作者 | 谭日成 编辑 | 自动驾驶之心
原文链接:https://zhuanlan.zhihu.com/p/2518215740
点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
本文只做学术分享,如有侵权,联系删文
Weijian Sun:Imitation Is Not Enough - 在运动规划中克服模仿学习的局限性
DILab决策实验室:Diffusion Model + RL 系列技术科普博客(1):Diffuser
北方的郎:深入浅出讲解Stable Diffusion原理,新手也能看明白
自动驾驶车辆是一种特殊的机器人,而机器人领域中用来做motionplanning目前比较火的一个分支是扩散策略
所以我们来看看相关的论文
HE-DRIVE:HUMAN-LIKEEND-TO-ENDDRIVING WITH VISION LANGUAGE MODELS(第一篇是直接用于端到端自动驾驶的,来自于2024年10月,地平线)

大概思想就是用条件扩散-带主车历史状态信息,来生成未来动作序列分布,用VLM给输出的动作序列打分,最终达成驾驶任务,提升时序一致性
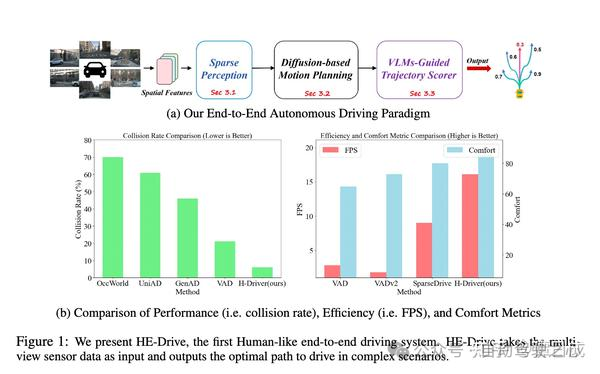
这里主要关注diffusion policy部分:
时序一致性不是由模型保证的,而是后处理rulebased打分保证的
diffusion过程中perception的token特征是固定的,没有加入到学习过程,相当于先学好了token嵌入,再学习diffusion
diffusion本身出的轨迹没有概率,是后面vlm出的,直觉上个人觉得这是一个优化点,用vlm来打分有点牵强,违背了diffusion生成模型的精髓
Diffusion policy:Visuomotor policy learning via action diffusion(Shuran Song团队,开山鼻祖论文)
王建明:Diffusion Policy—基于扩散模型的机器人动作生成策略
NoMaD:GoalMaskedDiffusionPoliciesforNavigationandExploration(来自于ucberkly大学,地平线文章中引用)
GitHub - robodhruv/visualnav-transformer: Official code and checkpoint release for mobile robot foundation models: GNM, ViNT, and NoMaD.
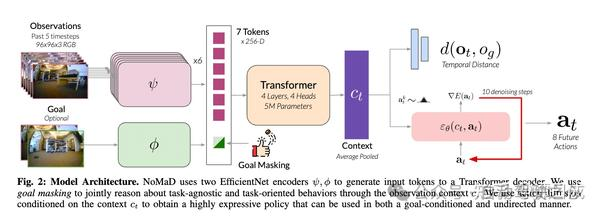
主要思想:前面从输入图片到获取Ct的架构参考第三篇文章ViNT,后面动作多模态用了diffusion策略,相比于图像生成,该处引入了Ct作为condition,所以是带条件的去噪。
这里主要关注的其实就是怎么学习到:
动作离散采样的规则,因为动作空间其实是连续的?
答:diffusion学的是一个分布不牵涉到action,action本身可以连续也可以离散,取决于自己的定义,所以这里的action可以在连续空间里采样,组成动作序列!
文中提到去噪过程中,Ct是被排除在外的,这个排除在外是指的先训练好Ct,去噪时固定住前面的参数?只学去噪的参数?
答:从代码里看就是将去噪作为单独的过程学习,其实并没有把Ct作为条件去噪!

自己对于文中的一些疑问:
动作序列本身也是条件性的是一个MDP过程,建模过程没有体现,这个是不是考虑进去会对效果有提升!
Ct在去噪时为什么要排除在外,这样是不是割裂了diffusion和环境,我对于学习的效果是有质疑的
具体diffusion的细节其实文中用了diffusion policy封装好的实现,具体为

def train_nomad(
model: nn.Module,
ema_model: EMAModel,
optimizer: Adam,
dataloader: DataLoader,
transform: transforms,
device: torch.device,
noise_scheduler: DDPMScheduler,
goal_mask_prob: float,
project_folder: str,
epoch: int,
alpha: float = 1e-4,
print_log_freq: int = 100,
wandb_log_freq: int = 10,
image_log_freq: int = 1000,
num_images_log: int = 8,
use_wandb: bool = True,
):
"""
Train the model for one epoch.
Args:
model: model to train
ema_model: exponential moving average model
optimizer: optimizer to use
dataloader: dataloader for training
transform: transform to use
device: device to use
noise_scheduler: noise scheduler to train with
project_folder: folder to save images to
epoch: current epoch
alpha: weight of action loss
print_log_freq: how often to print loss
image_log_freq: how often to log images
num_images_log: number of images to log
use_wandb: whether to use wandb
"""
goal_mask_prob = torch.clip(torch.tensor(goal_mask_prob), 0, 1)
model.train()
num_batches = len(dataloader)
uc_action_loss_logger = Logger("uc_action_loss", "train", window_size=print_log_freq)
uc_action_waypts_cos_sim_logger = Logger(
"uc_action_waypts_cos_sim", "train", window_size=print_log_freq
)
uc_multi_action_waypts_cos_sim_logger = Logger(
"uc_multi_action_waypts_cos_sim", "train", window_size=print_log_freq
)
gc_dist_loss_logger = Logger("gc_dist_loss", "train", window_size=print_log_freq)
gc_action_loss_logger = Logger("gc_action_loss", "train", window_size=print_log_freq)
gc_action_waypts_cos_sim_logger = Logger(
"gc_action_waypts_cos_sim", "train", window_size=print_log_freq
)
gc_multi_action_waypts_cos_sim_logger = Logger(
"gc_multi_action_waypts_cos_sim", "train", window_size=print_log_freq
)
loggers = {
"uc_action_loss": uc_action_loss_logger,
"uc_action_waypts_cos_sim": uc_action_waypts_cos_sim_logger,
"uc_multi_action_waypts_cos_sim": uc_multi_action_waypts_cos_sim_logger,
"gc_dist_loss": gc_dist_loss_logger,
"gc_action_loss": gc_action_loss_logger,
"gc_action_waypts_cos_sim": gc_action_waypts_cos_sim_logger,
"gc_multi_action_waypts_cos_sim": gc_multi_action_waypts_cos_sim_logger,
}
with tqdm.tqdm(dataloader, desc="Train Batch", leave=False) as tepoch:
for i, data in enumerate(tepoch):
(
obs_image,
goal_image,
actions,
distance,
goal_pos,
dataset_idx,
action_mask,
) = data
obs_images = torch.split(obs_image, 3, dim=1)
batch_viz_obs_images = TF.resize(obs_images[-1], VISUALIZATION_IMAGE_SIZE[::-1])
batch_viz_goal_images = TF.resize(goal_image, VISUALIZATION_IMAGE_SIZE[::-1])
batch_obs_images = [transform(obs) for obs in obs_images]
batch_obs_images = torch.cat(batch_obs_images, dim=1).to(device)
batch_goal_images = transform(goal_image).to(device)
action_mask = action_mask.to(device)
B = actions.shape[0]
# Generate random goal mask
goal_mask = (torch.rand((B,)) < goal_mask_prob).long().to(device)
obsgoal_cond = model("vision_encoder", obs_img=batch_obs_images, goal_img=batch_goal_images, input_goal_mask=goal_mask)
# Get distance label
distance = distance.float().to(device)
deltas = get_delta(actions)
ndeltas = normalize_data(deltas, ACTION_STATS)
naction = from_numpy(ndeltas).to(device)
assert naction.shape[-1] == 2, "action dim must be 2"
# Predict distance
dist_pred = model("dist_pred_net", obsgoal_cond=obsgoal_cond)
dist_loss = nn.functional.mse_loss(dist_pred.squeeze(-1), distance)
dist_loss = (dist_loss * (1 - goal_mask.float())).mean() / (1e-2 +(1 - goal_mask.float()).mean())
# Sample noise to add to actions
noise = torch.randn(naction.shape, device=device)
# Sample a diffusion iteration for each data point
timesteps = torch.randint(
0, noise_scheduler.config.num_train_timesteps,
(B,), device=device
).long()
# Add noise to the clean images according to the noise magnitude at each diffusion iteration
noisy_action = noise_scheduler.add_noise(
naction, noise, timesteps)
# Predict the noise residual
noise_pred = model("noise_pred_net", sample=noisy_action, timestep=timesteps, global_cond=obsgoal_cond)
def action_reduce(unreduced_loss: torch.Tensor):
# Reduce over non-batch dimensions to get loss per batch element
while unreduced_loss.dim() > 1:
unreduced_loss = unreduced_loss.mean(dim=-1)
assert unreduced_loss.shape == action_mask.shape, f"{unreduced_loss.shape} != {action_mask.shape}"
return (unreduced_loss * action_mask).mean() / (action_mask.mean() + 1e-2)
# L2 loss
diffusion_loss = action_reduce(F.mse_loss(noise_pred, noise, reduction="none"))
# Total loss
loss = alpha * dist_loss + (1-alpha) * diffusion_loss
# Optimize
optimizer.zero_grad()
loss.backward()
optimizer.step()
# Update Exponential Moving Average of the model weights
ema_model.step(model)
# Logging
loss_cpu = loss.item()
tepoch.set_postfix(loss=loss_cpu)
wandb.log({"total_loss": loss_cpu})
wandb.log({"dist_loss": dist_loss.item()})
wandb.log({"diffusion_loss": diffusion_loss.item()})
if i % print_log_freq == 0:
losses = _compute_losses_nomad(
ema_model.averaged_model,
noise_scheduler,
batch_obs_images,
batch_goal_images,
distance.to(device),
actions.to(device),
device,
action_mask.to(device),
)
for key, value in losses.items():
if key in loggers:
logger = loggers[key]
logger.log_data(value.item())
data_log = {}
for key, logger in loggers.items():
data_log[logger.full_name()] = logger.latest()
if i % print_log_freq == 0 and print_log_freq != 0:
print(f"(epoch {epoch}) (batch {i}/{num_batches - 1}) {logger.display()}")
if use_wandb and i % wandb_log_freq == 0 and wandb_log_freq != 0:
wandb.log(data_log, commit=True)
if image_log_freq != 0 and i % image_log_freq == 0:
visualize_diffusion_action_distribution(
ema_model.averaged_model,
noise_scheduler,
batch_obs_images,
batch_goal_images,
batch_viz_obs_images,
batch_viz_goal_images,
actions,
distance,
goal_pos,
device,
"train",
project_folder,
epoch,
num_images_log,
30,
use_wandb,
)ViNT: A Foundation Model for Visual Navigation非diffusion相关工作(第二篇文章提到,和第二篇的作者基本相同,应该是系列工作)-可以看出该团队在这个方向上做了挺多的内容的
主要思想是通过弱监督学习更多的领域知识,有助于zeroshot迁移到数据稀少的任务,提升效果。
loss如下,可以看出该方法把action和distance抽象成了离散分类策略:

Potential Based Diffusion Motion Planning
github.com/devinluo27/potential-motion-plan-release
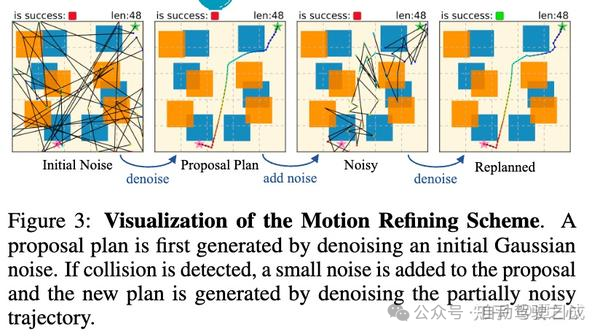
这张图比较好的展示了这个方法的效果:
可以将不同能量分布组合(黄色和蓝色)
能够通过diffuision学习到一个还不错能量值最低的轨迹
第2步学习的motionplanning可能还是会碰撞,在这个基础上replan,并进行更细致的去噪,从而有更好的规划效果
『自动驾驶之心知识星球』欢迎加入交流!重磅,自动驾驶之心科研论文辅导来啦,申博、CCF系列、SCI、EI、毕业论文、比赛辅导等多个方向,欢迎联系我们!

① 全网独家视频课程
端到端自动驾驶、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)

② 国内首个自动驾驶学习社区
国内外最大最专业,近4000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(端到端自动驾驶、世界模型、仿真闭环、2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦感知、定位、融合、规控、标定、端到端、仿真、产品经理、自动驾驶开发、自动标注与数据闭环多个方向,目前近60+技术交流群,欢迎加入!扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

④【自动驾驶之心】全平台矩阵
