使用Pytorch训练Kolmogorov-Arnold实现 MNIST 数字分类
**Kolmogorov-Arnold网络 (KAN)**,它是目前占主导地位的多层感知器 (MLP)架构的有前途的替代方案。
今天把代码应用到一个基本任务上,发现效果还不错,在特定的任务上可能有潜力,且可解释性可能更好。
KAN原理
在MLP中,一层中的每个节点/神经元都连接到下一层中的每个节点/神经元。
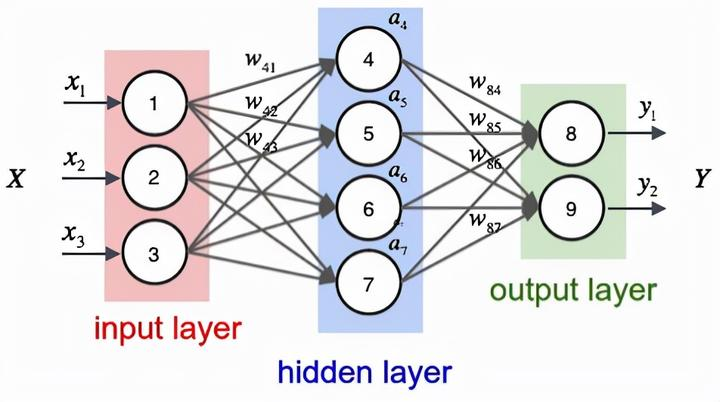
MLP 中的节点或神经元使用激活函数来捕获其输入中的非线性。
这些激活函数是固定且非线性的。
MLP 的灵感来自通用逼近定理。如果 MLP 的隐藏层有足够的神经元,它就可以将任何真实的 连续函数逼近到任何所需的精度。
MLP ( N(x)) 的这种近似可以在数学上描述如下
KAN 是受Kolmogorov-Arnold 表示定理(由俄罗斯数学家Vladimir Arnold和Andrey Kolmogorov提出)启发的神经网络。
该定理指出,每个多变量 连续函数可以用连续单变量函数的总和来表示。
简而言之,它告诉我们每个复杂的多变量函数都可以分解为更简单的一维函数。
该定理在数学上描述如下——
这个定理催生了KAN架构:
在最简单的形式中,KAN 类似于Kolmogorov-Arnold 表示定理方程,并且仅由两层组成。
第一层使用一组单变量函数对每个输入进行变换。
第二层对这些变换进行求和并输出最终预测。
但当扩展到学习复杂的现实世界函数时,KAN 与 MLP 一样由多个层组成,其中每一层的输出都是下一层的输入。
多层 KAN 包括 —
-
输入层 -
边缘(执行大部分计算的地方) -
节点
与每条边都有关联的权重参数的 MLP 不同,在 KAN 中,这些权重完全被可学习的单变量函数取代。
这些单变量函数使用B-Spline进行参数化。
KAN 中的节点只是对传入信号进行求和,而不是应用激活函数。
由于 KAN 中发生的所有操作都是可微分的,因此可以使用反向传播和传统损失函数来训练它们。
下表简要总结了 KAN 和 MLP 之间的差异。

值得注意的是,在参数数量相同的情况下,KAN 目前的训练速度比 MLP 慢 10 倍。
数据集和预处理
MNIST 数据集是手写数字的集合,是分类算法的标准基准。我们使用 PyTorch 的torchvision库来加载和预处理数据集。
import torchvision
import torchvision.transforms as transforms
import torch
# Load MNIST dataset
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
train_dataset = torchvision.datasets.MNIST(root='../DLdataset', train=True, transform=transform, download=False)
train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=64, shuffle=True, num_workers=4) # Adjust based on CPU cores
图像被归一化然后展平为一维数组,以满足 KAN 模型的输入要求。
模型
SimpleKAN 模型由多个线性层组成,用于处理单个像素并组合其输出以进行分类。以下是模型架构:
import torch
import torch.nn as nn
class SimpleKAN(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(SimpleKAN, self).__init__()
self.u_funcs = nn.ModuleList([nn.Linear(1, hidden_size) for _ in range(input_size)])
self.v_funcs = nn.ModuleList([nn.Linear(hidden_size, 1) for _ in range(input_size)])
self.w_funcs = nn.Linear(input_size, output_size)
def forward(self, x):
u_outputs = [torch.relu(u(x[:, i:i+1])) for i, u in enumerate(self.u_funcs)]
v_outputs = [v(u) for v, u in zip(self.v_funcs, u_outputs)]
stacked_v = torch.cat(v_outputs, dim=1)
output = self.w_funcs(stacked_v)
return output
实例化模型:
input_size = 28 * 28
hidden_size = 128
output_size = 10
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
kan = SimpleKAN(input_size=input_size, hidden_size=hidden_size, output_size=output_size).to(device)
超参数和优化器设定:
该模型采用交叉熵损失函数和 Adam 优化器
import torch.optim as optim
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(kan.parameters(), lr=0.001)
scaler = torch.cuda.amp.GradScaler()
训练:
num_epochs = 10
training_losses = []
for epoch in range(num_epochs):
epoch_loss = 0.0
for batch in train_loader:
inputs, targets = batch
inputs = inputs.view(inputs.size(0), -1).to(device) # Flatten images and move to GPU
targets = targets.to(device)
kan.train()
optimizer.zero_grad()
with torch.cuda.amp.autocast():
outputs = kan(inputs)
loss = criterion(outputs, targets)
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
epoch_loss += loss.item()
average_loss = epoch_loss / len(train_loader)
training_losses.append(average_loss)
print(f'Epoch [{epoch + 1}/{num_epochs}] Loss: {average_loss:.4f}')
这里训练了10个epoches,即使用了GPU,训练还是很慢,这是KAN的缺点
import os
import matplotlib.pyplot as plt
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
plt.figure(figsize=(10, 5))
plt.plot(range(num_epochs), training_losses, label='Training Loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.title('Training Loss Over Epochs')
plt.legend()
plt.show()
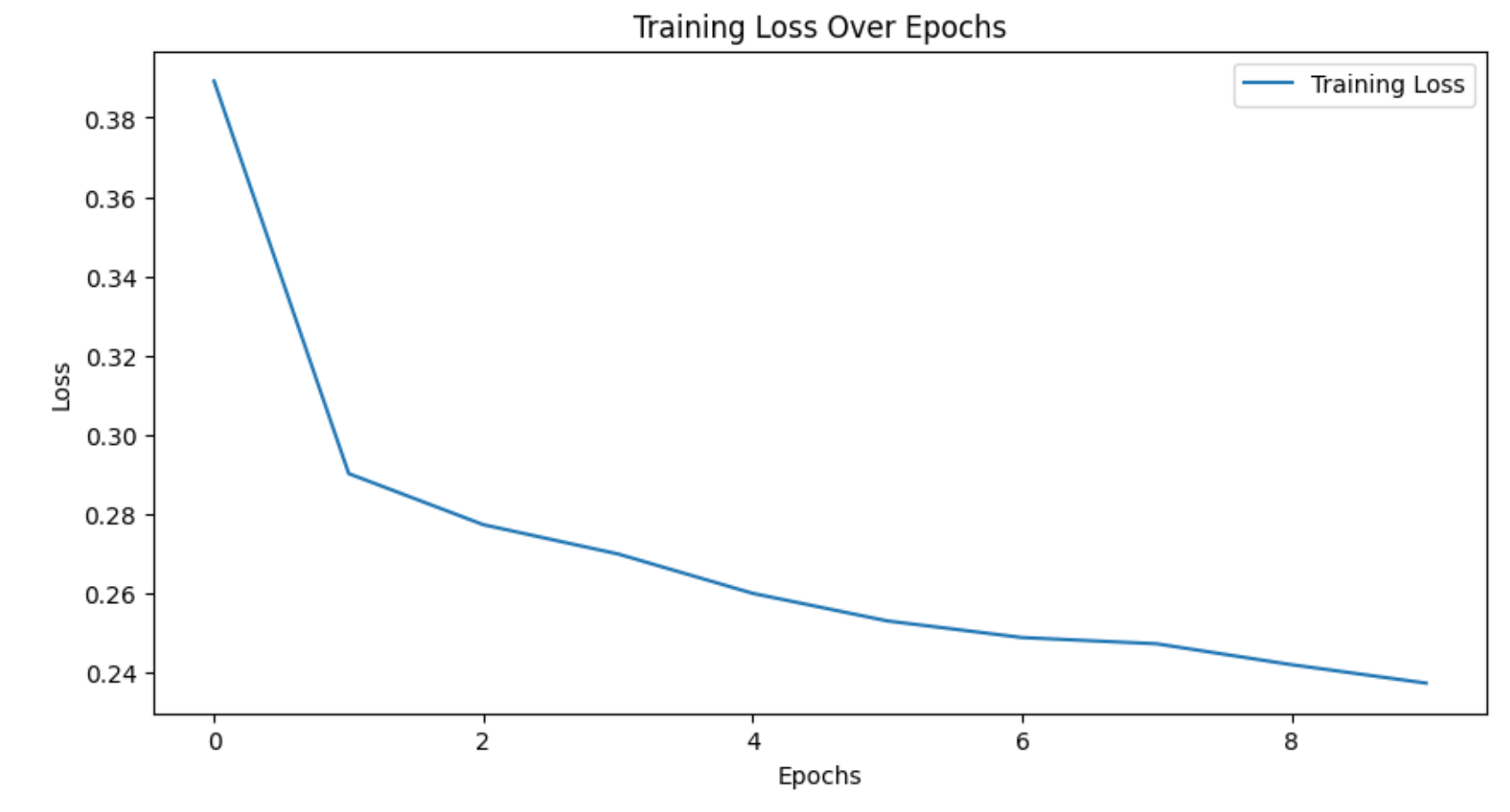
如图所示,基本收敛。
模型结果
correct = 0
total = 0
with torch.no_grad():
for images, labels in train_loader:
images = images.view(images.size(0), -1).to(device)
labels = labels.to(device)
outputs = kan(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
accuracy = correct / total
print(f'Accuracy: {accuracy * 100:.2f}%')

准确率有93%,看起来不错,但:
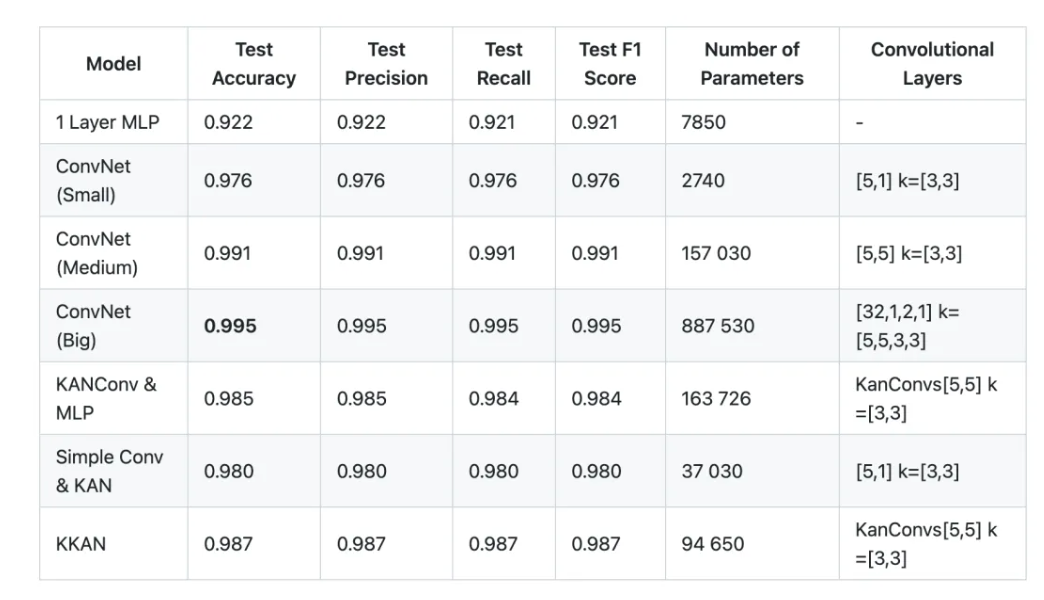
精确度仅仅超过了一层的MLP,距离一些卷积神经网络的98%,99%准确率还有一定距离。
本文由 mdnice 多平台发布