一、读写文本格式的数据
1、整体读取文本文件
pandas提供了一些用于将表格型数据读取为DataFrame对象的函数。表6-1对它们进行了总结,其中read_csv和read_table可能会是你今后用得最多的。
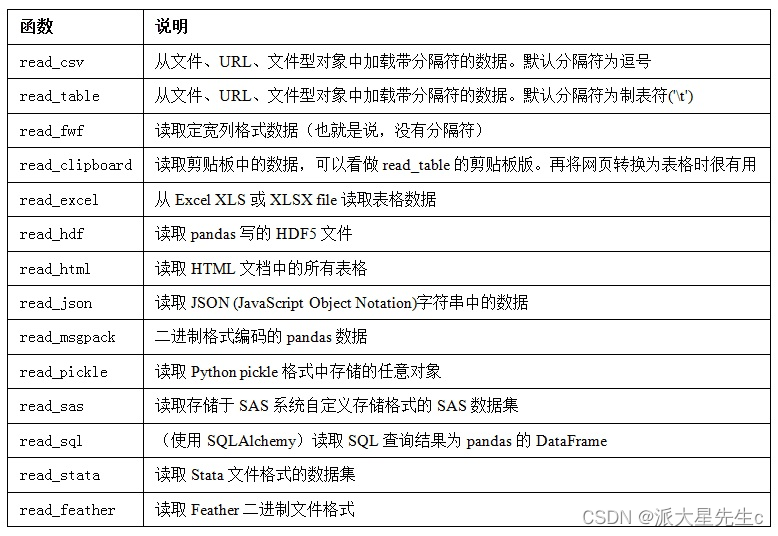
我将大致介绍一下这些函数在将文本数据转换为DataFrame时所用到的一些技术。
这些函数的选项可以划分为以下几个大类:
- 索引:将一个或多个列当做返回的DataFrame处理,以及是否从文件、用户获取列名。
- 类型推断和数据转换:包括用户定义值的转换、和自定义的缺失值标记列表等。
- 日期解析:包括组合功能,比如将分散在多个列中的日期时间信息组合成结果中的单个列。
- 迭代:支持对大文件进行逐块迭代。
- 不规整数据问题:跳过一些行、页脚、注释或其他一些不重要的东西(比如由成千上万个逗号隔开的数值数据)。
import pandas as pd
df = pd.read_csv('Food.csv')
df
#或者是用read_table 并指定分隔符
pd.read_table('Food.csv',sep=',')
如果希望将多个列做成一个层次化索引,只需传入由列编号或列名组成的列表即可

缺失值进行简单的处理
result = pd.read_csv('examples/ex5.csv', na_values=['NULL'])
#字典的各列可以使用不同的NA标记值
sentinels = {
'message': ['foo', 'NA'], 'something': ['two']}
pd.read_csv('examples/ex5.csv', na_values=sentinels)
常用选项



2、逐块读取文本文件
在处理很大的文件时,或找出大文件中的参数集以便于后续处理时,你可能只想读取文件的一小部分或逐块对文件进行迭代。
在看大文件之前,我们先设置pandas显示地更紧一些:
pd.options.display.max_rows = 10
如果只想读取几行(避免读取整个文件),通过nrows进行指定即可:
pd.read_csv('examples/ex6.csv',nrows=5)
要逐块读取文件,可以指定chunksize(行数):
chunker = pd.read_csv('ch06/ex6.csv', chunksize=1000)
3、将数据写出到文本格式
# 读取数据的前五行
data=pd.read_csv('Food.csv',nrows=5)
# 把他们生成一个新的csv文件
data.to_csv('out.csv')
# 更换分隔符
import sys
data.to_csv(sys.stdout,sep='|')
Series也有一个to_csv方法:
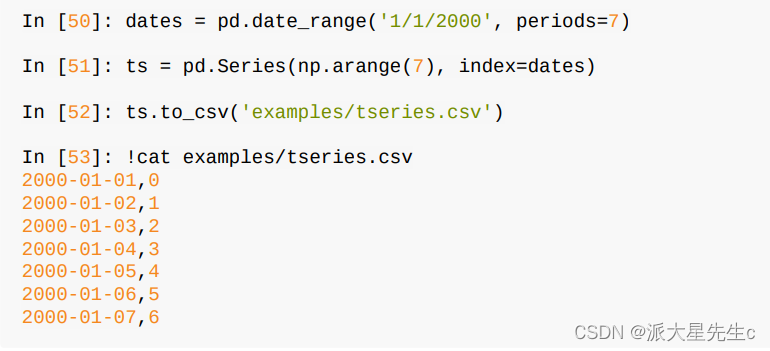
4、处理分隔符格式


二、读取Microsoft Excel文件
xlsx = pd.ExcelFile('examples/ex1.xlsx')
pd.read_excel(xlsx, 'Sheet1')
如果要读取一个文件中的多个表单,创建ExcelFile会更快,但你也可以将文件名传递到pandas.read_excel:
frame = pd.read_excel('examples/ex1.xlsx', 'Sheet1')
如果要将pandas数据写入为Excel格式,你必须首先创建一个ExcelWriter,然后使用pandas对象的to_excel方法将数据写入到其中:
writer = pd.ExcelWriter('examples/ex2.xlsx')
frame.to_excel(writer, 'Sheet1')
writer.save()
你还可以不使用ExcelWriter,而是传递文件的路径到to_excel:
frame.to_excel('examples/ex2.xlsx')
三、数据集交互
将数据从SQL加载到DataFrame的过程很简单,此外pandas还有一些能够简化该过程的函数。例如,我将使用SQLite数据库(通过Python内置的sqlite3驱动器):
import sqlite3
query = """
CREATE TABLE test
(a VARCHAR(20), b VARCHAR(20),
c REAL, d INTEGER
);"""
con = sqlite3.connect('mydata.sqlite')
con.execute(query)
con.commit()
插入数据
data = [('Atlanta', 'Georgia', 1.25, 6),
('Tallahassee', 'Florida', 2.6, 3),
('Sacramento', 'California', 1.7, 5)]
stmt = "INSERT INTO test VALUES(?, ?, ?, ?)"
con.executemany(stmt, data)
con.commit()
cursor = con.execute('select * from test')
rows = cursor.fetchall()
rows
这种数据规整操作相当多,你肯定不想每查一次数据库就重写一次。SQLAlchemy项目是一个流行的Python SQL工具,它抽象出了SQL数据库中的许多常见差异。
pandas有一个read_sql函数,可以让你轻松的从SQLAlchemy连接读取数据。这里,我们用SQLAlchemy连接SQLite数据库,并从之前创建的表读取数据:
import sqlalchemy as sqla
db = sqla.create_engine('sqlite:///mydata.sqlite')
pd.read_sql('select * from test', db)