
为期一周的人工智能和机器学习领域顶级会议NeurIPS已于当地时间12月16日圆满结束。蚂蚁集团有20篇论文被本届会议收录,其中《Prompt-augmentedTemporalPointProcessforStreamingEventSequence》由蚂蚁集团研究并撰写,作者包括薛思乔、王言、褚志轩、师晓明、蒋才高、郝鸿延、蒋刚玮、冯晓云、JamesY.Zhang、周俊。
作者简介:薛思乔是这篇论文的主要作者,也是蚂蚁集团高级算法专家,主要研究方向是生成式序列模型(sequentialmodeling),他的研究成果曾多次发表于主流机器学习相关会议(NeurIPS/ICML/AAAI)。最近一年团队的主要工作聚焦于大语言模型与时间序列的交叉方向,在NeurIPS'23发表了事件序列预测模型的持续学习方法"PromptTPP"以及利用大语言模型支持事件序列预测的方法"LAMP"两篇论文。
本文中,薛思乔会带大家了解论文《Prompt-augmentedTemporalPointProcessforStreamingEventSequence》的背景和主要研究成果,完整论文可点击阅读原文查看。
01 背景和动机
时间序列模型通常用于分析和预测具有明显时间顺序特征的序列数据。这些场景包括但不限于:
- 金融市场分析与预测:如股票价格、汇率、商品期货等时间序列数据的趋势预测。
- 交通流量和运输:预测车辆的行驶情况,从而改进城市交通规划和运营管理。
在真实的商业场景中,时间序列(本文特指事件序列,eventsequence)通常是以流式(stream)的形式存在并且不断更新的。对这样的数据建模,我们通常有以下几个方法(图一):
- 预训练一个点过程模型,然后不再更新:最简单粗暴,但是因为它们在被部署后不会再进行学习或更新,从而导致它们在面对新的或者未见过的数据时性能下降,因为这些数据可能与训练集有所不同(这种现象称为分布漂移)。
- 每隔一段时间,针对固定窗口的数据重新训练一次点过程模型:这个方法会遇到灾难性遗忘的问题(图二),即忘记过去任务的重要信息。
- 点过程模型的在线学习版本:模型的维护并不容易,而且也会遇到灾难性遗忘的问题。
在这样的背景下,我们如何能更有效率、更有效果的进行模型的持续学习?我们在文章中Prompt-augmentedTPP尝试解答了这个问题,并且被NeurIPS'23接收。
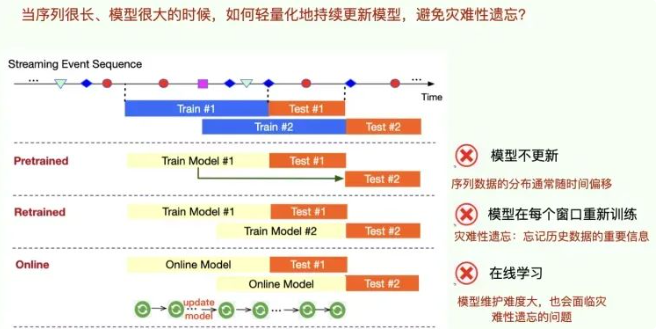
图1:主要方法的示意图
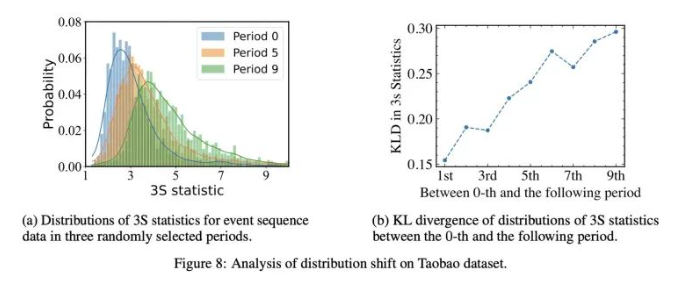
图2:在开源数据集事件序列上做的数据分析
02 问题定义
我们首先定义任务:与NLP领域不同,我们沿着时间轴定义任务(task),以及任务的训练、验证和测试流程。然后,我们的问题是,一个点过程模型应该如何持续学习,使得它可以既能够及时适应分布变化,同时避免灾难性遗忘。另外,我们希望这个新的方法有足够的实用性,即是taskagnositic的,不需要保存任务的信息(比如事件序列中事件的属性信息)即可进行预测。taskagnostic是持续学习方向常见的诉求,这种方法更有效率,而且也能满足隐私保护的要求(比如不能存储某些属性信息)。
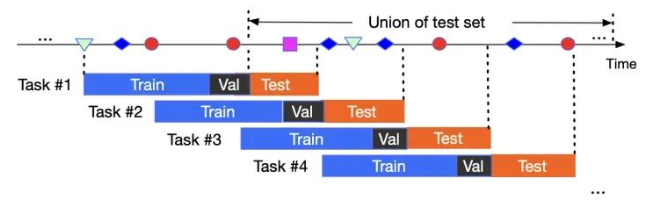
图3:任务的定义
03 方法
我们引入NLP领域的promptpool改进。"Promptpool"这个概念在中文中可以理解为“提示池”或者“命令池”机制。在机器学习的背景下,"promptpool"机制指的是一组用于提升模型性能的提示或命令,这些提示会作为输入的一部分提供给模型,引导或激励模型生成预期的输出。
例如,在基于transformer的语言模型(如GPT-3)中,promptpool机制可以指代一个包含多种不同提示(questions,命令,或者情景描述等)的集合,用于激发模型针对不同场景或任务产生相对应的回应。此前主要用于NLP领域,我们是第一个把这个概念引入时序领域的研究人员。
04 思路
我们用一系列可学习的promptpool来编码任务的信息,当新的任务来的时候,有一个抽取和匹配的机制。匹配的意义在于根据新的任务,找到编码相关信息的prompt,来指导新的任务的学习。
通过这个机制,我们把持续学习的概念引入到了时序模型中,以一种轻量级的方式让这个模型持续的学习,不断适应新的数据。
机器学习中的持续学习(ContinuousLearning,也称为终身学习或增量学习)是指让机器学习模型在完成初始训练之后,继续学习新的数据,从而不断更新和改进其性能和知识库的能力。这种学习方式让模型能够模仿人类在持续不断地获取新知识和技能的过程中所表现出的学习行为。
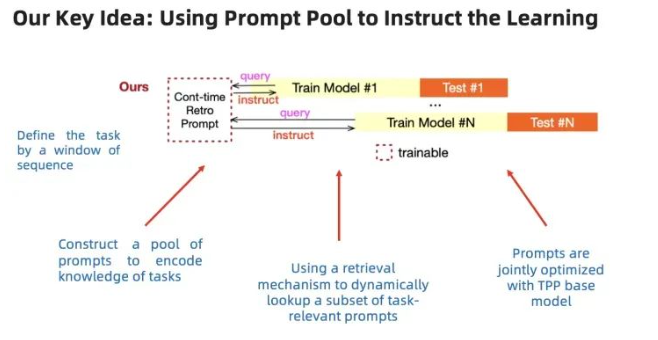
图四:整体思路
05 架构

图五:模型结构
06 训练
与NLP里面的方法已知,我们使用联合训练的方式对点过程的基础模型以及prompt同时进行优化。

图六:训练方法
07 预测

08 实验
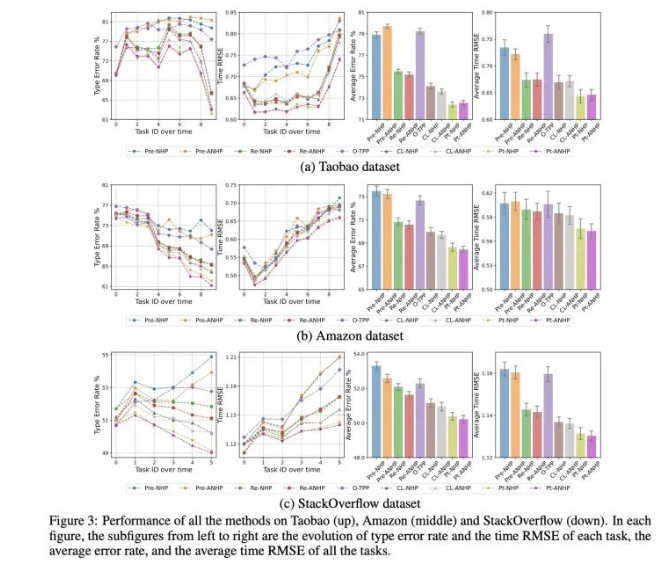
我们在三个开源数据集上完成了非常丰富的验证:
-
随着任务的累积,PromptTPP整体性能依然维持高位,而其他多个基准模型的预测性能均出现了不同程度的下降。
-
promptpool的引入,只带来了较小比例参数量的提升,并且实现了taskagnostic。我们的方法是一个非常轻量级的持续学习方式。
文章中在实验方面有非常多的细节验证,在此不做赘述。
09 结论
我们完成了首个把PromptPool机制首次引入时间序列领域的工作。代码、数据均已经开源,并将集成进开源库EasyTPP。
EasyTPPGitHub:
https://github.com/ant-research/EasyTemporalPointProcess
GitHub: https://github.com/Open-All-Scale-Causal-Engine/OpenASCE
JetBrains 全家桶 2024 首个大版本更新 (2024.1) 老乡鸡“开源”了 微软都打算付钱了,为何还是被骂“白嫖”开源? 【已恢复】腾讯云后台崩了:大量服务报错、控制台登入后无数据 德国也要“自主可控”,州政府将 3 万台 PC 从 Windows 迁移到 Linux deepin-IDE 终于实现了自举! Visual Studio Code 1.88 发布 好家伙,腾讯真把 Switch 变成了「思维驰学习机」 RustDesk 远程桌面启动重构 Web 客户端 微信基于 SQLite 的开源终端数据库 WCDB 迎来重大升级