作者 | 数源AI 编辑 | 自动驾驶之心
原文链接:https://zhuanlan.zhihu.com/p/2147759445
点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
本文只做学术分享,如有侵权,联系删文

DINOv2 是 Meta AI 推出的一款计算机视觉模型,旨在提供一个基础模型,类似于自然语言处理领域已经普遍存在的基础模型。
在这篇文章中,我们将解释在计算机视觉中成为基础模型的意义,以及为什么 DINOv2 能够被视为这样的模型。
DINOv2 是一个非常大的模型(相对于计算机视觉领域),拥有十亿个参数,因此在训练和使用时会面临一些严峻的挑战。本文将回顾这些挑战,并介绍 Meta AI 的研究人员如何通过自监督学习和蒸馏技术克服这些问题。即使你不熟悉这些术语,也不用担心,我们会在后面解释。首先,让我们了解 DINOv2 提供了什么,使它成为计算机视觉领域的基础模型。
什么是基础模型?
在没有基础模型的时代,必须先找到或创建一个数据集,然后选择一种模型架构,并在该数据集上训练模型。你所需的模型可能非常复杂,训练过程可能很长或很困难。
于是,DINOv2 出现了,这是一种预训练的大型视觉Transformer(ViT)模型,这是计算机视觉领域中一种已知的架构。它表明你可能不再需要一个复杂的专用模型。
例如,假设我们有一张猫的图片(下图左侧的那张)。我们可以将这张图片作为输入提供给 DINOv2。DINOv2 会生成一个数字向量,通常称为嵌入或视觉特征。这些嵌入包含对输入猫图片的深层理解,一旦我们获得这些嵌入,就可以将它们用于处理特定任务的小型模型中。例如,我们可以使用一个模型进行语义分割(即对图像中的相关部分进行分类),另一个模型估计图中物体的深度。这些输出示例来自 Meta AI 对 DINOv2 的演示。
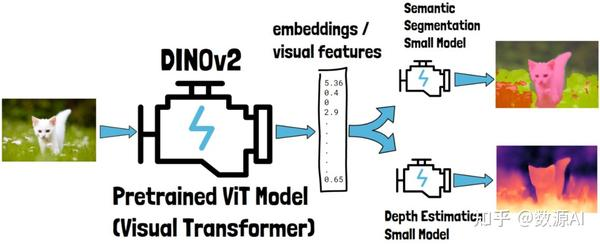
DINOv2 的另一个重要特性是,在训练这些任务特定的模型时,DINOv2 可以被冻结,换句话说,不需要进行微调。这大大简化了简单模型的训练和使用,因为 DINOv2 可以在图像上执行一次,输出结果可以被多个模型使用。与需要微调的情况不同,那样每个任务特定的模型都需要重新运行微调后的 DINOv2。此外,微调这样的大型模型并不容易,需要特定的硬件,而这种硬件并非人人都能使用。

如何使用DINOv2?
我们不会深入探讨代码,但如果你想使用 DINOv2,可以通过 PyTorch 代码简单加载它。以下代码来自 DINOv2 的 GitHub 页面。我们可以看到,有几种不同大小的模型版本可供加载,因此你可以根据自己的需求和资源选择合适的版本。即使使用较小版本,准确率的下降也不明显,尤其是使用中等大小的版本时,这非常有用。
模型蒸馏
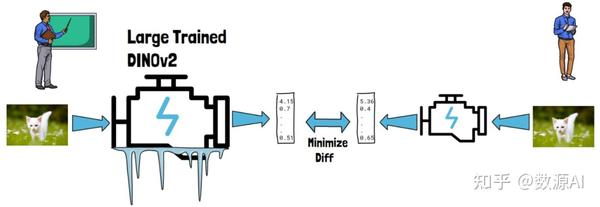
蒸馏指的是将一个大型训练模型的知识转移到一个新的小型模型中。令人有趣的是,在 DINOv2 中,研究人员通过这种方式得到了比直接训练小型模型更好的结果。具体方法是使用预训练的 DINOv2 教授新的小型模型,例如给定一张猫的图片,DINOv2 和小型模型都会生成嵌入,蒸馏过程会尽量减少两者生成嵌入的差异。需要注意的是,DINOv2 保持冻结,只有右侧的小型模型在发生变化。
这种方法通常被称为师生蒸馏,因为这里的左侧充当老师,右侧充当学生
在实践中,为了从蒸馏过程中获得更好的结果,我们不会只使用一个学生模型,而是同时使用多个学生模型。每个学生模型会接收相同的输入并输出结果。在训练过程中,所有学生模型的结果会进行平均,最终形成一个经过蒸馏的毕业模型。

在 DINOv2 中,模型的规模相比之前版本大幅增加,这就需要更多的训练数据。这引出了一个话题,即使用大规模精心整理的数据进行自监督学习。这种方法帮助模型无需大量的人工标注数据,依靠数据本身进行有效的学习,尤其适合像 DINOv2 这样的大模型训练需求。
利用大量精选数据进行自我监督学习
首先,什么是自监督学习?简单来说,它指的是我们的训练数据没有标签,模型只从图像中学习。第一版 DINO 也使用了自监督学习技术。没有数据标注是否会更容易增加训练数据的规模?然而,以前尝试通过自监督学习增加未经整理的数据规模,反而导致了质量下降。
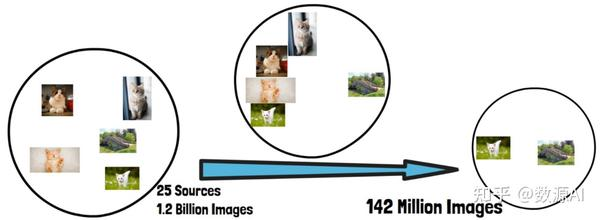
在 DINOv2 中,研究人员构建了一个自动化流程,用来创建精心整理的数据集,帮助他们取得了相较其他自监督学习模型的最新成果。他们从 25 个数据来源中收集了 12 亿张图像,最终从中提取了 1.42 亿张图像用于训练。这种数据筛选策略提升了模型性能。
因此,这个流程包含多个过滤步骤。例如,在未经整理的数据集中,我们可能会找到大量猫的图片以及其他图像。如果直接在这些数据上训练,可能会导致模型在理解猫方面表现优异,但在泛化到其他领域时表现不佳。
因此,这个流程的其中一步是使用聚类技术,将图像根据相似性进行分组。然后,他们可以从每个组中抽取相似数量的图像,创建一个规模更小但更多样化的数据集。这种方法确保了数据的广泛代表性,避免模型过度专注于某些特定类别如猫的图像。
更好的像素级理解
使用自监督学习的另一个好处是对像素级别的理解更强。目前计算机视觉中常见的方法是使用文本引导的预训练。例如,一张猫的图片可能会附带类似“草地上一只白色小猫”的描述。这种方法结合了图像和文本信息,但自监督学习能够更深入地理解图像本身,而无需依赖文本标签。
然而,这类模型会将图像和文本一起作为输入,但描述文本可能会遗漏一些信息,例如猫在走路或图片中的小白花,这可能会限制模型的学习能力。

通过 DINOv2 和自监督学习,模型在像素级别信息的学习上展现了惊人的能力。例如,图片中的多个马匹,即使在不同图片中,或者图片中的马很小,DINOv2 都能将相同身体部位标注为相似的颜色,非常令人印象深刻。这展示了 DINOv2 对细节的深度理解能力。

『自动驾驶之心知识星球』欢迎加入交流!重磅,自动驾驶之心科研论文辅导来啦,申博、CCF系列、SCI、EI、毕业论文、比赛辅导等多个方向,欢迎联系我们!

① 全网独家视频课程
端到端自动驾驶、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)

② 国内首个自动驾驶学习社区
国内外最大最专业,近4000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(端到端自动驾驶、世界模型、仿真闭环、2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦感知、定位、融合、规控、标定、端到端、仿真、产品经理、自动驾驶开发、自动标注与数据闭环多个方向,目前近60+技术交流群,欢迎加入!扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

④【自动驾驶之心】全平台矩阵
