


目前主流的加速思路包含算子优化、模型编译、模型缓存、模型蒸馏等,下面将简要介绍一下几种测试中用到的有一定代表性的开源方案。
▐ 算子优化:FlashAttention2
▐ 模型编译:oneflow / stable-fast
oneflow通过将模型编译为静态图,结合oneflow.nn.Graph内置的算子融合等加速策略,实现对模型推理的加速。优势在于对于基础SD模型只需一行编译代码即可完成加速、加速效果明显、生成效果差异小、可以结合其他加速方案(如deepcache)使用以及官方更新频率高等。缺点放到后面再说。
stable-fast也是基于模型编译的加速库,并结合了一系列算子融合的加速方法,但它的性能优化依赖于xformer、triton、torch.jit等工具。
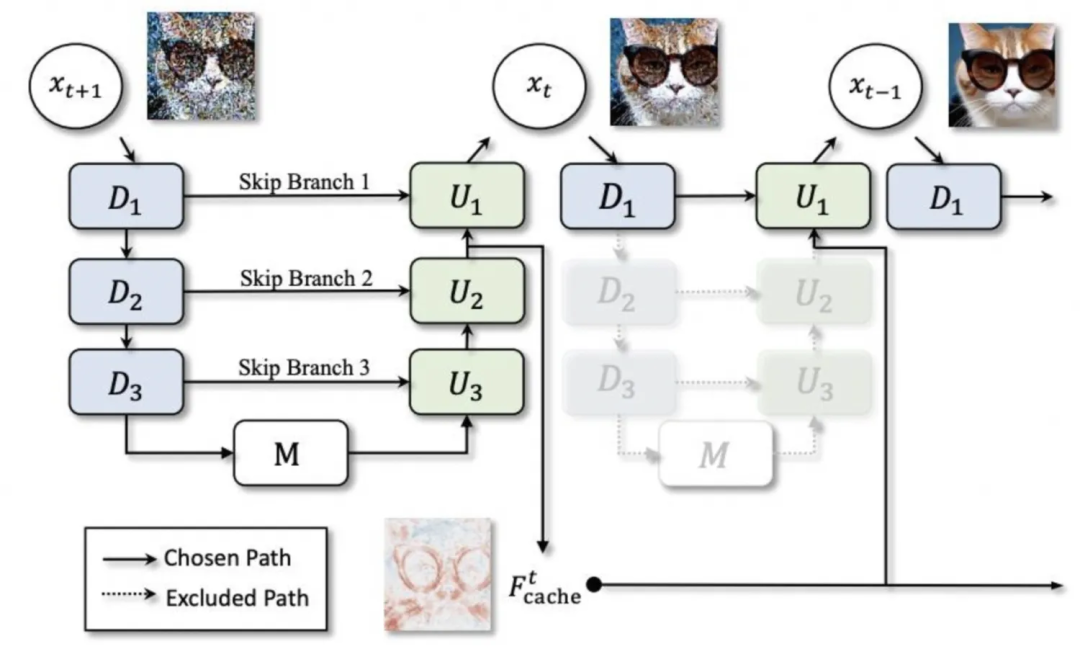
▐ 模型缓存:deepcache
▐ 模型蒸馏:lcm-lora
结合了lcm(Latent Consistency Model)与lora,lcm会对整个sd模型进行蒸馏,从而实现少步数推理,而lcm-lora借助了lora的形式,只对lora部分进行优化,这样既能够实现加速,也可以直接与常规的lora使用相结合。

SD1.5加速测试
▐ 测试环境
▐ 测试结果
-
通过固定seed的方式对生成的图片进行对比,可以发现oneflow编译能够降低rt 40%以上,且精度几乎没有损失,但在使用新的pipeline初次生成图片时,需要几十秒的编译时间作为warmup -
deepcache能够在此基础上额外降低15%~25%的rt,但同时随着缓存间隔的增大,生成效果差异也越来越明显 -
oneflow对使用了controlnet的SD1.5模型也同样有效 -
stable-fast对外部包的依赖比较严重,容易出现各种版本问题和外部工具报错,与oneflow类似,初次生成图片需要一定的编译时间,最终的加速效果也略逊于oneflow
▐ 详细对比数据
优化方法 |
平均生成耗时(秒) 512*512,50step |
加速效果 |
生成效果1 |
生成效果2 |
生成效果3 |
diffusers |
3.3701 |
0 |
|
|
|
diffusers+bf16 |
3.3669 |
≈0 |
|
|
|
diffusers+controlnet |
4.7452 |
|
|||
diffusers+oneflow编译 |
1.9857 |
41.08% |
|
|
|
diffusers+oneflow编译+controlnet |
2.8017 |
|
|||
diffusers+oneflow编译+deepcache |
interval=2:1.4581 |
56.73%(15.65%) |
|
|
|
interval=3:1.3027 |
61.35%(20.27%) |
|
|
||
interval=5:1.1583 |
65.63%(24.55%) |
|
|
||
diffusers+sfast |
2.3799 |
29.38% |















▐ 测试环境
▐ 测试结果
基础sdxl模型:
sdxl模型在固定seed的条件下,使用不同的加速方案似乎更容易影响生成图片的效果
oneflow只能降低24%的rt,但仍然能保证生成图片的精度
deepcache能够提供极其显著的加速,interval为2(即缓存只使用一次)时rt降低42%,interval为5时rt降低69%,但生成图片差异也很明显
lcm-lora显著降低了生图所需步数,能够极大程度地实现推理加速,但在使用预训练权重的情况下,稳定性极差,对步数非常敏感,无法保证稳定产出符合要求的图片
oneflow与deepcache/lcm-lora可以很好地结合起来使用
lora:
加载lora后,diffusers的推理速度明显降低,降低幅度与使用lora的类型和数量有关
deepcache依然有效,也依然存在精度问题,但在缓存间隔较低的情况下差异不大
使用lora的情况下,oneflow编译无法固定seed以保持与原版本一致
oneflow编译优化了加载lora后的推理速度,加载多个lora时,推理rt与未加载lora时相差不大,加速效果极其显著。例如,同时使用yarn+watercolor两个lora,rt能够降低约65%
oneflow对lora加载耗时有较小幅度的优化,但加载lora之后的设置操作耗时增加了
▐ 详细对比数据
优化方法 |
lora |
平均生成耗时(秒)512*512,50step |
lora加载耗时(秒) |
lora修改耗时(秒) |
效果1 |
效果2 |
效果3 |
diffusers |
无 |
4.5713 |
|
||||
yarn |
7.6641 |
13.9235 11.0447 |
0.06~0.09 根据配置的lora数量 |
||||
watercolor |
7.0263 |
||||||
yarn+watercolor |
10.1402 |
|
|||||
diffusers+bf16 |
无 |
4.6610 |
|
||||
yarn |
7.6367 |
12.6095 11.1033 |
0.06~0.09 根据配置的lora数量 |
||||
watercolor |
7.0192 |
||||||
yarn+ watercolor |
10.0729 |
||||||
diffusers+deepcache |
无 |
interval=2:2.6402 |
|
||||
yarn |
interval=2:4.6076 |
||||||
watercolor |
interval=2:4.3953 |
||||||
yarn+ watercolor |
interval=2:5.9759 |
|
|||||
无 |
interval=5: 1.4068 |
|
|||||
yarn |
interval=5:2.7706 |
||||||
watercolor |
interval=5:2.8226 |
||||||
yarn+watercolor |
interval=5:3.4852 |
|
|||||
diffusers+oneflow编译 |
无 |
3.4745 |
|
||||
yarn |
3.5109 |
11.7784 10.3166 |
0.5左右 移除lora 0.17 |
||||
watercolor |
3.5483 |
||||||
yarn+watercolor |
3.5559 |
|
|||||
diffusers+oneflow编译+deepcache |
无 |
interval=2:1.8972 |
|
||||
yarn |
interval=2:1.9149 |
||||||
watercolor |
interval=2:1.9474 |
||||||
yarn+watercolor |
interval=2:1.9647 |
|
|||||
无 |
interval=5:0.9817 |
|
|||||
yarn |
interval=5:0.9915 |
||||||
watercolor |
interval=5:1.0108 |
||||||
yarn+watercolor |
interval=5:1.0107 |
|
|||||
diffusers+lcm-lora |
4step:0.6113 |
||||||
diffusers+oneflow编译+lcm-lora |
4step:0.4488 |














AI试衣业务场景使用了算法在diffusers框架基础上改造的专用pipeline,功能为根据待替换服饰图对原模特图进行换衣,基础模型为SD2.1。
根据调研的结果,deepcache与oneflow是优先考虑的加速方案,同时,由于pytorch版本较低,也可以尝试使用较新版本的pytorch进行加速。
▐ 测试环境
A10 + cu118 + py310 + torch2.0.1 + diffusers0.21.4
图生图(示意图,仅供参考):
待替换服饰 |
原模特图 |
|
|


▐ 测试结果
pytorch2.2版本集成了FlashAttention2,更新版本后,推理加速效果明显
deepcache仍然有效,为了尽量不损失精度,可设置interval为2或3
对于被“魔改”的pipeline和子模型,oneflow的图转换功能无法处理部分操作,如使用闭包函数替换forward、使用布尔索引等,而且很多错误原因较难通过报错信息来定位。在进行详细的排查之后,我们尝试了改造原模型代码,对其中不被支持的操作进行替换,虽然成功地在没有影响常规生成效果的前提下完成了改造,通过了oneflow编译,但编译后的生成效果很差,可以看出oneflow对pytorch的支持仍然不够完善
最终采取pytorch2.2.1+deepcache的结合作为加速方案,能够实现rt降低40%~50%、生成效果基本一致且不需要过多改动原服务代码
▐ 详细对比数据
优化方法 |
平均生成耗时(秒) 576*768,25step |
生成效果 |
diffusers |
22.7289 |
|
diffusers+torch2.2.1 |
15.5341 |
|
diffusers+torch2.2.1+deepcache |
11.7734 |
|
diffusers+oneflow编译 |
17.5857 |
|
diffusers+deepcache |
interval=2:18.0031 |
|
interval=3:16.5286 |
|
|
interval=5:15.0359 |
|








目前市面上有很多非常好用的开源模型加速工具,pytorch官方也不断将各种广泛采纳的优化技术整合到最新的版本中。
我们在初期的调研与测试环节尝试了很多加速方案,在排除了部分优化效果不明显、限制较大或效果不稳定的加速方法之后,初步认为deepcache和oneflow是多数情况下的较优解。
但在解决实际线上服务的加速问题时,oneflow表现不太令人满意,虽然oneflow团队针对SD系列模型开发了专用的加速工具包onediff,且一直保持高更新频率,但当前版本的onediff仍存在不小的限制。
如果使用的SD pipeline没有对unet的各种子模块进行复杂修改,oneflow仍然值得尝试;否则,确保pytorch版本为最新的稳定版本以及适度使用deepcache可能是更省心且有效的选择。

相关资料
FlashAttention:
https://github.com/Dao-AILab/flash-attention
https://courses.cs.washington.edu/courses/cse599m/23sp/notes/flashattn.pdf
oneflow
https://github.com/Oneflow-Inc/oneflow
https://github.com/siliconflow/onediff
stable-fast
https://github.com/chengzeyi/stable-fast
deepcache
https://github.com/horseee/DeepCache
lcm-lora
https://latent-consistency-models.github.io/
pytorch 2.2
https://pytorch.org/blog/pytorch2-2/

我们是淘天集团内容技术AI工程团队,通过搭建完善的算法工程化一站式平台,辅助上千个淘宝图文、视频、直播等泛内容领域算法的工程落地、部署和优化,承接每日上亿级别的数字内容数据,支撑并推动AI技术在淘宝内容社交生态中的广泛应用。
本文分享自微信公众号 - 大淘宝技术(AlibabaMTT)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。