0.briefly speaking
这是6.S081 Fall 2021的第三个实验,是页表和虚拟内存相关的实验,在之前我们已经详细地阅读了Xv6内核中有关虚拟内存管理的源代码,现在就可以深入一下这个实验了。本实验分为如下三个小任务:
- Speed up system calls (easy)
- Print a page table (easy)
- Detecting which pages have been accessed (hard)
一个一个来看吧…
1.Speed up system calls (easy)
第一个任务是加速系统调用,主要做法就是在创建进程时在用户页表中额外分配一个只读的页面,这样就可以在执行特定系统调用时直接从用户页表中读出数据并返回,减少在用户态和内核态之间的穿越次数,从而减少系统调用的开销,加速执行过程。
按照实验指导书上的提示,我们可以按照如下步骤来完成这个任务:
1.在kernel/proc.c的allocproc函数中为进程分配一个物理内存页面,专门用来存放共享信息
我们首先阅读一下kernel/proc.c中的allocproc函数,看看它在做什么,然后仿照它的写法,在代码中添加分配一个加速页面的代码,这个页面在后面会由proc_pagetable函数映射到进程页表内。
// Look in the process table for an UNUSED proc.
// If found, initialize state required to run in the kernel,
// and return with p->lock held.
// If there are no free procs, or a memory allocation fails, return 0.
// 译:查找进程表,找到UNUSED状态的进程
// 如果找到了UNUSED状态的进程,那么初始化它的状态,使其能在内核态下运行
// 并且返回时不占用锁
// 如果没有空闲进程,或内存分配失败,则返回0
static struct proc*
allocproc(void)
{
struct proc *p;
// 遍历进程组,寻找处于UNUSED状态的进程
for(p = proc; p < &proc[NPROC]; p++) {
// 首先获取进程的锁,保证访问安全
acquire(&p->lock);
// 如果进程状态为UNUSED,则跳转至found
if(p->state == UNUSED) {
goto found;
} else {
// 否则释放锁,检查下一个进程是否为UNUSED状态
release(&p->lock);
}
}
return 0;
// 以下是初始化一个进程的代码
found:
// 为当前进程分配PID,并将当前进程状态改为USED
p->pid = allocpid();
p->state = USED;
// Allocate a trapframe page.
// 分配一个trapframe页,如果不成功则释放当前进程和锁
if((p->trapframe = (struct trapframe *)kalloc()) == 0){
freeproc(p);
release(&p->lock);
return 0;
}
// <照葫芦画瓢,我们也像trapframe一样申请一个空闲物理页用来存储变量>
// <那么在进程信息里也得保留一份指向这个页面的指针>,这里记为p->usyscall
// 因为内核执行的是直接映射,所以kalloc返回的指针可以直接当作物理地址映射到页表中
if((p->usyscall) == (struct usyscall *)kalloc() == 0){
freeproc(p);
release(&p->lock);
return 0;
}
// <将pid信息放入结构体,其实也就是放到了这个物理页面开头处>
p->usyscall->pid = p->pid;
// An empty user page table.
// 为当前进程申请一个页表页,并将trapframe和trampoline页面映射进去
// 注意trampoline代码作为内核代码的一部分,不用额外分配空间,只需要建立映射关系
// <我们后面将要修改这个函数,将加速页面一并映射进去>
p->pagetable = proc_pagetable(p);
// 如果上述函数执行不成功,则释放当前进程和锁
if(p->pagetable == 0){
freeproc(p);
release(&p->lock);
return 0;
}
// Set up new context to start executing at forkret,
// which returns to user space.
// 译:设置新的上下文并从forkret开始执行
// 这会回到用户态下
// 这里涉及trap的返回过程,我们在后面研究源码时再深入解读这里的行为
memset(&p->context, 0, sizeof(p->context));
p->context.ra = (uint64)forkret;
p->context.sp = p->kstack + PGSIZE;
// 返回新的进程
return p;
}
注意在上面我将与实验有关的注释全部用尖括号括出了,正如注释中所展示的,我们首先要修改的是对于进程结构体的定义,在其中添加一枚指针指向usyscall结构体,这枚指针本质上也指向了加速页面的起始物理地址,如下所示:
// Per-process state
struct proc {
struct spinlock lock;
// p->lock must be held when using these:
enum procstate state; // Process state
void *chan; // If non-zero, sleeping on chan
int killed; // If non-zero, have been killed
int xstate; // Exit status to be returned to parent's wait
int pid; // Process ID
// wait_lock must be held when using this:
struct proc *parent; // Parent process
// these are private to the process, so p->lock need not be held.
uint64 kstack; // Virtual address of kernel stack
uint64 sz; // Size of process memory (bytes)
pagetable_t pagetable; // User page table
struct trapframe *trapframe; // data page for trampoline.S
struct usyscall *usyscall; // <加入一个指向加速页面的指针>
struct context context; // swtch() here to run process
struct file *ofile[NOFILE]; // Open files
struct inode *cwd; // Current directory
char name[16]; // Process name (debugging)
};
然后在allocproc中我们为这枚指针分配了一个物理页,并将pid信息放入了这个页面,这些代码已经在上面完整写出了,在此不再赘述。
2.在freeproc函数中编写释放内存的代码,这是用于可能出现的错误处理
首先还是先阅读一下freeproc的代码实现,并在其中加入释放usyscall页面的代码:
// free a proc structure and the data hanging from it,
// including user pages.
// p->lock must be held.
// 译:释放进程结构体和悬挂在其上的数据,包括页表
// 必须要持有进程p的锁才可以调用此函数
static void
freeproc(struct proc *p)
{
// 释放trapframe页面,之所以要单独释放是因为:
// trapframe页面位于地址空间的最高处,与下面已经使用的地址空间是分离的
if(p->trapframe)
kfree((void*)p->trapframe);
// 释放完将trapframe指针置为空
p->trapframe = 0;
// <仿照trapframe内存释放的代码,在出错时将p->usyscall页面释放,并将指针置空>
if(p->usyscall)
kfree((void*)p->usyscall);
p->usyscall = 0;
// 释放页表
// proc_freepagetable会调用uvmunmap解除trampoline和trapframe的映射关系
// 并最终调用uvmfree释放内存和页表
// <我们后面要修改此处的函数>
if(p->pagetable)
proc_freepagetable(p->pagetable, p->sz);
// 将页表与其他量全部置为空,表示进程已完全释放
p->pagetable = 0;
p->sz = 0;
p->pid = 0;
p->parent = 0;
p->name[0] = 0;
p->chan = 0;
p->killed = 0;
p->xstate = 0;
p->state = UNUSED;
}
但在完成这些之后,仅仅释放了usyscall页面的物理内存,接下来还要在proc_freepagetable函数中解除一下页面的映射关系,这样的释放过程才算是完备,故修改proc_freepagetable函数如下:
// Free a process's page table, and free the
// physical memory it refers to.
// 译:释放进程的页表,并释放它指向的物理内存
void
proc_freepagetable(pagetable_t pagetable, uint64 sz)
{
// 解除TRAMPOLINE和TRAPFRAME的映射关系
// 之所以要分开来写是因为它们和连续的地址空间是分离的
// 连续空间使用uvmfree一套解决
uvmunmap(pagetable, TRAMPOLINE, 1, 0);
uvmunmap(pagetable, TRAPFRAME, 1, 0);
// <释放USYSCALL函数的映射关系>
uvmunmap(pagetable, USYSCALL, 1, 0);
uvmfree(pagetable, sz);
}
3.最后,在kernel/proc.c的proc_pagetable函数中完成这个页面的映射,并设置页面访问权限为用户态只读(PTE_U | PTE_R)
我们先阅读一下proc_pagetable的代码实现,然后将这个“加速页面”映射到页表中,代码如下:
// Create a user page table for a given process,
// with no user memory, but with trampoline pages.
// 译: 为给定的进程创建一个页表
// 没有用户地址空间,只有trampoline页面
pagetable_t
proc_pagetable(struct proc *p)
{
pagetable_t pagetable;
// An empty page table.
// 调用uvmcreate函数返回一个空页表
// uvmcreate函数的详细解释见完全解析系列博客(2)
pagetable = uvmcreate();
if(pagetable == 0)
return 0;
// map the trampoline code (for system call return)
// at the highest user virtual address.
// only the supervisor uses it, on the way
// to/from user space, so not PTE_U.
// 译:将trampoline页面(用于系统调用返回)映射到用户最高虚拟地址处
// 只有超级用户(处于超级用户模式)下才可以使用
// 所以PTE_U标志为0
// mappages函数的讲解见系列博客(1)
// uvmfree函数的讲解见系列博客(2)
// 如果出错,就调用uvmfree来释放映射关系,回收页表
// 注意这里传入的sz是0,表明在这一步没有实际的物理内存需要释放
if(mappages(pagetable, TRAMPOLINE, PGSIZE,
(uint64)trampoline, PTE_R | PTE_X) < 0){
uvmfree(pagetable, 0);
return 0;
}
// map the trapframe just below TRAMPOLINE, for trampoline.S.
// uvmunmap函数的讲解见系列博客(2)
// 将trapframe映射到紧邻TRAMPOLINE的下一个页面
// 如果出错,首先取消TRAMPOLINE的映射关系,再使用uvmfree释放页表映射关系,回收页表
if(mappages(pagetable, TRAPFRAME, PGSIZE,
(uint64)(p->trapframe), PTE_R | PTE_W) < 0){
uvmunmap(pagetable, TRAMPOLINE, 1, 0);
uvmfree(pagetable, 0);
return 0;
}
// <仿照上面的格式将加速页面映射到页表中>
// 使用mappages将此页映射到页表中
// 如果出错要释放映射trampoline和trapframe的映射关系
// 并释放pagetable的内存,返回空指针
if(mappages(pagetable, USYSCALL, PGSIZE,
(uint64)(p->usyscall), PTE_R | PTE_U) < 0){
uvmunmap(pagetable, TRAMPOLINE, 1, 0);
uvmunmap(pagetable, TRAPFRAME, 1, 0);
uvmfree(pagetable, 0);
return 0;
}
// <添加代码结束>
return pagetable;
}
其实这个实验要做的事情不多,但其实非常考验对页表和虚拟内存机制的理解,让我们梳理一下这个小小的实验。
首先,allocproc函数会在调用kalloc分配一个物理页面专门用来存储一些不用进入内核态就可以直接读取的信息。kalloc会返回一个指针,虽是虚拟地址,但由于内核页表的直接映射机制,我们也可以将此地址作为物理地址直接使用。随后,我们将想要加速访问的数据(pid)直接放入此页面中,并在进程信息结构体中维持一个指向此页面的指针。注意直到此时,这个页面只是存在了,但是进程还没有将其映射到自己的地址空间中,因而在页表中是访问不到这个页面的。
接下来allocproc会调用proc_pagetable函数,这个函数会创建进程的页表,并将特殊的几个页面(trampoline、trapframe、我们的加速页面)映射到页表中。这几个特殊页面必须已经分配好,即在物理内存中已经存在,我们在这里只是使用建立映射关系。trampoline是内核代码的一部分,始终在内存中存在,trapframe和我们的加速页面在之前的allocproc中已经分配完毕,故它们也是存在的,所以在proc_pagetable中我们使用mappages一一将它们映射到进程页表中。
在上述步骤都完成之后,一个进程在用户态下,直接访问所谓的USYSCALL虚拟地址,这个地址经过多级页表的翻译就会索引到我们分配的加速页面中,进而直接获取到了想要的数据。
上述是整个实验的原理,更加精妙的地方在于错误处理,即在上述过程中可能出现的错误处理及对应的处置措施。注意allocproc、proc_pagetable、proc_freepagetable、free_proc之间的分工和配合,不能错乱。
- allocproc负责分配物理内存
- freeproc负责释放物理内存
- proc_pagetable负责申请页表页和建立映射关系
- proc_freepagetable负责取消映射关系和回收页表页
值得玩味的是proc_pagetable函数中映射页面失败时,会返回一个空指针给allocproc,这里如果返回空指针给allocproc的话,后面会直接进入freeproc,且此时因为p->pagetable指针为空,所以proc_freepagetable函数不会执行,所以原本属于它的释放逻辑全部得写到proc_pagetable中作为补偿,所以我们看到其实proc_pagetable中的错误处理逻辑和proc_freepagetable的逻辑从形式上是十分相似的。
运行一下测试程序,结果是正确的:

2.Print a page table (easy)
第二个小任务也很简单,就是将一个进程的页表按照指定格式打印出来。按照实验指导书所述,这个函数的格式应该和walkaddr非常相似,所以应该是一个递归的逻辑,所以我们就参照这个函数的格式来写。但是最困难的地方可能在于控制打印格式,所以我首先定义了raw_vmprint函数,这个函数的作用在于按照页表的层次打印指定数量的缩进符,代码如下(kernel/vm.c):
// 此函数借鉴了walkaddr的写法,用来递归地打印页表
void
raw_vmprint(pagetable_t pagetable, int Layer)
{
// 遍历页表的每一项
for(int i = 0 ; i < 512 ; ++i){
pte_t pte = pagetable[i];
// 如果当前的pte指向的是更低一级的页表
if((pte & PTE_V) && (pte & (PTE_R|PTE_W|PTE_X)) == 0){
// 从PTE中解析出物理地址,并打印指定数量的缩进符
// 注意解析物理地址时,不能只是简单地将权限位移除出去,还应该左移12位,让出页内偏移量
uint64 phaddr = (pte >> 10) << 12;
for( ; Layer != 0 ; --Layer)
printf(".. ");
// 打印本级页表信息,向孩子页表递归,注意层数+1
printf("..%d: pte %p pa %p\n", i, pte, phaddr);
uint64 child = PTE2PA(pte);
raw_vmprint((pagetable_t)child, Layer + 1);
}
// 如果当前PTE指向的是叶级页表
// 取出物理地址并打印信息,随后返回
else if (pte & PTE_V){
uint64 phaddr = (pte >> 10) << 12;
printf(".. .. ..%d: pte %p pa %p\n", i, pte, phaddr);
}
}
}
然后在此函数的基础上封装一层,就构成了最终的vmprint函数:
void vmprint(pagetable_t pagetable)
{
raw_vmprint(pagetable, 0);
}
不要忘记在def.h函数中加上vmprint的函数签名,否则这个函数不能被其他函数调用:
// kernel/def.h:173
void vmprint(pagetable_t); // <插入vmprint的函数签名>
最后别忘了在exec函数返回之前调用vmprint函数:
// kernel/exec.c:119-122
// 为第一个进程打印页表,注意这个页表头也可以放在vmprint中打印
// 我为了让vmprint函数更加干净,把这个打印语句摘出来了
if(p->pid == 1){
printf("page table %p\n", p->pagetable);
vmprint(p->pagetable);
}
这个小任务到此就结束了,非常简单,让我们看看具体的打印效果:
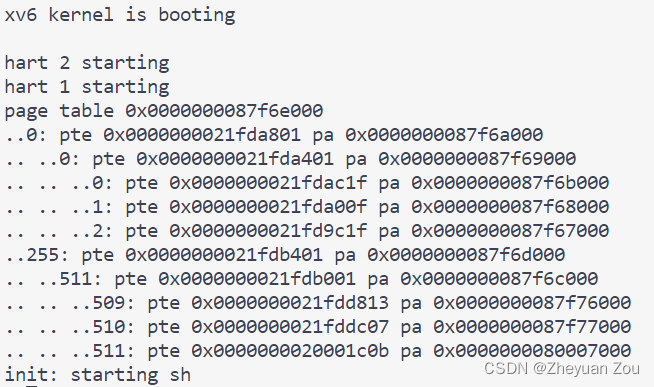
这些虚拟地址都应该和实验指导书上保持一致,而具体的物理地址可以随着实验环境的不同而不同。最后再测试一下打印的正确性,肯定是没有问题的:

3.Detecting which pages have been accessed (hard)
最后一个任务是实现一个系统调用来检测某个页面是否被访问的,其实也非常简单。按照实验指导书中的指示,我们首先在头文件kernel/riscv.h中将PTE_A加入头文件,查询一下RISC-V的指令手册,发现PTE_A这个标志在第6位:

另外,我们规定一下一次最多可以查询的页面数量MAXSCAN,它同样也定义在kernel/riscv.h文件中(32这个数值是通过阅读user/pgtbltest.c中的pgaccess_test函数确认的)。
#define PTE_V (1L << 0) // valid
#define PTE_R (1L << 1)
#define PTE_W (1L << 2)
#define PTE_X (1L << 3)
#define PTE_U (1L << 4) // 1 -> user can access
#define PTE_A (1L << 6) // <加入对访问位的支持>
#define MAXSCAN 32 // <限制一次最多可以查询的页面数量>
然后我们就可以来着手实现一下sys_pgaccess函数,按照指导书上的提示,这个函数的实现也是相对简单的,我的代码实现如下:
#ifdef LAB_PGTBL
// 在这里声明对kernel/vm.c/walk函数的引用声明
extern pte_t * walk(pagetable_t, uint64, int);
int
sys_pgaccess(void)
{
// lab pgtbl: your code here.
// 在内核态下声明一个BitMask,用来存放结果
uint64 BitMask = 0;
// 声明一些变量,用来接收用户态下传入的参数
uint64 StartVA;
int NumberOfPages;
uint64 BitMaskVA;
// 首先读取要访问的页面数量
if(argint(1, &NumberOfPages) < 0)
return -1;
// 如果页面数量超过了一次可以读取的最大范围
// 系统调用直接返回
if(NumberOfPages > MAXSCAN)
return -1;
// 读取页面开始地址和指向用户态存放结果的BitMask的指针
if(argaddr(0, &StartVA) < 0)
return -1;
if(argaddr(2, &BitMaskVA) < 0)
return -1;
int i;
pte_t* pte;
// 从起始地址开始,逐页判断PTE_A是否被置位
// 如果被置位,则设置对应BitMask的位,并将PTE_A清空
for(i = 0 ; i < NumberOfPages ; StartVA += PGSIZE, ++i){
if((pte = walk(myproc()->pagetable, StartVA, 0)) == 0)
panic("pgaccess : walk failed");
if(*pte & PTE_A){
BitMask |= 1 << i; // 设置BitMask对应位
*pte &= ~PTE_A; // 将PTE_A清空
}
}
// 最后使用copyout将内核态下的BitMask拷贝到用户态
copyout(myproc()->pagetable, BitMaskVA, (char*)&BitMask, sizeof(BitMask));
return 0;
}
#endif
所以这就是sys_pgaccess系统调用的实现,最后来测试一下它的正确性:

4.结语
至此,就完成了6.S081 Fall 2021的第三个实验,有关虚拟内存和页表机制的实验内容。总的来说实验难度都没有很大,在指导书的帮助下可以很快完成。但是对于内核代码的研究却远远没有结束,接下来的实验内容涉及到操作系统中最重要的一个部分,那就是终端和陷阱机制的实现。已经迫不及待去扒一下对应的源码了…哈哈