文章目录
前言
本篇文章主要讲解如何爬取豆瓣电影top250中的数据。
爬取豆瓣top250比较适合初学者用于练习和熟悉爬虫技能知识的简单实战项目,通过这个项目,可以让小白对爬虫有一个初步认识和了解。那么就让我们开始吧!
拓展内容
什么是爬虫?
爬虫(Spider)是一种自动化程序,用于在互联网上抓取和提取信息。它通过模拟人类浏览器的行为,访问网页并提取所需的数据。爬虫可以自动化地访问大量的网页,从中提取出有用的数据,如文本、图片、链接等。爬虫通常用于搜索引擎、数据挖掘、数据分析等领域。
遵守爬虫规则
爬虫在获取网页数据时,需要遵守以下几点,以确保不违反法律法规:
1. 遵守网站的 Robots 协议
在爬取网站数据之前,一定要查看并遵守网站的 Robots.txt 文件,了解哪些页面是可以被爬取的,哪些是禁止访问的。
2. 控制请求频率
爬虫发送的请求频率应该进行合理的控制,避免对目标网站服务器造成过大的负担,影响其他用户的正常访问。可以设置访问间隔时间或者使用并发控制手段来确保爬虫行为不会对网站正常运行产生影响。
3. 遵守网站的规则和条款
每个网站都有自己的规则和条款,使用爬虫工具时必须遵守这些规则,比如禁止对网站内容进行商业利用或者禁止绕过限制获取免费信息等。
4. 尊重个人隐私
在爬取数据的过程中,可能会获取到包含个人隐私信息的数据。处理这些数据时要严格遵守相关法律法规,并采取必要的安全措施保护用户的个人隐私。
5. 注意版权问题
在使用爬虫工具获取他人创作的内容时,要尊重原创者的版权,不得将他人的作品用于商业目的或未经授权的传播。
6. 避免对服务器造成过大负担
编写爬虫程序时,应尽量减少对目标网站服务器的负担,避免爬取过多无用或重复的数据,以免浪费服务器资源。
7. 不要滥用爬虫技术
明确自己使用爬虫的目的和范围,并遵循相应的法律法规,不得利用爬虫技术进行非法活动、侵犯他人权益或干扰正常网络秩序。
爬取流程
使用爬虫爬取数据的流程大致如下:
确定目标:首先,需要确定要爬取数据的目标网站或网页。在选择目标时,应考虑网站的结构、数据类型和反爬虫机制等因素。
发起请求:通过HTTP库向目标站点发起请求,即发送一个Request。请求可以包含额外的headers等信息,然后等待服务器响应。
获取响应内容:如果服务器能正常响应,会得到一个Response。Response的内容便是所要获取的内容,类型可能有HTML、Json字符串,二进制数据(图片、视频)等。
解析内容:得到的内容可能是HTML,可以用正则表达式,网页解析库进行解析。可能是二进制数据,可以做保存或者进一步处理。
存储数据:解析完成后,将数据存储到本地磁盘或数据库中,以便进一步处理或使用。在存储数据时,应考虑数据去重、清洗、格式转换等问题。如果数据量较大,还需要考虑使用分布式存储技术或云存储技术。
以上流程仅供参考,实际操作中需要根据具体需求和目标网站的特性进行调整。
项目流程图
这是本次要爬取豆瓣电影top250的具体的一个项目流程,我会根据这个图进行一 一讲解。

一、明确目标
在进行数据爬取时要先确定爬取目标的原因主要有以下几点:
1、明确需求:确定爬取目标可以帮助我们明确数据需求,从而有针对性地进行数据爬取。这有助于我们在有限的时间和资源内获取到最有价值的数据。
2、提高效率:明确爬取目标后,我们可以针对性地设计爬虫程序,减少不必要的数据抓取和处理工作。这将大大提高数据爬取的效率,节省时间和计算资源。
3、避免法律风险:在明确爬取目标后,我们可以确保只抓取与目标相关的数据,避免抓取无关或敏感数据,从而降低可能触犯法律的风险。
4、数据筛选和整理:明确爬取目标后,可以在爬取过程中对数据进行筛选和整理,以便于后续的数据分析和利用。
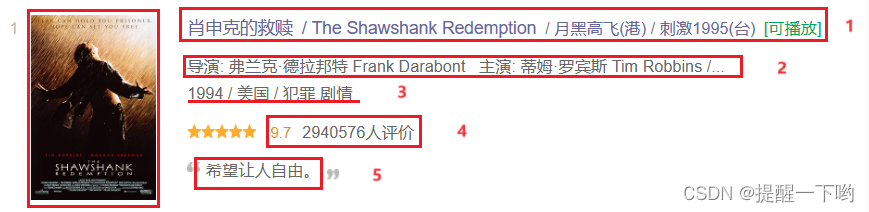
本次的爬取目标主要是:图片、电影名、导演及参演人员、年份、评分、评价人数、引言
二、安装并导入所需库
1.进行库的安装
pip install requests
pip install lxml
pip install csv
2.导入requests、lxml、csv库
在python中导入了名为requests的库。requests是一个流行的Python HTTP客户端库,用于发送所有种类的HTTP请求。
从lxml库中导入了etree模块。lxml是一个处理XML和HTML的Python库,etree模块提供了XML和HTML的解析功能。
导入csv库,用于读取和写入 CSV(逗号分隔值)格式的文件。
import requests
from lxml import etree
from csv
三、发送模拟请求
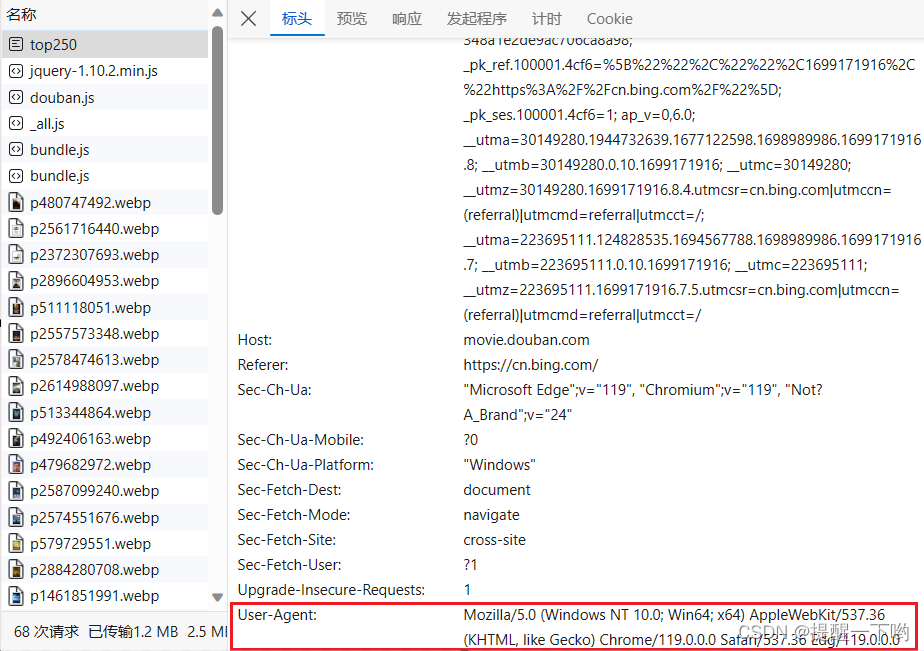
定义一个名为head的字典,包含了User-Agent头,用于模拟浏览器发送请求。
head = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36 Edg/118.0.2088.61'
}
这个信息可以在检查页面的请求头信息(Headers)里找到,如下所示:
四、定义函数,保存图片
下载图片并保存到本地,如果下载过程中出现异常,会打印出错误信息。
我们会先定义一个函数pic_img,用于下载图片。
再设置函数的两个参数:name表示图片的名称,url表示图片的链接。
在try-except块中,使用requests库的get方法发送GET请求获取图片的二进制数据。
使用open函数以二进制写入模式打开文件,并使用write方法将图片数据写入文件。
如果下载图片出现异常,打印错误信息。
注意:图片的保存位置要根据自己的一个路径位置进行设置哟
def pic_img(name,url):
try:
response = requests.get(url)# 发送GET请求获取图片数据
with open(f'C:/DEV/pycharm/workspace/test_001/{
name}.jpg', 'wb') as f:# 以二进制写入模式打开文件
f.write(response.content)# 将图片数据写入文件
except Exception as e:
print(f"Failed to download image: {
e}") # 如果出现异常,则打印错误信息
C:/DEV/pycharm/workspace/test_001/{name}.jpg是保存图片的文件路径。
五、实现翻页效果
这里会进行10次循环(豆瓣电影top250只有10页,每页有25个电影),每次循环的 i 乘以25赋值给cnt,用于控制每页显示的电影数量。
for i in range(10):
cnt = i * 25
url = f'https://movie.douban.com/top250?start={
cnt}&filter='
六、分析数据
使用开发者工具f12分别找到我们要爬取的数据位置,并复制xpath路径从而获取数据
-
电影名称

-
导演及参演人员

-
年份

-
评分

-
评价人数

-
引言

七、获取数据
遍历li_list列表中的每个li标签。进一步提取有用信息
引言这块有个小坑,就是有些电影没有引言,如果该xpath表达式匹配到了元素,代码将提取出匹配到的第一个元素的文本内容,并使用strip方法去除首尾空格,将结果赋值给introduc变量。如果xpath表达式没有匹配到元素,代码将引发索引超出范围的异常。

为了避免这种异常,我们使用了try-except块来捕获异常,并将introduc变量赋值为空字符串。
for li in li_list:
# 图片
img_url = li.xpath('.//img/@src')[0].strip()
# 名称
name = li.xpath('./div/div[2]/div[1]/a/span[1]/text()')[0].strip()
# 导演
info = li.xpath('./div/div[2]/div[2]/p[1]/text()[1]')[0].strip()
# 年份
year_type = li.xpath('./div/div[2]/div[2]/p[1]/text()[2]')[0].strip()
# 评分
score = li.xpath('./div/div[2]/div[2]/div/span[2]/text()')[0].strip()
# 评价人数
num = li.xpath('./div/div[2]/div[2]/div/span[4]/text()')[0].strip()
# 引言
try:
introduc = li.xpath('./div/div[2]/div[2]/p[2]/span/text()')[0].strip()
except:
introduc = ''
八、存储数据
使用open函数将处理的数据保存为CSV文件,使用writerow方法将电影的表头写入CSV文件。
注意:文件的保存位置要根据自己的一个路径位置进行设置哟
header = ['name', 'info', 'year_type', 'score', 'num', 'introduc'] # 设置表头
with open('C:\DEV\pycharm\study/task_3\\movies.csv', 'a', encoding='utf-8', newline='') as f:
writer = csv.writer(f)
writer.writerow(header) # 写入表头
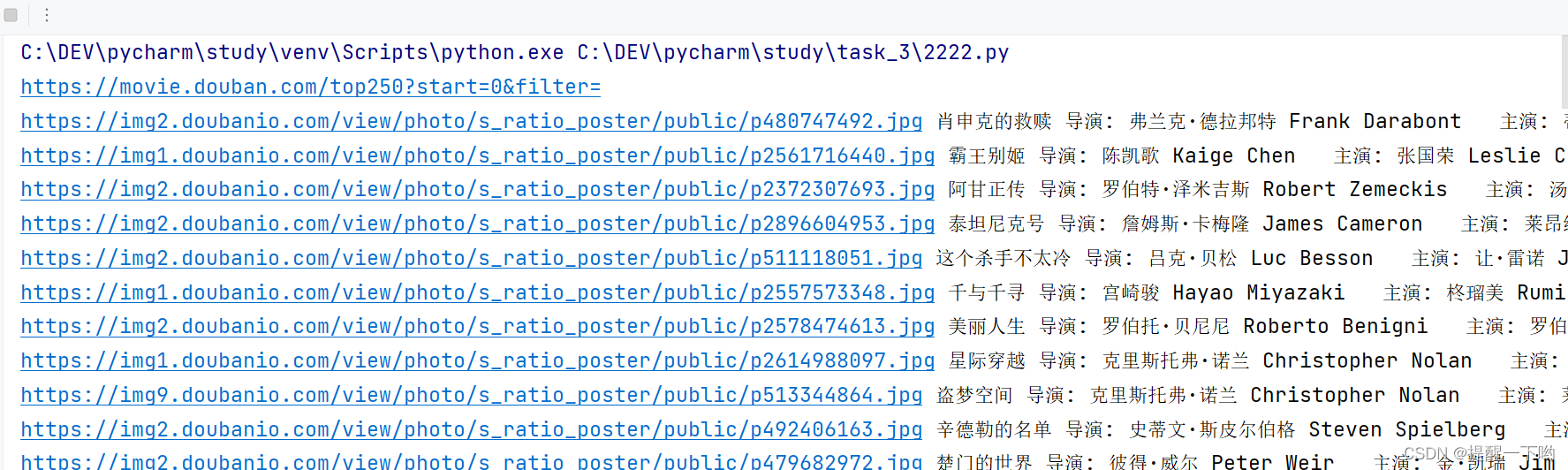
执行结果


总结
总之,爬虫需要遵守相关法律法规和网站的使用条款,合理抓取数据,避免侵犯网站的知识产权和干扰网站的正常运行,以确保爬虫的合法性和可持续性。以上就是本篇文章的所有内容,希望能够帮助到大家!