask=None):
image = inputs[0]
# 得到图像的特征表示
latent = self.encoder(image, training)
# 通过特征重建图像
reconstruct_img = self.decoder(latent, training)
return reconstruct_img
@tf.function
def train_step(self, data):
img = data["image"]
with tf.GradientTape() as tape:
reconstruct_img = self((img,), True)
trainable_vars = self.trainable_variables
# 利用l2 loss 来判断重建图片和原始图像的一致性
l2_loss = (reconstruct_img - img) ** 2
l2_loss = tf.reduce_mean(tf.reduce_sum(
l2_loss, axis=(1, 2, 3)
))
gradients = tape.gradient(l2_loss, trainable_vars)
self.optimizer.apply_gradients(zip(gradients, trainable_vars))
return {"l2_loss": l2_loss}通过AE模型可以看到,只要有有效的数据的Latent Attribute表示,那么就可以通过Decoder来生成新数据,但是在AE模型中,Latent是通过已有数据生成的,所以没法生成已有数据外的新数据。
所以我们设想,是不是可以假设Latent 符合一定分布规律,只要通过有限参数能够描述这个分布,那么就可以通过这个分布得到不在训练数据中的新Latent ,利用这个新Latent就能生成全新数据,基于这个思路,有了VAE(Variational AutoEncoder 变分自编码器)
三.VAE
VAE 中假设Latent Attributes (公式中用z)符合正态分布,也就是通过训练数据得到的z满足以下条件
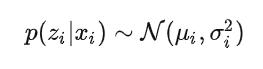
因为z是向量,所, 都是向量,分别为正态分布的均值和方差。有了学习得到正态分布的参数 ,那么就可以从这个正态分布中采样新的z,新的z通过解码器得到新的数据。
所以在训练过程中需要同时优化两点:
重建的数据和训练数据差异足够小,也就是生成x的对数似然越高,一般依然用L2 或者L1 loss;
, 定义的正态分布需要和标准正态分布的一致,这里用了KL散度来约束两个分布一致;
Loss公式定义如下,其中 q(x|z)和q(x)为生成分布, q(z|x) 为编码分布, q(z) 为从正态分布中采样的先验分布
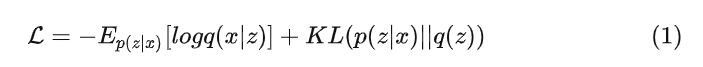
Loss的证明如下

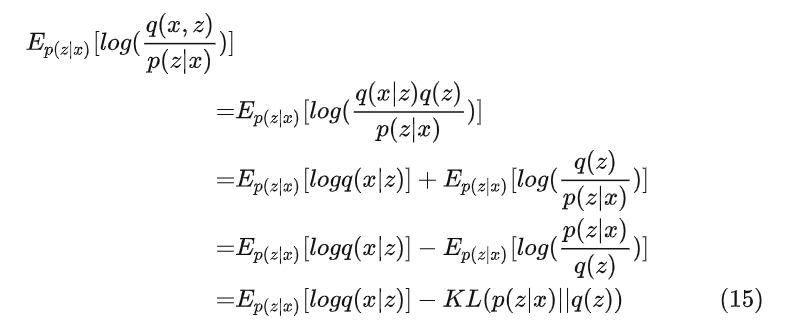
因为我们的目标是最大化对数似然生成分布q(x),也就是最小化负的公式15,也就是公式1的Loss
所以VAE的结构如下
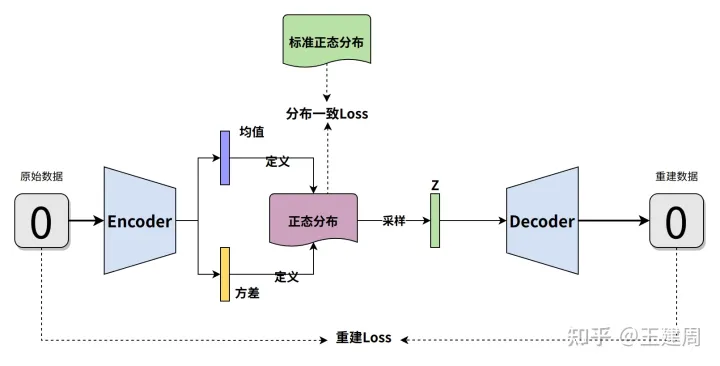
注意的是在上图中有一个采样z的操作,这个操作不可导导致无法对进行优化,所以为了反向传播优化,用到重参数的技巧,也就是将z表示成 , 的数学组合方式且该组合方式可导,组合公式如下
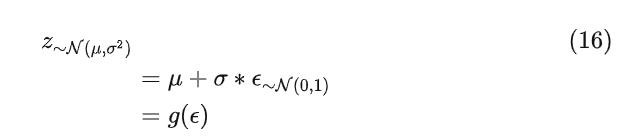
可以证明重参数后的模型f输出期望是不变的(z是连续分布)
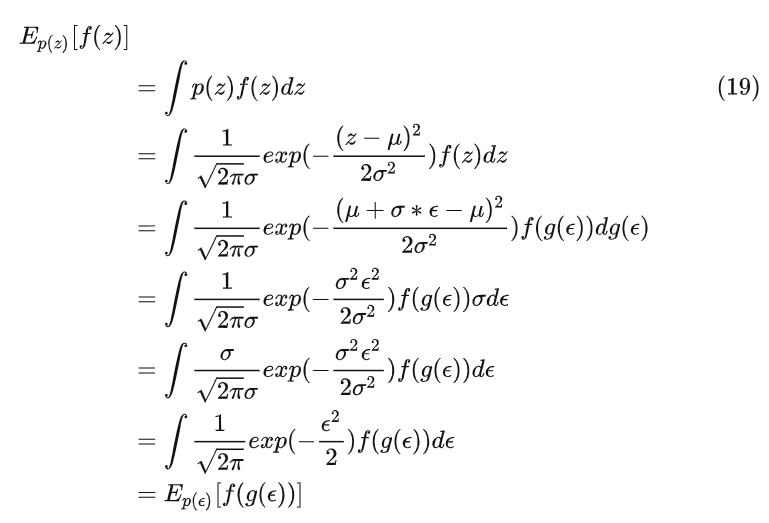
在计算 , 定义的正态分布和 , 定义的正态分布的KL散度时,用了数学推导进行简化
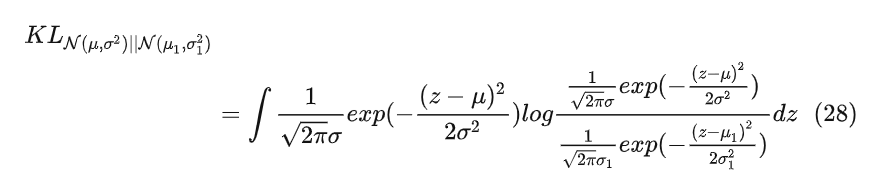
对公式28的log部分继续简化
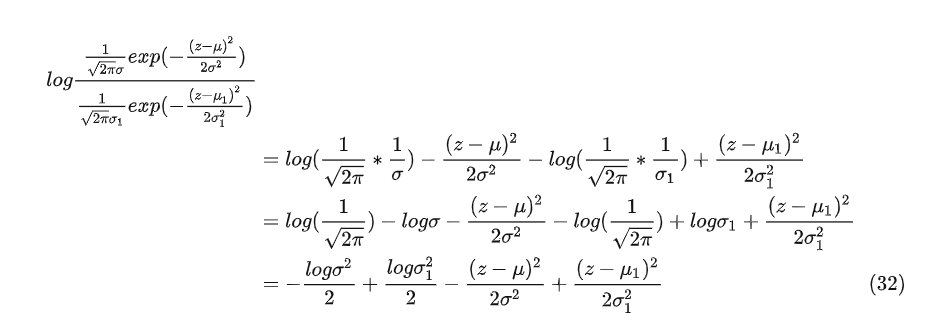
令
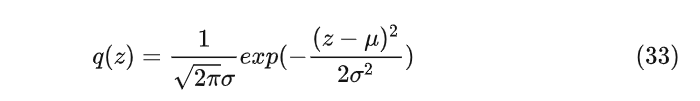
将公式32和33带入公式28得到
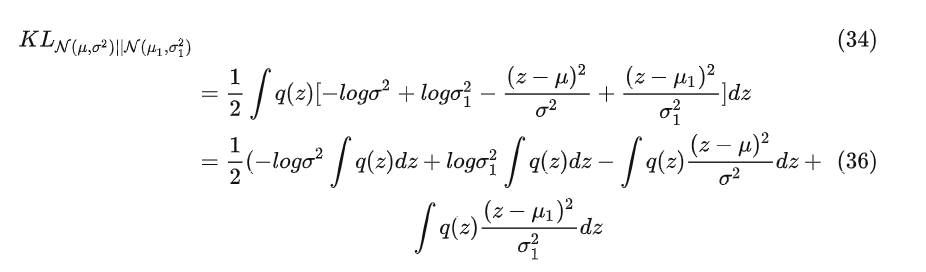
因为

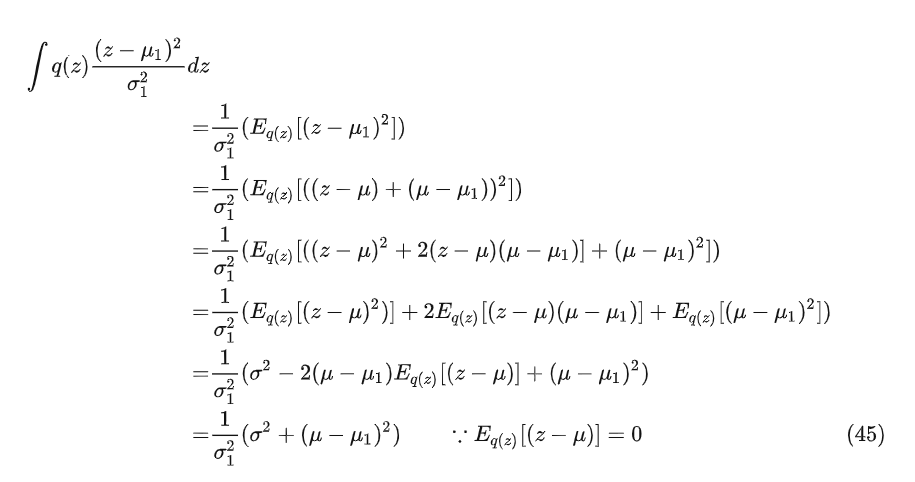
将公式37、38、45带入公式34得到最终的KL散度Loss公式
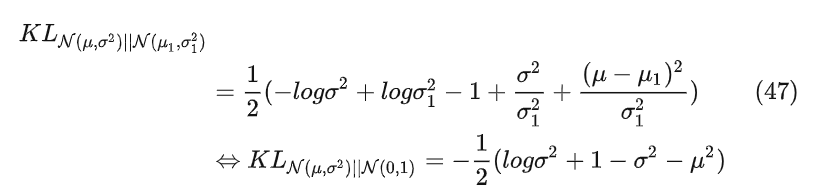
因为 非负,所以我们通过神经网络来学习 。
有了前边的铺垫,所以VAE的实现上也比较简单,代码如下
class VAEModel(tf.keras.Model):
def __init__(self, inference=False):
super(VAEModel, self).__init__()
self.inference = inference
self.encoder = Encoder(64, layer_num=3)
self.decoder = Decoder(64, layer_num=3)
# mnist 的size是28,这里为了简单对齐大小,缩放成了32
self.img_size = 32
# z的维度
self.latent_dim = 64
# 通过全连接来学习隐特征z正态分布的均值
self.z_mean_mlp = tf.keras.Sequential(
[
tf.keras.layers.Dense(self.latent_dim * 2, activation="relu"),
tf.keras.layers.Dense(self.latent_dim, use_bias=False),
]
)
# 通过全连接来学习隐特征z正态分布的方差的对数log(o^2)
self.z_log_var_mlp = tf.keras.Sequential(
[
tf.keras.layers.Dense(self.latent_dim * 2, activation="relu"),
tf.keras.layers.Dense(self.latent_dim, use_bias=False),
]
)
# 通过全连接将z 缩放成上采样输入适配的shape
self.decoder_input_size = [int(self.img_size / (2 ** 3)), 64]
self.decoder_dense = tf.keras.layers.Dense(
self.decoder_input_size[0] * self.decoder_input_size[0] * self.decoder_input_size[1],
activation="relu")
def sample_latent(self, bs, image):
# 推理阶段的z直接可以从标准正态分布中采样,因为训练的decoder已经可以从标准高斯分布生成新的图片了
if self.inference:
z = tf.keras.backend.random_normal(shape=(bs, self.latent_dim))
z_mean, z_log_var = None, None
else:
x = image
x = self.encoder(x)
x = tf.keras.layers.Flatten()(x)
z_mean = self.z_mean_mlp(x)
z_log_var = self.z_log_var_mlp(x)
epsilon = tf.keras.backend.random_normal(shape=(bs, self.latent_dim))
'''
实现重参数采样公式17
u + exp(0.5*log(o^2))*e
=u +exp(0.5*2*log(o))*e
=u + exp(log(o))*e
=u + o*e
'''
z = z_mean + tf.exp(0.5 * z_log_var) * epsilon
return z, z_mean, z_log_var
def call(self, inputs, training=None, mask=None):
# 推理生成图片时,image为None
bs, image = inputs[0], inputs[1]
z, z_mean, z_log_var = self.sample_latent(bs, image)
latent = self.decoder_dense(z)
latent = tf.reshape(latent,
[-1, self.decoder_input_size[0], self.decoder_input_size[0], self.decoder_input_size[1]])
# 通过z重建图像
reconstruct_img = self.decoder(latent, training)
return reconstruct_img, z_mean, z_log_var
def compute_loss(self, reconstruct_img, z_mean, z_log_var, img):
# 利用l2 loss 来判断重建图片和原始图像的一致性
l2_loss = (reconstruct_img - img) ** 2
l2_loss = tf.reduce_mean(tf.reduce_sum(
l2_loss, axis=(1, 2, 3)
))
# 实现公式48
kl_loss = -0.5 * (1 + z_log_var - tf.square(z_mean) - tf.exp(z_log_var))
kl_loss = tf.reduce_mean(tf.reduce_sum(kl_loss, axis=1))
total_loss = kl_loss + l2_loss
return {"l2_loss": l2_loss, "total_loss": total_loss, "kl_loss": kl_loss}
@tf.function
def forward(self, data, training):
img = data["img_data"]
bs = tf.shape(img)[0]
reconstruct_img, z_mean, z_log_var = self((bs, img), training)
return self.compute_loss(reconstruct_img, z_mean, z_log_var, img)
def train_step(self, data):
with tf.GradientTape() as tape:
result = self.forward(data, True)
trainable_vars = self.trainable_variables
gradients = tape.gradient(result["total_loss"], trainable_vars)
self.optimizer.apply_gradients(zip(gradients, trainable_vars))
return result生成的图片效果如下

在我们大多数生成场景,都需要带有控制条件,比如我们在生产手写数字的时候,我们需要明确的告诉模型,生成数字0的图片,基于这个需求,有了Conditional Variational AutoEncoder (CVAE)
四. CVAE
CVAE的改进思路比较简单,就是训练阶段的z同时由x和控制条件y决定,同时生成的x也是由y和z同时决定,Loss如下
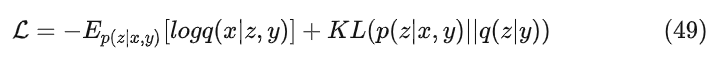
而q(z|y) 我们仍然期望符合标准正态分布,对VAE代码改动非常少,简单的实现方法就是对条件y有一个embedding表示,这个embedding表示参与到encoder和decoder的训练,代码如下
class CVAEModel(VAEModel):
def __init__(self, inference=False):
super(CVAEModel, self).__init__(inference=inference)
# 定义label的Embedding
self.label_dim = 128
self.label_embedding = tf.Variable(
initial_value=tf.keras.initializers.HeNormal()(shape=[10, self.label_dim]),
trainable=True,
)
self.encoder_y_dense = tf.keras.layers.Dense(self.img_size * self.img_size, activation="relu")
self.decoder_y_dense = tf.keras.layers.Dense(
self.decoder_input_size[0] * self.decoder_input_size[0] * self.decoder_input_size[1], activation="relu")
def call(self, inputs, training=None, mask=None):
# 推理生成图片时,image为None
bs, image, label = inputs[0], inputs[1], inputs[2]
label_emb = tf.nn.embedding_lookup(self.label_embedding, label)
label_emb = tf.reshape(label_emb, [-1, self.label_dim])
if not self.inference:
# 训练阶段将条件label的embedding拼接到图片上作为encoder的输入
encoder_y = self.encoder_y_dense(label_emb)
encoder_y = tf.reshape(encoder_y, [-1, self.img_size, self.img_size, 1])
image = tf.concat([encoder_y, image], axis=-1)
z, z_mean, z_log_var = self.sample_latent(bs, image)
latent = self.decoder_dense(z)
# 将条件label的embedding拼接到z上作为decoder的输入
decoder_y = self.decoder_y_dense(label_emb)
latent = tf.concat([latent, decoder_y], axis=-1)
latent = tf.reshape(latent,
[-1, self.decoder_input_size[0], self.decoder_input_size[0],
self.decoder_input_size[1] * 2])
# 通过特征重建图像
reconstruct_img = self.decoder(latent, training)
return reconstruct_img, z_mean, z_log_var
@tf.function
def forward(self, data, training):
img = data["img_data"]
label = data["label"]
bs = tf.shape(img)[0]
reconstruct_img, z_mean, z_log_var = self((bs, img, label), training)
return self.compute_loss(reconstruct_img, z_mean, z_log_var, img)
def train_step(self, data):
with tf.GradientTape() as tape:
result = self.forward(data, True)
trainable_vars = self.trainable_variables
gradients = tape.gradient(result["total_loss"], trainable_vars)
self.optimizer.apply_gradients(zip(gradients, trainable_vars))
return result生成0~9的图片效果如下

从VAE的原理可以看到,我们做了假设p(z|x)~N(, ) ,但是在大多数场景,这个假设过于严苛,很难保证数据特征符合基本的正态分布(严格意义上也做不到,严格分布的话说明特征就是高斯噪声了),因为这个缺陷,所以基本的VAE生成的图像细节不够,边缘偏模糊,为了解决这些问题,又出现DDPM(Denoising Diffusion Probabilistic Model),因为DDPM相比GAN,更容易训练(GAN需要交替训练,而且容易出现模式崩塌,可以参考我们以前的博客 https://mp.weixin.qq.com/s/Z-twmXHdIlUJ_FS99lx-7Q ),此外DDPM的多样性相比GAN更好(GAN因为生成的图像要“欺骗”过鉴别器,所以生成的图像和训练集合的真实图像类似),所以最近DDPM成为最受欢迎的生成模型。
五.DDPM
DDPM 启发点来自非平衡热力学,系统和环境之间有着物质和能量交换,比如在一个盛水的容器中滴入一滴墨水,最终墨水会均匀的扩散到水中,但是如果扩散的每一步足够小,那么这一步就可逆。所以主要流程上分两个阶段,前向加噪和反向去噪,原始数据为 ,每一步添加足够小的高斯噪声,经过足够的step T后,最终数据 会变成标准的高斯噪声(下图的q),因为前向加噪上是可行的,所以我们假设反向去噪也是可行的,可以逐步的从噪声中一点点的恢复数据的有用信息(下图的p)直到为 ,下边将详细介绍两部分
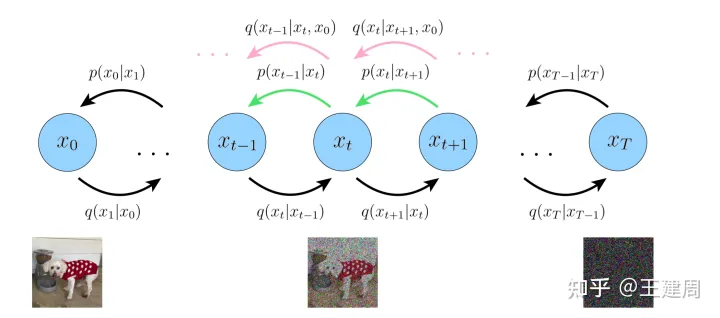
1.前向加噪
假设前向加噪过程每一步添加噪声的过程符合以下高斯分布,且整个过程满足马尔科夫链,即以下公式
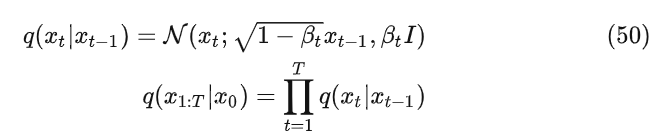
根据上文提到的重参数技巧,公式50可以写成(为了方便,写成标量形式)
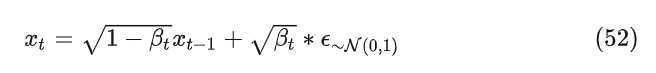
其中 0<<<<...<<1 ,所以公式52可以理解为向原始的数据设中加非常小的高斯噪音,并且随着t变大加的噪音逐渐变大,为了方便公式推导,令
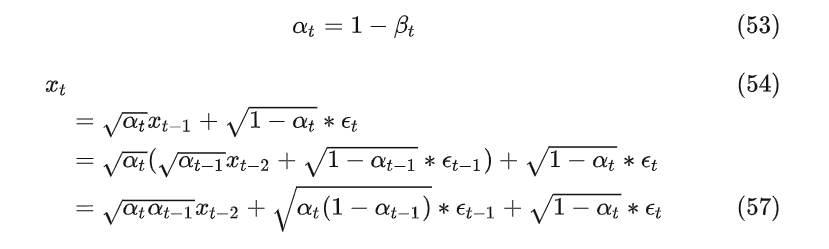
因为
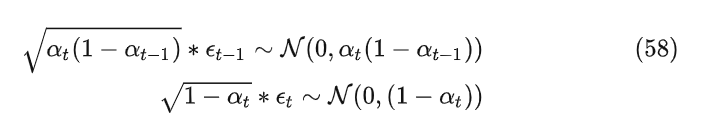
根据正态分布的求和计算公式以及重参数技巧
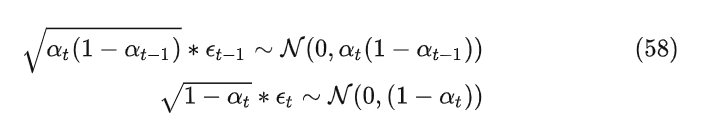
公式64就是正向过程的最终公式,可以看到正向过程是不存在任何网络参数的,而且对于给定的t,无需迭代,通过表达式可以直接计算得到。
2.反向去噪
反向去噪期望从标准的高斯分布噪声逐步的消除噪音,每次只恢复目标数据的一点点,最终生成目标数据 ,假设的反向去噪也是符合高斯分布和马尔科夫链,可以用以下数学公式描述
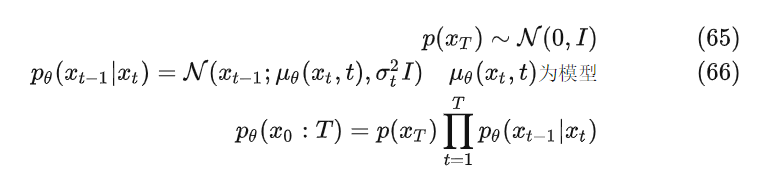

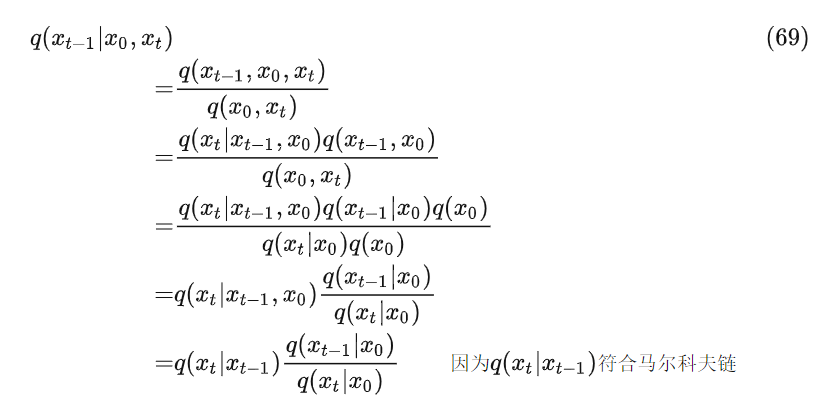
带入各自的表达式
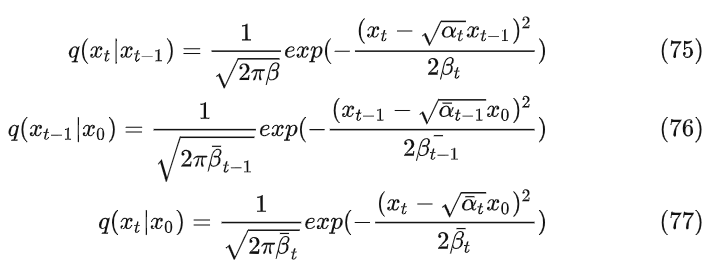
得到
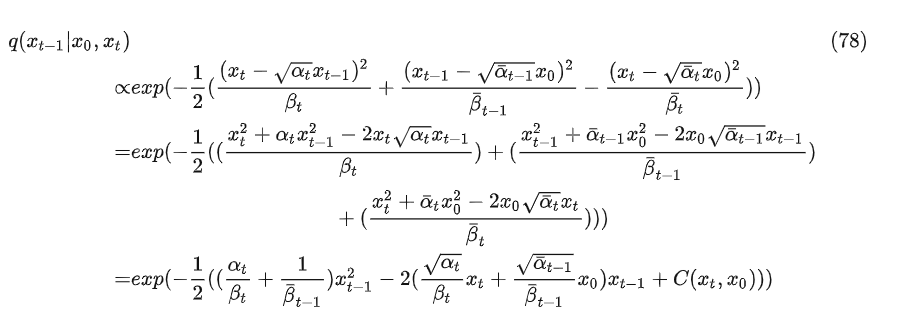
对比正态分布公式
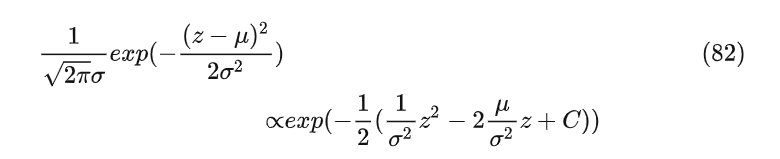



接下来我们需要推导下优化的目标,根据前边公式10的推导有以下
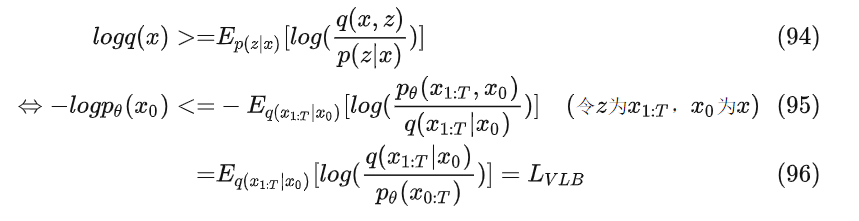
因为
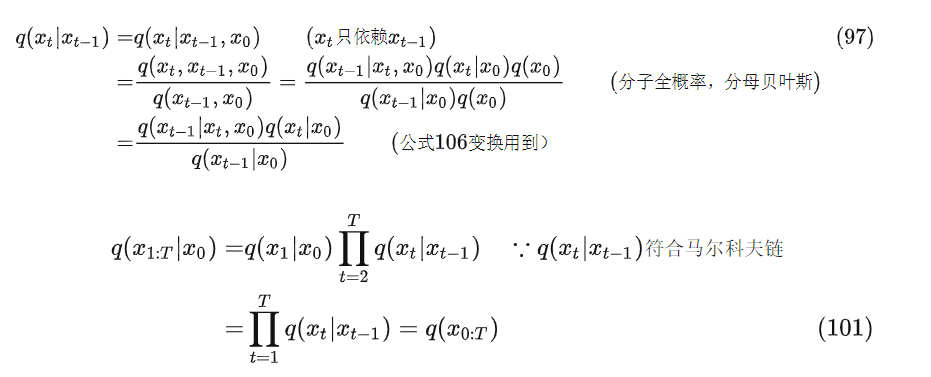
公式101代入公式96得到
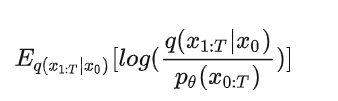
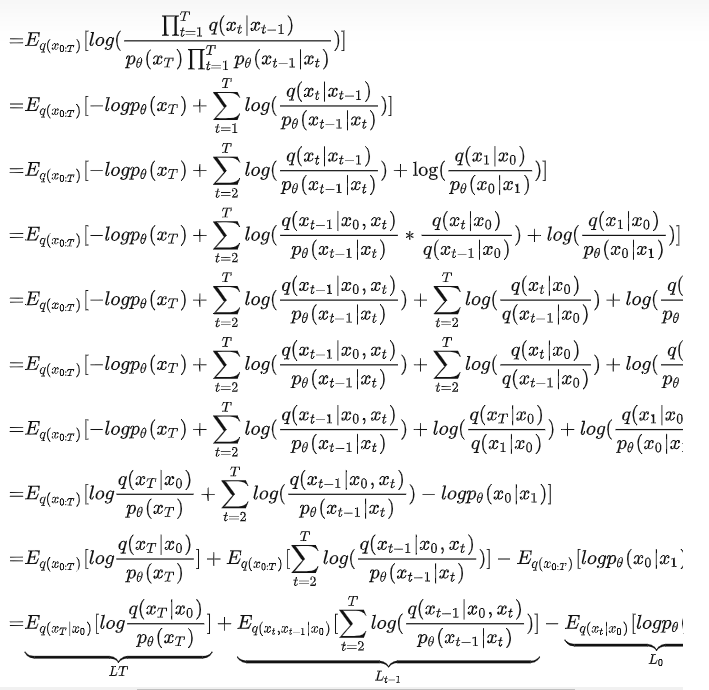
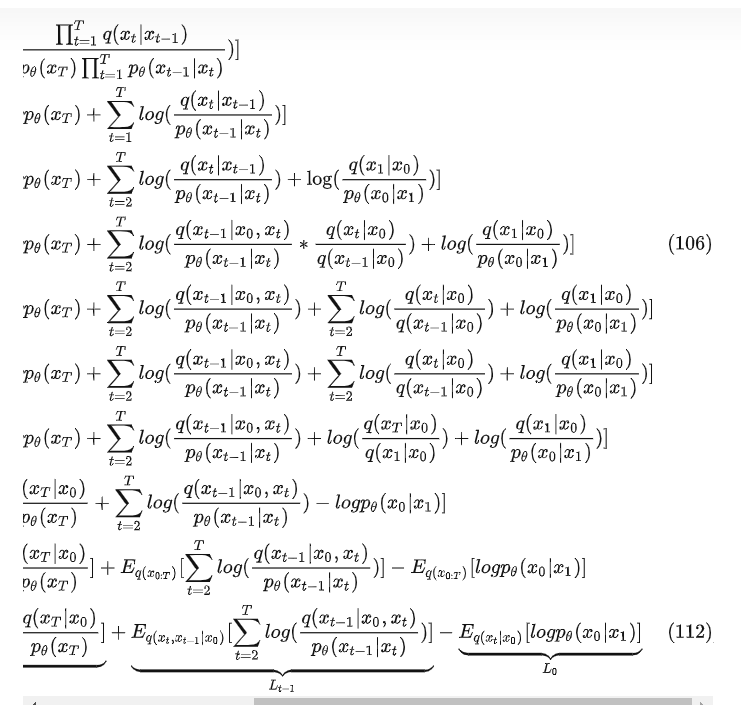
对112的 ,, 继续推导
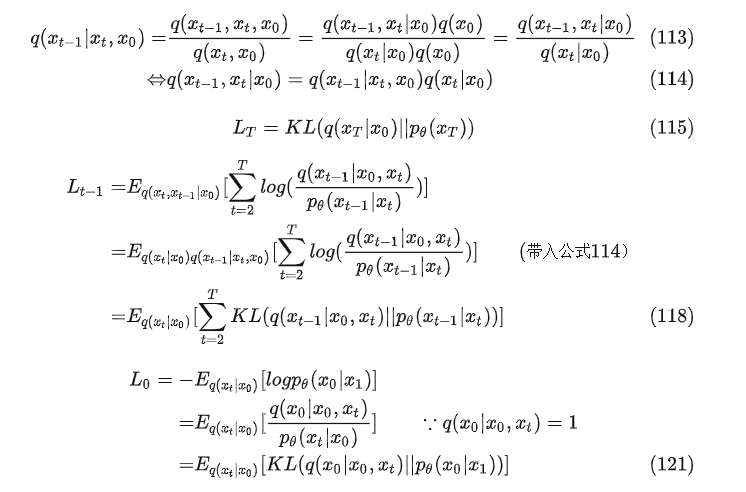

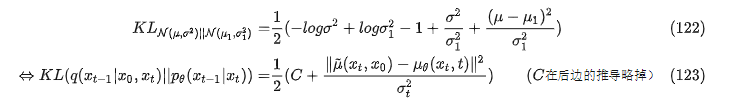
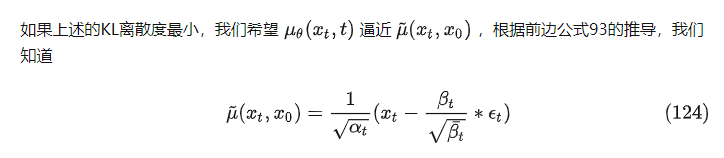

所以KL散度(公式122)变成一下公式
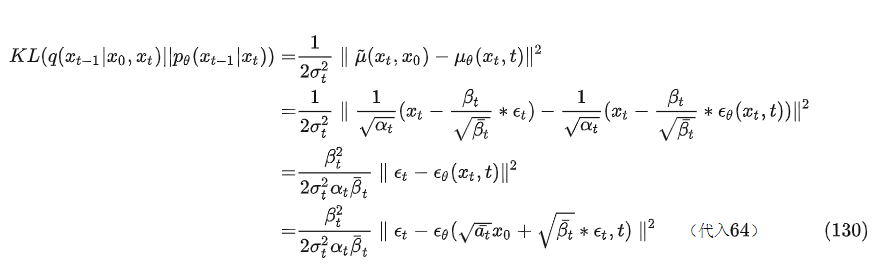

所以训练过程如下

从公式66和126,以及重参数技巧可以得知
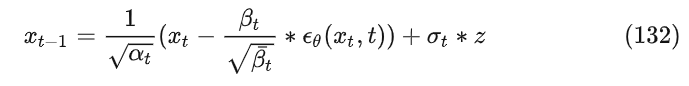
所以等待训练完成得到后,循环执行公式132就得到了最终的目标数据 ,过程如下


为了简化代码,我们去掉常见实现方式的self-attention;
一般时间步t也会采用transformer中基本的sincos的position编码,为了简化编码,我们的时间编码直接采用可以学习网络并只加入Unet的编码阶段,解码阶段不加入;
相比前边的VAE代码,这里的代码相对复杂,卷积模块采用Resnet的残差处理方式(经过实验,前边VAE基本的编码器和解码器过于简单,没法收敛)
参照官方,用group norm 代替 batch norm
class ConvResidualLayer(tf.keras.layers.Layer):
def __init__(self, filter_num):
super(ConvResidualLayer, self).__init__()
self.conv1 = tf.keras.layers.Conv2D(filter_num, kernel_size=1, padding='same')
# import tensorflow_addons as tfa
self.gn1 = tfa.layers.GroupNormalization(8)
self.conv2 = tf.keras.layers.Conv2D(filter_num, kernel_size=3, padding='same')
self.gn2 = tfa.layers.GroupNormalization(8)
self.act2 = tf.keras.activations.swish
def call(self, inputs, training=False, *args, **kwargs):
residual = self.conv1(inputs)
x = self.gn1(residual)
x = tf.nn.swish(x)
x = self.conv2(x)
x = self.gn2(x)
x = tf.nn.swish(x)
out = x + residual
return out / 1.44
class SimpleDDPMModel(tf.keras.Model):
def __init__(self, max_time_step=100):
super(SimpleDDPMModel, self).__init__()
# 定义ddpm 前向过程的一些参数
self.max_time_step = max_time_step
# 采用numpy 的float64,避免连乘的精度失准
betas = np.linspace(1e-4, 0.02, max_time_step, dtype=np.float64)
alphas = 1.0 - betas
alphas_bar = np.cumprod(alphas, axis=0)
betas_bar = 1.0 - alphas_bar
self.betas, self.alphas, self.alphas_bar, self.betas_bar = tuple(
map(
lambda x: tf.constant(x, tf.float32),
[betas, alphas, alphas_bar, betas_bar]
)
)
filter_nums = [64, 128, 256]
self.encoders = [tf.keras.Sequential([
ConvResidualLayer(num),
tf.keras.layers.MaxPool2D(2)
]) for num in filter_nums]
self.mid_conv = ConvResidualLayer(filter_nums[-1])
self.decoders = [tf.keras.Sequential([
tf.keras.layers.Conv2DTranspose(num, 3, strides=2, padding="same"),
ConvResidualLayer(num),
ConvResidualLayer(num),
]) for num in reversed(filter_nums)]
self.final_conv = tf.keras.Sequential(
[
ConvResidualLayer(64),
tf.keras.layers.Conv2D(1, 3, padding="same")
]
)
self.img_size = 32
self.time_embeddings = [
tf.keras.Sequential(
[
tf.keras.layers.Dense(num, activation=tf.keras.layers.LeakyReLU()),
tf.keras.layers.Dense(num)
]
)
for num in filter_nums]
# 实现公式 64 从原始数据生成噪音图像
def q_noisy_sample(self, x_0, t, noisy):
alpha_bar, beta_bar = self.extract([self.alphas_bar, self.betas_bar], t)
sqrt_alpha_bar, sqrt_beta_bar = tf.sqrt(alpha_bar), tf.sqrt(beta_bar)
return sqrt_alpha_bar * x_0 + sqrt_beta_bar * noisy
def extract(self, sources, t):
bs = tf.shape(t)[0]
targets = [tf.gather(source, t) for i, source in enumerate(sources)]
return tuple(map(lambda x: tf.reshape(x, [bs, 1, 1, 1]), targets))
# 实现公式 131,从噪声数据恢复上一步的数据
def p_real_sample(self, x_t, t, pred_noisy):
alpha, beta, beta_bar = self.extract([self.alphas, self.betas, self.betas_bar], t)
noisy = tf.random.normal(shape=tf.shape(x_t))
# 这里的噪声系数和beta取值一样,也可以满足越靠近0,噪声越小
noisy_weight = tf.sqrt(beta)
# 当t==0 时,不加入随机噪声
bs = tf.shape(x_t)[0]
noisy_mask = tf.reshape(
1 - tf.cast(tf.equal(t, 0), tf.float32), [bs, 1, 1, 1]
)
noisy_weight *= noisy_mask
x_t_1 = (x_t - beta * pred_noisy / tf.sqrt(beta_bar)) / tf.sqrt(alpha) + noisy * noisy_weight
return x_t_1
# unet 的下采样
def encoder(self, noisy_img, t, data, training):
xs = []
for idx, conv in enumerate(self.encoders):
noisy_img = conv(noisy_img)
t = tf.cast(t, tf.float32)
time_embedding = self.time_embeddings[idx](t)
time_embedding = tf.reshape(time_embedding, [-1, 1, 1, tf.shape(time_embedding)[-1]])
# time embedding 直接相加
noisy_img += time_embedding
xs.append(noisy_img)
return xs
# unet的上采样
def decoder(self, noisy_img, xs, training):
xs.reverse()
for idx, conv in enumerate(self.decoders):
noisy_img = conv(tf.concat([xs[idx], noisy_img], axis=-1))
return noisy_img
@tf.function
def pred_noisy(self, data, training):
img = data["img_data"]
bs = tf.shape(img)[0]
noisy = tf.random.normal(shape=tf.shape(img))
t = data.get("t", None)
# 在训练阶段t为空,随机生成成t
if t is None:
t = tf.random.uniform(shape=[bs, 1], minval=0, maxval=self.max_time_step, dtype=tf.int32)
noisy_img = self.q_noisy_sample(img, t, noisy)
else:
noisy_img = img
xs = self.encoder(noisy_img, t, data, training)
x = self.mid_conv(xs[-1])
x = self.decoder(x, xs, training)
pred_noisy = self.final_conv(x)
return {
"pred_noisy": pred_noisy, "noisy": noisy,
"loss": tf.reduce_mean(tf.reduce_sum((pred_noisy - noisy) ** 2, axis=(1, 2, 3)), axis=-1)
}
# 生成图片
def call(self, inputs, training=None, mask=None):
bs = inputs[0]
x_t = tf.random.normal(shape=[bs, self.img_size, self.img_size, 1])
for i in reversed(range(0, self.max_time_step)):
t = tf.reshape(tf.repeat(i, bs), [bs, 1])
p = self.pred_noisy({"img_data": x_t, "t": t}, False)
x_t = self.p_real_sample(x_t, t, p["pred_noisy"])
return x_t
def train_step(self, data):
with tf.GradientTape() as tape:
result = self.pred_noisy(data, True)
trainable_vars = self.trainable_variables
gradients = tape.gradient(result["loss"], trainable_vars)
self.optimizer.apply_gradients(zip(gradients, trainable_vars))
return {"loss": result["loss"]}
def test_step(self, data):
result = self.pred_noisy(data, False)
return {"loss": result["loss"]}生成的图片如下

类似CVAE,使用DDPM的时候,我们依然希望可以通过条件控制生成,如前边提到的DALLE-2,Stable Diffusion都是通过条件(文本prompt)来控制生成的图像,为了实现这个目的,就需要采用Conditional Diffusion Model。
六.Conditional Diffusion Model
目前最主要使用的Conditional Diffusion Model 主要有两种实现方式,Classifier-guidance和Classifier-free,从名字也可以看出,前者需要一个分类器模型,后者无需分类器模型,下边讲简单推导两种的实现方案,并给出Classifier-free Diffusion Model的实现代码。
1.Classifier-guidance
参考前边的推导公式在无条件的模型下,我们需要优化;而在控制条件y下,我们需要优化的是,可以用贝叶斯进行以下的公式推导

从以下公式推导可以看出,我们需要一个分类模型,这个分类模型可以对前向过程融入噪音的数据很好的分类,在扩散模型求梯度的阶段,融入这个分类模型对当前噪音数据的梯度即可
2.Classifier-free
通过classifier-guidance的公式证明,我们很容易得到以下的公式推导
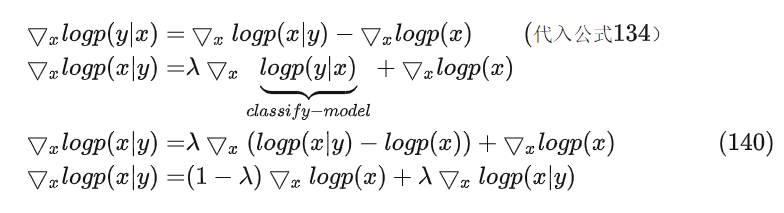
取值0~1之间,从公式140可以看出,只要我们在模型输入上,采样性的融入y就可以达到目标,所以在前边的DDPM代码上改动比较简单,我们对0~9这10个数字学习一个embedding表示,然后采样性的加入unet的encoder的阶段,代码如下
class SimpleCDDPMModel(SimpleDDPMModel):
def __init__(self, max_time_step=100, label_num=10):
super(SimpleCDDPMModel, self).__init__(max_time_step=max_time_step)
# condition 的embedding和time step的一致
self.condition_embedding = [
tf.keras.Sequential(
[
tf.keras.layers.Embedding(label_num, num),
tf.keras.layers.Dense(num)
]
)
for num in self.filter_nums]
# unet 的下采样
def encoder(self, noisy_img, t, data, training):
xs = []
mask = tf.random.uniform(shape=(), minval=0.0, maxval=1.0, dtype=tf.float32)
for idx, conv in enumerate(self.encoders):
noisy_img = conv(noisy_img)
t = tf.cast(t, tf.float32)
time_embedding = self.time_embeddings[idx](t)
time_embedding = tf.reshape(time_embedding, [-1, 1, 1, tf.shape(time_embedding)[-1]])
# time embedding 直接相加
noisy_img += time_embedding
# 获取 condition 的embedding
condition_embedding = self.condition_embedding[idx](data["label"])
condition_embedding = tf.reshape(condition_embedding, [-1, 1, 1, tf.shape(condition_embedding)[-1]])
# 训练阶段一定的概率下加入condition,推理阶段全部加入
if training:
if mask < 0.15:
condition_embedding = tf.zeros_like(condition_embedding)
noisy_img += condition_embedding
xs.append(noisy_img)
return xs
# 生成图片
def call(self, inputs, training=None, mask=None):
bs = inputs[0]
label = tf.reshape(tf.repeat(inputs[1], bs), [-1, 1])
x_t = tf.random.normal(shape=[bs, self.img_size, self.img_size, 1])
for i in reversed(range(0, self.max_time_step)):
t = tf.reshape(tf.repeat(i, bs), [bs, 1])
p = self.pred_noisy({"img_data": x_t, "t": t, "label": label}, False)
x_t = self.p_real_sample(x_t, t, p["pred_noisy"])
return x_t最终生成的图片如下

七.参考文献
https://www.jarvis73.com/2022/08/08/Diffusion-Model-1/
https://blog.csdn.net/qihangran5467/article/details/118337892
https://jaketae.github.io/study/vae/
https://pyro.ai/examples/cvae.html
https://lilianweng.github.io/posts/2021-07-11-diffusion-models/
https://spaces.ac.cn/archives/9164
https://zhuanlan.zhihu.com/p/575984592
https://kxz18.github.io/2022/06/19/Diffusion/
https://zhuanlan.zhihu.com/p/502668154
https://xyfjason.top/2022/09/29/%E4%BB%8EVAE%E5%88%B0DDPM/
https://arxiv.org/pdf/2208.1197
(一)视频课程来了!
自动驾驶之心为大家汇集了毫米波雷达视觉融合、高精地图、BEV感知、多传感器标定、传感器部署、自动驾驶协同感知、语义分割、自动驾驶仿真、L4感知、决策规划、轨迹预测等多个方向学习视频,欢迎大家自取(扫码进入学习)

(扫码学习最新视频)
视频官网:www.zdjszx.com
(二)国内首个自动驾驶学习社区
近1000人的交流社区,和20+自动驾驶技术栈学习路线,想要了解更多自动驾驶感知(分类、检测、分割、关键点、车道线、3D目标检测、Occpuancy、多传感器融合、目标跟踪、光流估计、轨迹预测)、自动驾驶定位建图(SLAM、高精地图)、自动驾驶规划控制、领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频,期待交流!

(三)【自动驾驶之心】全栈技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多传感器融合、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、产品经理、硬件配置、AI求职交流等方向;

添加汽车人助理微信邀请入群
备注:学校/公司+方向+昵称