自用
引用:http://dx.doi.org/10.1016/j.envsoft.2013.08.006
A stepwise cluster analysis approach for downscaled climate projection - A Canadian case study
Xiuquan Wang a, Guohe Huang a, b, *, Qianguo Lin b, c, Xianghui Nie a, Guanhui Cheng a, Yurui Fan a, Zhong Li a, Yao Yao a, Meiqin Suo c
降尺度技术用于获得高分辨率气候预测,以评估区域范围内气候变化的影响。本研究提出了一种基于逐步聚类分析方法的统计降尺度工具 SCAD。 SCDS 使用聚类树来表示大尺度大气变量(即预测变量)和局部地表变量(即预测变量)之间的复杂关系。它可以有效地处理连续变量和离散变量,以及预测变量和预测变量之间的非线性关系。通过集成缺失数据检测、相关性分析、模型校准和聚类树绘图等辅助功能模块,SCDS能够对当前和未来气候强迫下的局地天气变量进行降尺度情景的快速开发。应用 SCADS 得到了 2070-2099 年加拿大多伦多 10 公里的日平均气温和月降水预测。来自 NARR 的当代再分析数据用于模型校准(1981-1990)和验证(1991-2000)。然后应用经过验证的聚类树来生成未来的气候预测。
介绍:
可以从基于多种排放情景的全球气候模型 (GCM) 中获得对气候变化的未来预测。然而,为了评估区域尺度的气候变化影响,由于 GCM 和影响评估模型之间的空间分辨率不匹配,因此不能直接使用 GCM 的输出(Hashmi 等,2009;Willems 和 Vrac,2011)。通常,GCM 具有数百公里的空间分辨率,而影响分析则需要更精细的分辨率(几十公里甚至更小)。因此,近年来开发了降尺度技术来处理空间不匹配,作为改进 GCM 输出变量的区域或局部估计的替代方法(Hessami 等,2008)。根据对先前研究的回顾(Hewitson 和 Crane,1996;Wilby 和 Wigley,1997;Wilby 等,1998,2004;Murphy,1999;Mearns 等,2003),降尺度技术可以分为动态和统计。作为一种典型的动态降尺度方法,区域气候模型(RCM)不仅可以生成包含与物理机制一致的时空相关性的降水和温度时间序列,还有助于识别以前未观察到的样本外气候条件和机制。然而,RCM 很难快速生成大量可能的结果并经济高效地提供高分辨率的台站数据。相比之下,统计降尺度主要涉及发展大尺度大气变量(或
预测器)和局部表面变量(或预测器),这更容易实现,计算要求低得多(Wilby et al., 2004)。
因此,统计降尺度方法被广泛用于气候变化影响的研究(Heyen 等,1996;Maak 和 von Storch,1997;Beckmann 和 Adri Buishand,2002;Huth,2002;Wood 等,2004;Fowler 等。 , 2007; Timbal 等人, 2009; Hashmi 等人, 2011; Phatak 等人, 2011; Mullan 等人, 2012)。一般来说,统计降尺度方法可以分为三类:天气分类方案(如模拟方法、模糊分类、蒙特卡罗方法)、回归模型(如线性回归、随机模型、法术长度方法、混合建模)和天气生成器(如:例如神经网络、典型相关分析)。
相应地,最近开发了一些降尺度工具来促进气候变化影响研究。例如,威尔比等人。 (2002) 开发了一种基于回归的降尺度工具,称为 SDSM;赫萨米等人。 (2008) 提出了一种基于 SDSM 的自动统计降尺度 (ASD) 工具; Semenov 和 Barrow (1997) 开发了一种天气发生器模型,称为 Long Ashton 研究站天气发生器 (LARS-WG); Willems 和 Vrac (2011) 使用基因表达编程 (GEP) 开发了一种人工智能数据驱动模型,以创建符号缩减函数。
在这些降尺度方法中,它们中的大多数假设每个感兴趣的预测变量都是预测变量的函数。对于基于回归的模型尤其如此。但是,不能保证预测变量和预测变量之间必须存在这种函数关系。虽然我们可以通过减少变量数量或引入更多假设来约束地建立函数关系,但与 GCM 的粗略输出相比,它可能无法显着提高投影质量。
为此,本研究将提出一种基于逐步聚类分析的降尺度工具(SCADAS),该工具将预测变量和预测变量之间的复杂交互表示为聚类树,而不需要假设功能关系。所提出的缩减工具的灵感来自于 Huang (1992) 首次引入的逐步聚类分析 (SCA) 方法。
在过去几年中,SCA 已广泛应用于环境研究。
例如,黄等人。 (2006) 开发了一个基于 SCA 的支持修复设计和过程控制的预测系统;秦等人。 (2007) 应用 SCA 建立补救措施和系统响应之间的联系。
本研究的主要目的是开发一种基于 SCA 的降尺度工具,并测试其从 GCM 或 RCM 的粗略输出中获取更精细场景的能力。以下部分首先概述了 SCA 方法的基本原理、建模过程和软件实现。然后给出一个说明性示例,通过缩小 PRECIS(为影响研究提供区域气候)模型和由气象局开发的区域气候建模系统输出的 25 公里情景,获得 2070-2099 年加拿大多伦多的 10 公里高分辨率气候预测哈德利中心。最后一节阐述了SCDS应用方面的主要结论和建议及其局限性。
方法
SCA基本原理
SCA 的基本算法基于多元方差分析理论(Morrison,1967;Cooley 和 Lohnes,1971;Overall 和 Klett,1972)。在 SCA 中,因变量的样本集将根据给定的标准被切割或合并成新的集(即子簇),并以自变量的值作为参考来确定原始集中的样本是哪个新集(即父集群)将进入(Huang et al., 2006)。 SCA聚类树的构建需要多次切割和合并操作,这个过程实际上是将原始的因变量集合按照特定的标准划分为许多不相关的子集,这将在本节后面介绍。生成的聚类树可以表达预测变量和预测变量之间的复杂关系,它将用于预测预测变量的未来值,基于 Wilks 的 L 统计量的切割或合并操作(Wilks,1962),
定义为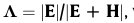
,其中 E 和 H 分别是组内和组间平方和和叉积矩阵。让两组因变量 e 和 f 包含 ne 和 nf 个样本,表示为以下向量:

其中 d 是 e 和 f 的维数。那么 H 和 E 可以由下式给出:

SCADS的发展
一般来说,获得缩小的气候预测的过程可以概括为四个步骤:
1)为每个感兴趣的预测变量筛选一组预测变量,这通常需要对每对预测变量和预测变量进行一些必要的相关性分析;
2)基于样本数据建立预测变量和预测变量之间的定量关系,在本研究中称为“训练”;
3) 验证已建立的与观测数据的关系,以评估其再现历史气候的性能;
4) 根据已建立的关系生成局地气候预测,
本研究将这一步称为“预测”。 SCDS 的发展路线图如图 1 所示。
训练过程的结果是一个可以处理连续和离散变量的聚类树,以及变量之间的非线性关系。该预测工作的输入主要来自 GCM 或 RCM 输出的大规模气候预测。 SCADS 是一个基于网络的降尺度工具,全世界任何国家的用户都可以通过 Internet 自由访问它。 SCDS 的用户需要注册一个帐户才能使用所有提供的功能。图 2 显示了 SCADAS 的主界面,用户可以通过该界面使用自己创建的帐户信息登录系统。为了避免托管 Web 服务器变慢并有效地管理所有降级请求,我们在 SCAD 的开发中采用了排队规则(即先到先得)来控制用户对计算资源和时间消耗的要求。 SCDS的主要功能将在以下章节中介绍。
3.1缺失数据检测
缺失数据几乎出现在所有严肃的统计分析中(Gelman 和 Hill,2006 年)。由于缺少数据而导致的不响应或不合理的结果可能会导致对研究目标的干扰。因此,有必要检查样本集合是否包含缺失数据,并明确其在时间序列和数据矩阵结构方面的分布,以便选择合适的方法来处理缺失数据。 SCDS 集成了缺失数据检测功能,可帮助用户了解缺失的元素数量以及这些缺失值在样本集合中的分布情况。如图 3 所示,原始数据集合包含四个缺失元素,用“NA”表示。缺少的概览面板由SCDS 给出了输入数据的可视化图,其中缺少的元素以红色突出显示(在网络版本中)。同时,SCDS 会输出一份缺失报告,包括详细的统计信息,例如缺失元素的总数、缺失的位置(行和列索引)。
3.2 相关性分析
相关性分析功能旨在帮助有效筛选一组预测变量,用于预测相应预测变量的值。在本研究中,我们使用相关系数(也称为 R)作为衡量每对预测变量和预测变量之间关联的标准。相关系数是衡量两个变量之间直线或线性关系强度的指标(Rodgers 和 Nicewander,1988 年),取值介于 1 和 1 之间。 þ 或 ?符号表示相关的方向。正号表示直接相关,而负号表示反相关。数字越接近 1,相关性越强。零表示没有相关性。因此,基于相关系数设计相关分析模块有两种基本方式:确定预测变量的预测能力和确定预测变量与其对应预测变量之间的相关性。图 4 显示了集成在当前版本的 SCDS 中的相关性分析模块的图示。计算出的相关系数值以不同的背景颜色突出显示(在网络版本中)。颜色从黄色(网页版)逐渐变为红色(网页版)表示相关系数的绝对值逐渐增加。通过单击每对预测变量和预测变量的相关系数值,将显示一个包含散点图的弹出窗口,有助于了解所有样本点的分布模式以及有效识别极值点。
3.3训练
训练过程是建立预测变量和预测变量之间的关系,并使用量化函数或其他形式来表示它。在 SCDS 中,可以通过创建训练作业来初始化和处理与训练相关的事务。预测变量和预测变量之间的复杂关系表示为聚类树。在当前版本的 SCDS 中创建训练作业需要三个步骤:
1)选择样本,
2)审核样本,
3)确认并提交。
建议用户在创建新的训练作业之前检查样本数据,并借助缺失数据检查和相关性分析模块。如果在没有任何预处理的情况下将具有缺失数据的样本输入到训练作业中,只要至少缺少一个元素,SCDS 就会消除整个数据行。创建新的培训作业时,将要求用户指定一个友好的名称来标识该作业。一项培训工作所消耗的总时间通常差异很大。通常,它取决于样本大小(即样本集合的总行数)、预测变量和预测变量的数量以及每对预测变量和预测变量的相关性。提交训练作业后,SCDS 将决定是否应立即启动。如果在此作业之前提交了一些作业,并且其中至少有一个正在等待或运行,则新作业将被添加到等待队列中。否则,它将立即开始运行。训练工作完成后,SCDS 将输出两个纯文本文件:treefile 和 mapfile,分别包括簇树路径和叶节点。
基于 Windows 的实用程序,即 SCDS Cluster Tree Generator (CTGV1.0),与 SCADAS 一起开发,方便训练过程输出的聚类树的可视化。 CTG V1.0主界面如图5所示。
3.4.校准
在校准过程中,模型的各个部分,包括输入值,都会发生变化,以使测量值(即观察值)与模拟值相匹配,目的是准确表示实际系统的重要方面(Hill, 1998 年)。在 SCDS 中,只有一个输入参数需要校准,即显着性水平 (a)。通常,它的初始值可以在 0.01 到 0.05 的范围内。显着性级别越高,模型越不敏感,生成的聚类树的叶节点越少。 SCDS 中的默认显着性水平为 0.05。但是,用户可以反复调整它,直到缩小的输出以可接受的准确度与样本预测匹配。
3.5验证
验证用于确定模型是否是真实系统的准确表示,这通常通过将模型与实际系统行为进行比较的迭代过程来实现(Kleijnen,1995;Bennett 等,2013)。 R平方(R2,决定系数)的使用在经典回归分析中得到了很好的证实(Rao,1973)。其定义为回归模型解释的方差比例,使其可用于衡量从自变量预测因变量的成功程度(Nagelkerke,1991)。因此,SCADAS 采用决定系数作为验证模型性能的关键标准。如图 6 所示,为每对预测和观察到的预测变量计算了许多 R 平方值。通过单击每个值,将显示一个包含预测与观察散点图的顶部窗口,以帮助直观地了解模型的性能。
3.6.预测
预测模块用于帮助用户基于经过验证的集群树开发高分辨率的缩小场景。创建预测作业的过程很简单。用户指定训练作业名称以及预测变量的输入数据。作为回报,SCDS 根据训练过程中的输出树和映射文件预测相应的预测变量。
4应用
SCDS 应用于加拿大多伦多市。 1981-2000 年期间的大规模预测变量来自北美区域再分析数据集 (NARR),该数据集最初由国家环境预测中心 (NCEP) 生成。 NARR 项目是 NCEP 全球再分析在北美的延伸。 NARR 模型使用了非常高分辨率的 NCEP Eta 模型(32 公里/45 层)以及区域数据同化系统 (RDAS),该系统显着地同化了降水和其他变量(Mesinger 和 Coauthors,2006;Saha 和 Coauthors,2010 )。然后将收集到的数据重新网格化到 PRECIS 模型的 25 公里网格中以进行预测。区域尺度的预测变量,如同一时期的日平均气温 (?C) 和月降水量 (mm),是从国家水土资源信息服务、农业和农业食品提供的 10 公里网格气候数据集中提取的,加拿大。网格化数据是通过 ANUSPLIN V4.3 (NLWIS, 2008) 实施的薄板平滑样条曲面拟合方法从加拿大环境部气候站每日观测数据中插值得到的。前十年数据(即 1981-1990)用于模型校准,其余十年数据(即 1991-2000)用于模型验证。其次,借助 SCAD 的相关性分析,从大量候选变量中筛选出一组有限的大规模预测变量。
表 1 列出了候选预测变量与日平均温度的相关系数和月降水量。粗体值表示为训练和预测过程选择的预测变量,表示预测变量和相应预测变量的最有希望的组合。筛选后的预测变量集被输入到训练过程中,以生成不同显着性水平(即 0.01、0.02、0.03、0.04 和 0.05)的聚类树。基于生成的聚类树再现了 1981-1990 年期间的日平均气温和月降水量结果。
表 2 显示了考虑 R 平方和均方根误差 (RMSE) 的不同显着性水平的校准结果。这表明在估算月降水量方面略有改进,同时数值从 0.01 增加到 0.05。当 ¼ 0.04 时,可以获得降水的最佳拟合结果,Rsquared 为 0.5279,RMSE 为 16.1787 mm。然而,选择不同的 a 水平不会显着影响日平均温度的拟合结果(R 平方为 0.9710 的恒定值),除了当 ¼ 0.05 时 RMSE 有非常轻微的改善。
因此,在此示例中,温度和降水的校准显着性水平将彼此不同;日平均气温的预测值为 0.05,而月降水量的预测值为 0.04。为了验证 SCAD 在后报近期气候方面的性能,通过校准的聚类树再现了 1991-2000 年期间的日平均气温和月降水量值。
SCDS 输出与从加拿大环境部检索到的观测数据进行了比较。图 7 显示了 1991-2000 年验证期间日平均气温的验证结果。 0.9705 的高 R 平方值表明 SCAD 可以更好地再现观测到的每日温度,10 年期间 RSME 低至 1.6689 摄氏度。图 8 显示了月降水的验证结果。 SCADA 的整体性能在验证期的月总降水量后推方面令人满意(R 平方值为 0.5156,RSME 为 16.8004 mm),揭示了 SCADA 估计极端降水值的能力,这些极端降水值通常与极端降水有关。
天气事件,例如夏季的洪水和冬季的暴风雪。
包含预测变量与日平均温度和月降水量之间的复杂关系,经过验证的聚类树接下来被用于从 PRECIS 模型中缩减等效的区域预测变量。多伦多 PRECIS 模型的结果由里贾纳大学能源与环境研究中心 (CSEE, 2010) 提供。在此插图中考虑了两个 30 年的时间片来预测 1961-1990 年和 2070-2099 年的未来气候情景。前者通常被定义为指示当前气候强迫的基线,而后者则指示未来气候。然后分析相对于基线期的未来气候变化,以帮助了解日平均温度和月降水量的合理未来变化。图 9 显示了 2070-2099 年多伦多月平均气温相对于基线期平均值的变化。它报告了所有月份平均温度的一致上升趋势,平均变化约为±4°C。 1 月、2 月和 3 月的变暖现象相当明显,变化高达 5 至 6 摄氏度,而其余月份则呈现相对较低的增幅(等于或小于 4.5 摄氏度)。总体而言,预计的变暖趋势将在很大程度上提高 2070-2099 年的年平均气温。例如,冬季平均气温(即 12 月、1 月和 2 月)将高于 0 摄氏度,而夏季(即 6 月、7 月和 8 月)将高达 23 摄氏度。图 10 显示了 2070-2099 年多伦多月总降水量相对于基线期的变化。 1-12月降水总量变化较大。冬季(即 12 月、1 月和 2 月)和春季(即 3 月、4 月和 5 月)的总降水量在±26 至±46 毫米范围内显着增加,5 月份除外(仅±5 毫米)。然而,JulyeSeptember 的月降水总量预计将减少 3 至 15 毫米,而 6 月和 10 月没有观察到明显变化。一般来说,多伦多的年降水量会增加,因为就月总降水量而言,预期增加的幅度远高于预计的减少幅度。
5. 警告
开发的缩减工具依赖于许多可能对其未来应用施加严重警告的假设。首先,SCADAS 仍然是一种统计降尺度工具。换句话说,统计降尺度的所有基本假设仍然适用于 SCADA。例如,基本假设是为当前气候开发的统计关系也适用于未来 e 也适用于动力模型的限制(Wilby 等,2004);预测变量集应该能够充分代表未来的气候变化信号,这需要根据预测变量与目标预测变量的相关性以及气候模型的准确表示来筛选预测变量(Wilby 和 Wigley,2000;Giorgi 等,2001) )。其次,SCADS 假设局部变量是正态分布的,因此可以根据 Wilk 统计量有效地处理切割和合并过程。因此,每日降水的结果会很差,因为一年中的大多数日子可能没有降水(即 0 毫米),这会导致伽马分布。针对这一弱点,可以通过引入 Fealy 和 Sweeney(2007)提出的降水发生模型和降水量模型来进一步改进日降水量的降尺度。第三,根据目标区域以前的气候对聚类树进行训练和校准。这意味着目标预测变量的未来预测不会超出先前气候学的范围;因此,无法捕获新的极值。此外,未来的工作还将集中在提高软件预测气候变化背景下局部非平稳过程引起的极端事件的能力,例如水文气象极端事件(Khaliq 等,2006)。
6. 结论
基于逐步聚类分析方法,已经开发了一种统计降尺度工具(SCADAS)来帮助获得高分辨率的气候变化情景。 SCDS 使用聚类树来表示大尺度大气变量和局部地表变量之间的复杂关系。它可以有效地处理连续变量和离散变量,以及预测变量和预测变量之间的非线性关系。通过集成缺失数据检测、相关性分析、模型标定和聚类树绘图等辅助功能模块,SCDS可以快速开发当前和未来气候强迫下的局部天气变量降尺度情景。 SCAD 用于为加拿大多伦多生成 10 公里的日平均气温和月降水量预测。根据 1981-1990 年的观测数据构建了两棵聚类树,然后用于重现 1991-2000 年的历史气候学以进行验证。结果表明,验证期内观测到的温度和降水量都很好地被 SCADA 后报。然后应用经过验证的模型来获得2070 年至 2099 年期间的温度和降水预测。