0. Briefly Speaking
这是记录本人完成MIT 6.S081课程系列博客的第一篇,在实验过程中我发现有非常多的点需要及时记录,也可能会有很多问题在完成后续的实验之后需要补记。这使得写这个系列博客非常有必要性,篇幅也可能会很长,并且还可能在后续持续更新和勘误,这是这个系列博客的引子。
我完成的实验是2021年秋季的,课程的schedule在这里。
实验的大部分内容是修改和补充操作系统设施,这意味着我们要游走于多个文件之间,在多个文件之间进行改动,如此细碎的任务也非常需要一篇篇描述详细的博客来记录过程中遇到的所有问题以及思考过程。否则会让很多实验时的收获随着时间流逝而逐渐遗忘,另外,阅读xv6内核代码我认为也是非常有益的,在本系列博客中主要记录实验过程。可能未来还会专门地开一个博客专栏专门来记录源码阅读的过程。
第一个实验是系统编程相关的实验,这个实验内容不涉及xv6操作系统的内核,我们只需要调用已有的系统调用来完成一些具有特定功能的小程序即可,就像使用Linux系统编程的接口在Linux上编程一样。
完成本实验的一些关键点如下(图中以sleep实验为例):
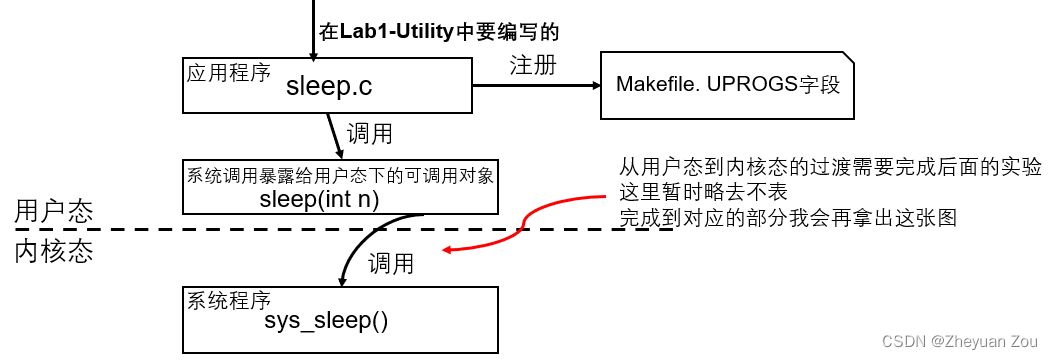
1. 本实验只需要使用user/user.h文件中暴露给用户使用的系统调用接口完成应用程序的编写,无需修改内核,所以这个实验只是小试牛刀,还没有深入操作系统。
2. 需要在Makefile文件中的UPROGS字段中将编写的用户程序加入,这样才可以在xv6的命令行中使用程序。
3. 我们编写的用户程序最终要以命令行的形式来驱动,所以如何从argc, argv中提取命令行参数是必须知道的,这一点可以参考这篇短文。
1.Boot xv6
这部分其实就是在你的设备上下载xv6源码并且将它跑起来的一个教程。
首先查看实验指导书进入下载工具页,这里会教你如何从git下载xv6的源代码,以及怎样才可以将它们在你的设备上运行起来。
就拿我本人而言,我是在WSL2上做的实验,所以这里只需要按照在Windows上安装的指示,将需要的软件包一一安装即可,复制命令行并粘贴运行之。另外值得一提的是,这里我安装的版本是Ubuntu22.04,此版本下apt软件源的qemu虚拟机版本是符合xv6 2021的需求的,其他版本的WSL貌似都有些过时。
接下来就是按照要求从github上下载xv6系统源码,命令行在指导书中也已经给出了:
# 下载xv6源码
git clone git://g.csail.mit.edu/xv6-labs-2021
这个过程有点慢,耐心等待一下。下载完毕之后我们就得到了完整的xv6源码,xv6使用不同的分支(branch)来管理不同的实验,这样方便了代码管理和code review,每次在进行试验之前都要使用git checkout,跳转到对应的分支,对应的分支目录下有专门为此实验裁剪好的系统。完成第一个实验,则要跳转到如下分支,我在写下此博客时已经完成后续几个实验,所以这里我就跳转到其他分支:
git checkout util
接下来文档中介绍了如何向gitHub提交代码等,这里略去不表,直接开始启动xv6:
# 如果你想了解更多细节,就去翻翻Makefile文件
make qemu
启动过程如下所示,如果出现命令行准备等待接收命令,则证明已经启动成功:
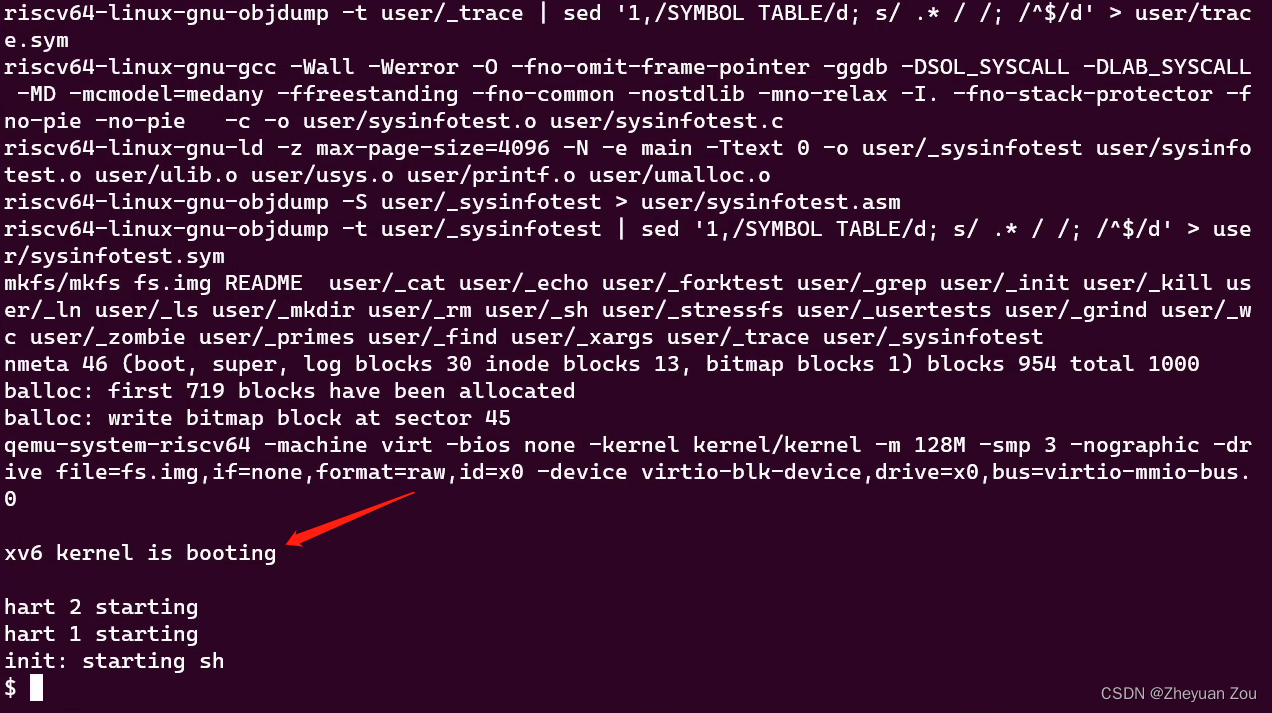
我使用的是AMD R7-4800H处理器,不知道为什么,一旦开始启动xv6内核CPU就会疯狂占用到40%左右。(最早其实我是在虚拟机上搭建的环境,但是发现一旦启动xv6,虚拟机就会完全卡死,无奈换成了WSL2。)这里如果有人知道为什么,劳烦在评论区告诉我,谢谢!
2.sleep (easy)
这是第一个实验,目的是写一个简单的程序sleep,它调用xv6内核中的sleep系统调用完成休眠一段时间的功能。
做Lab1的时候,千万要分清所谓用户态程序和系统调用之间的区别,我们在这个实验中写的是应用程序,它要调用同名的系统调用从而完成对应的功能,所有在用户态下可用的系统调用和功能函数都在user/user.h头文件中,可以查看此文件获得可用的功能函数。
首先在写代码之前,首先读一下提示(hints)部分,着重注意以下画红框的部分,它们对理清头绪很重要:

学会了如何从命令行中解析对应的参数之后,直接就可以开始写代码了,非常简单:
// sleep.c
#include "kernel/types.h"
#include "kernel/stat.h"
#include "user/user.h"
int
main(int argc, char *argv[])
{
int time;
if(argc != 2){
// 输入的参数数量错误,报错并退出
fprintf(2, "sleep: usage: sleep <time>\n");
exit(1);
}
time = atoi(argv[1]); // 将输入的时间转化为整数,调用sleep完成功能
sleep(time);
exit(0);
}
不要忘记在Makefile的UPROGS字段加入_sleep:
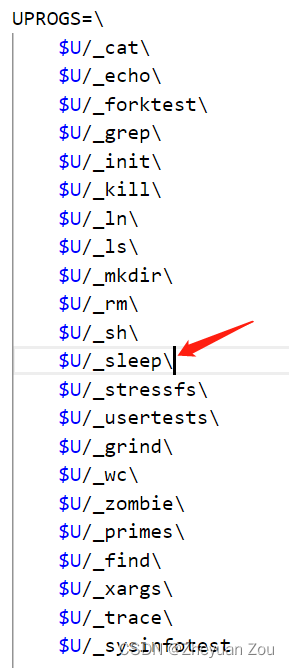
然后就可以使用如下命令测试一下程序的正确性:
# 测试一下util实验中sleep函数的正确性
./grade-lab-util sleep
实验结果如下,表明结果是正确的:

2.pingpong (easy)
这是第二个小程序,主要内容就是使用管道完成两个进程之间的通信,xv6 book中给出了一个非常好的小例子,它通过管道将“Hello World\n”输出到wc程序,我们只需要照葫芦画瓢就可以了。

这里直接给出含注释的代码,细节不再阐述:
#include "kernel/types.h"
#include "kernel/stat.h"
#include "user/user.h"
int
main(int argc, char *argv[])
{
int PipeFd[2]; // 管道的两个文件描述符
pipe(PipeFd); // 创建一个管道
if(fork() == 0){
// 子进程
char Send = 'a';
char Receive;
read(PipeFd[0], &Receive, 1); // 在没有接收到数据之前,子进程会被阻塞在此
fprintf(1, "%d: received ping\n", getpid());
write(PipeFd[1], &Send, 1);
}
else{
// 父进程
char Send = 'b';
char Receive;
write(PipeFd[1], &Send, 1);
wait(0); // 等待子进程结束之后再读出子进程的数据,否则可能自发自收
read(PipeFd[0], &Receive, 1);
fprintf(1, "%d: received pong\n", getpid());
}
close(PipeFd[0]); // 关闭文件描述符
close(PipeFd[1]);
exit(0);
}
运行一下测试用例,通过:

3.primes(hard)
这道题算是第一个实验中相对复杂一点的,它要求我们使用管道通信实现Eratosthenes筛法求解35以内的素数,这种算法的具体原理可以查看链接:Eratosthenes筛法,里面详述了此种算法的原理,主要部分如下图所示。

此算法的核心如下:对于任何一级流水线而言,到达当前流水线级的最小数字一定是一个素数,因为在处理之前比它更小的数字时它没有被筛掉,在当前流水线下它也需要作为一个基数去筛掉它在现存数字中的所有倍数,将所有剩下来的数字送入下一级流水线,直到本级流水线只剩下一个数字时,整个筛法结束。
这里我直接给出我的解法,并在其中给出注释:
#include "kernel/types.h"
#include "kernel/stat.h"
#include "user/user.h"
int
main(int argc, char* argv[])
{
int PresentNum = 2; // 流水线开始时要输入初始数据
int ParentPipeFd[2]; // 父进程要使用的管道标识符
int ChildPipeFd[2]; // 子进程要使用的管道标识符,用于新建下一级流水线
pipe(ParentPipeFd); // 首先创建一个管道
/* 在主进程中将数字2-35送入管道 */
while(PresentNum <= 35){
write(ParentPipeFd[1], &PresentNum, sizeof(PresentNum));
++PresentNum;
}
while(1)
{
if(fork() == 0) // 创建子进程
{
// 因为创建新进程时复制了管道的描述符,这里子进程又不需要向管道中写入
// 为了节省文件描述符,这里关掉不用的描述符
close(ParentPipeFd[1]);
int Base = -1; // 当前这一级流水线的筛出来的素数,我们要用这个数筛掉其他数
int ReadNumber = 0;
int ReadCounter = 0; // 统计当前级流水线一共读出了多少个数字,为1时跳出循环
char IsPipeEstablished = 0; // 判断子进程是否已经创建新的流水线
while(read(ParentPipeFd[0], &ReadNumber, sizeof(PresentNum)))
{
if(Base == -1) // 如果Base是-1,表示读取的是第一个数字
{
// 第一个数字就是基数,也是本级流水线筛出的素数,打印出来即可
Base = ReadNumber;
fprintf(1, "prime %d\n", Base);
}
// 否则如果后进来的数字没有被筛掉,则送入下一级流水线
else if(ReadNumber % Base != 0)
{
// 子进程流水线如果没有创建,则创建之再写入
if(IsPipeEstablished == 0)
{
pipe(ChildPipeFd);
IsPipeEstablished = 1;
write(ChildPipeFd[1], &ReadNumber, sizeof(PresentNum));
}
// 如果流水线已经创建,则直接写入
else
write(ChildPipeFd[1], &ReadNumber, sizeof(PresentNum));
}
// 统计截至目前已经从上一级流水线中读出了多少个数字
ReadCounter++;
}
// 将管道的读口关闭
close(ParentPipeFd[0]);
// 如果一共只读出了一个数字,那么跳出循环,筛法结束
if(ReadCounter == 1)
exit(0);
// 关键:将新生成的管道标识符赋值给父进程,因为当前的子进程是下一级流水线的父进程
ParentPipeFd[0] = ChildPipeFd[0];
ParentPipeFd[1] = ChildPipeFd[1];
}
else
{
// 父进程啥事也不要干,等子进程退出之后也退出就可以了
// 但是要关闭自己的管道标识符,防止资源浪费
close(ParentPipeFd[0]);
close(ParentPipeFd[1]);
wait(0);
exit(0);
}
}
}
其实上面的代码完全不用申请新的管道,每一次都用旧的管道模拟流水线就可以,但是我为了更能拟合和贴近下面这张图,特别在每一个子进程中都申请了新的管道:
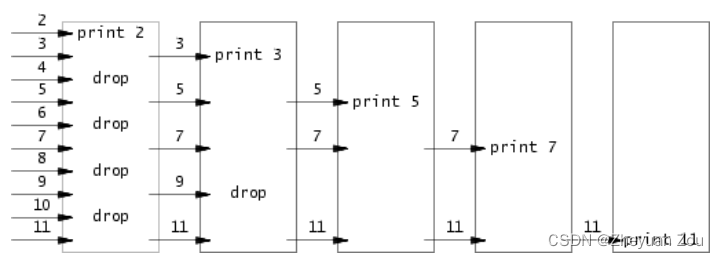
测试一下这个程序,思路是正确的:

4.find (moderate)
第四个小程序是写一个版本的find函数,它可以在指定的目录下寻找指定名称的文件并打印出来,在编写代码之前可以从ls.c例程中学习如何读取目录信息,当深入到嵌套的文件夹中寻找时,应该使用递归写法。
首先来看xv6代码中描述文件信息和目录的结构体,这对后面的编程比较重要:
// 文件信息结构体
// 其中type表明了文件的类型是:文件、目录还是设备
#define T_DIR 1 // Directory
#define T_FILE 2 // File
#define T_DEVICE 3 // Device
struct stat {
int dev; // File system's disk device
uint ino; // Inode number
short type; // Type of file
short nlink; // Number of links to file
uint64 size; // Size of file in bytes
};
// Directory is a file containing a sequence of dirent structures.
// 所谓目录,就是一系列dirent结构组成的顺序序列
#define DIRSIZ 14
struct dirent {
ushort inum;
char name[DIRSIZ];
};
其实也非常简单,学会使用fstat来读取文件信息之后基本上就差不多了,直接看代码吧:
#include "kernel/types.h"
#include "kernel/stat.h"
#include "user/user.h"
#include "kernel/fs.h"
void
searchFile(char* DirPath, char* FileName)
{
char TargetDirPath[512], *Ptr;
int Fd;
struct dirent DirEntry;
struct stat State;
// 打开指定的路径
if((Fd = open(DirPath, 0)) < 0)
{
fprintf(2, "find: cannot open %s\n", DirPath);
exit(1);
}
// 读取对应路径的目录信息
if(fstat(Fd, &State) < 0)
{
fprintf(2, "find: cannot stat %s\n", DirPath);
close(Fd);
exit(1);
}
switch(State.type)
{
// 如果对应的文件类型是文件,那么结束此次搜索
case T_FILE:
fprintf(2, "find: you are supposed to search for a file in a directory rather than a file \n");
break;
// 如果输入的路径确实指向一个目录,开始搜索
case T_DIR:
// 首先看看目录路径是否过长,这可能导致路径数组溢出
if(strlen(DirPath) + 1 + DIRSIZ + 1 > sizeof TargetDirPath)
{
printf("find: directory's path too long\n");
break;
}
// 将目录路径拷贝过去
strcpy(TargetDirPath, DirPath);
Ptr = TargetDirPath + strlen(TargetDirPath);
*Ptr++ = '/';
// 读取这个目录下的文件项
while(read(Fd, &DirEntry, sizeof(DirEntry)) == sizeof(DirEntry))
{
// 如果当前的目录项不包含信息,则跳过
if(DirEntry.inum == 0)
continue;
// 否则将新的目录加入到已有的路径中,准备检索
memmove(Ptr, DirEntry.name, DIRSIZ);
Ptr[DIRSIZ] = 0;
if(stat(TargetDirPath, &State) < 0)
{
fprintf(2, "find: cannot state %s\n", TargetDirPath);
exit(1);
}
// 找到目标名的文件,注意使用strcmp函数来完成这个任务
if(strcmp(FileName, DirEntry.name) == 0 && State.type == T_FILE)
{
fprintf(1, TargetDirPath);
fprintf(1, "\n");
}
// 如果目录之下还是目录,则开始递归搜索
// 注意要跳过.和..这两个特殊目录
else if (
State.type == T_DIR &&
strcmp(DirEntry.name, ".") != 0 &&
strcmp(DirEntry.name, "..") != 0
)
searchFile(TargetDirPath, FileName);
}
break;
}
close(Fd);
return;
}
int
main(int argc, char* argv[])
{
if(argc < 3)
{
fprintf(2, "find: command needs at least 2 params\n");
exit(1);
}
searchFile(argv[1], argv[2]); // 在主函数中直接调用之即可
exit(0);
}
测试上述函数,结果如图所示,表明函数是正确的:

5.xargs (moderate)
xargs(extensive arguments)是Linux系统中的一个很重要的命令,它一般通过管道来和其他命令一起调用,来将额外的参数传递给命令,这个小问题就是实现自己版本的xargs命令。初次理解xargs命令时还是有点费解的,指导书中的一个例子如下:
$ echo hello too | xargs echo bye
bye hello too
$
要理解这个例子就将echo hello too | xargs看作一个整体,它本质上是将hello too传递给了xargs,然后经过xagrs的逻辑处理,就会将这些额外传入的参数交给后面的echo命令。我们的任务就是实现这里所谓的xargs的处理逻辑。代码如下,思路都注释在其中了:
#include "kernel/types.h"
#include "kernel/stat.h"
#include "user/user.h"
#include "kernel/fs.h"
#include "kernel/param.h"
void
// 执行Command对应的命令行,Argv是要传入的参数数组
execCommand(char* Command, char* Argv[MAXARG])
{
if(fork() == 0)
exec(Command, Argv);
else
wait(0);
}
int
main(int argc, char* argv[])
{
char CmdPath[512] = "", *Ptr;
// 参数数组
char* Argv[MAXARG];
int StartIndex = argc - 1;
/* E.g: xargs grep hello */
// 首先解析出原有的命令
Ptr = CmdPath + strlen(CmdPath);
memmove(Ptr, argv[1], strlen(argv[1]));
Ptr[strlen(argv[1])] = 0;
// 将原有指令后面的参数记录下来,argv[0]是xargs,故从1开始
for(int i = 1 ; i < argc ; ++i)
{
uint Length = strlen(argv[i]) + 1;
Argv[i - 1] = malloc(Length);
memmove(Argv[i - 1], argv[i], Length);
}
// 设置Argv[Argc] = NULL
Argv[StartIndex + 1] = 0;
// 因为是通过|读入的其他参数,所以这里从标准输入一个个字符读入即可
// 遇到换行符说明这个额外参数已经结束
char ReadChar;
Argv[StartIndex] = malloc(512);
Ptr = Argv[StartIndex];
while(read(0, &ReadChar, 1))
{
if(ReadChar != '\n')
{
*Ptr = ReadChar;
++Ptr;
}
else
{
// 一旦遇到结尾,给字符串末尾一个空字符,执行此命令行即可
*Ptr = 0;
execCommand(CmdPath, Argv);
Ptr = Argv[StartIndex];
}
}
// 最后释放内存
for(int i = 0 ; i <= StartIndex ; ++i)
free(Argv[i]);
exit(0);
}
下面测试一下,结果如下,和指导书中预期的是一致的:

结语
这就是6.S081的第一个实验,主要考察的就是系统编程,其实其中后三个任务还是有一定难度的。不过经过编写这些代码,多少还是对系统调用有了更深的认识,这是很大的收获。其实在做xv6的实验时,更大的收获不是解决实验内容本身,这些实验内容只是xv6的很小一部分功能,要在解决问题的同时和内核代码一起玩耍,调试并阅读源码,这才是学习这门课的精华所在。