一、NoSQL概念
1、数据库分类
关系型数据库:MySQL、Oracle、SqlServer、DB2
非关系型数据库(NoSQL):Redis、MongoDB
2、NoSQL与SQL差异
- 结构上的差异:
关系型数据库是严格结构化的:存入的数据都有固定格式(数据类型、约束等等)
非关系型数据库没有非常严格的结构:存入的数据有键值型、文档型(一行一个json数据)、图类型(存入数据看作节点) - 关联上的差异
关系型数据库可能有表之间的主外键关联,不能随便删除
非关系型数据库则没有关联,一般是通过json数据的嵌套全部存储了 - 关系型数据库操作数据采用SQL语言;非关系型没有SQL语言,固定命令,缺点不同库的命令不同,要学习
- 关系型满足事务四大特性的;非关系型不能全部满足事务四大特性
- 关系型基本都是磁盘存储数据;非关系型大都是内存存储数据
3、什么时候用哪个?
如果数据结构相对固定,将来不怎么变更,对安全性,性能要求较高就使用关系型数据库;
再结合使用非关系型数据库,将表中冗余的其他表字段属性存在非关系型数据库。
比如订单主表数据存在关系型数据库,多个订单商品详细表存在Redis
二、Redis介绍
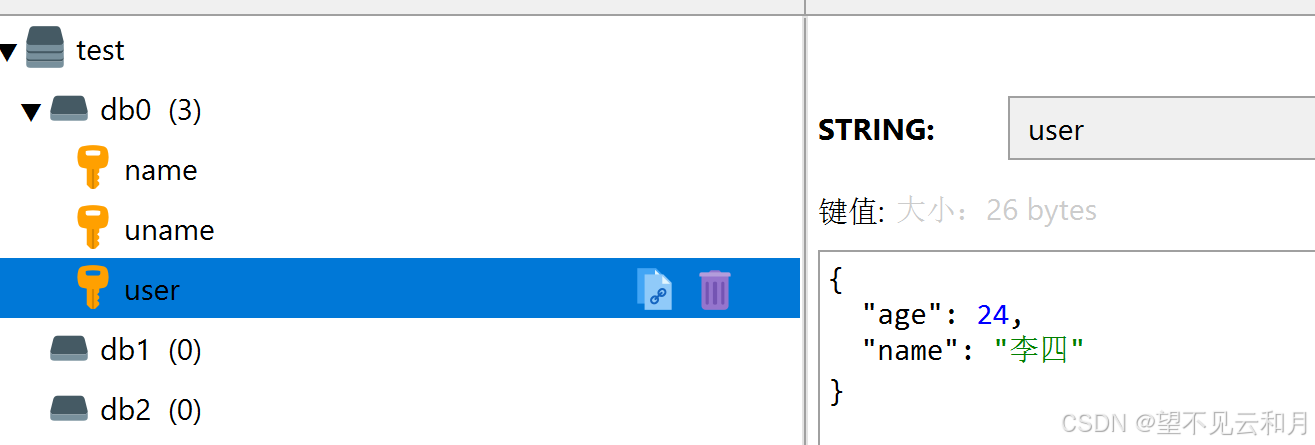
Redis是基于内存的键值型NoSQL数据库,里面存的都是键值对
1、特征
- 键值型:value支持多种数据结构,key是字符串
- 单线程:每个命令具有原子性,执行时不会有其他命令插进来,安全;Redis6的多线程仅仅是对于网络请求处理,而不是命令
- 低延迟,速度快(因为基于内存)
- 支持数据持久化,定期将数据从内存持久化到磁盘
- 支持主从集群(从节点可以备份主节点的数据),分片集群(提高存储上限)
2、支持的数据结构
key就是string,value支持多种数据结构,常见的有以下五种
- string
- hash:哈希表用字符串的形式描述——
{name : "张三", age : 23} - list:有序的集合,本质是链表——
[ A<->B<->C<->D ] - set:无序的集合
{A, B, C} - SortedSet:
{A : 1, B : 2, C : 3}
三、通用命令
在Redis的命令行(redis-cli)输入:help @generic追乃瑞可,查询所有基础通用命令
help 命令名称:就可以查看该命令的用法
# 连接到 Redis 服务器
redis-cli
# 查看符合模板的键,生产环境不建议使用,数据量大,查询慢占用服务器资源
keys pattern
# 删除键 可以删多个,后面的如果不存在也不会报错,会将前面存在的删掉返回删除的数量
DEL key1, key2, key3...
# 检查键是否存在
EXISTS key
# 给key设置一个有效期,到期自动删掉这个key(单位:秒)
EXPIRE key 60
# 查看key的剩余有效期,单位秒
TTL key
四、不同类型的常用命令
1、string
# 设置字符串
SET key "value"
# 设置多个
MSET
# 获取字符串
GET key
# 获取多个
MGET
# 递增1
INCR counter
# 递增num
INCRBY counter num
# 递减数值
DECR counter
DECRBY counter num
# 先判断,如果不存在,则添加字符串
SETNX key "value"
# 添加键值对,并指定有效期
SETEX key 60 "value"
2、hash
- hash类型,也叫散列,是一个无序字典,是field-value形式(就是键值对),就不需要用json格式了
- 命令语法:所有命令前加H
HSET key field "value"
HGET key field
3、list
- 类似与LinkedList,可以看作双向链表。可以正向检索,也可以反向检索
- 有序,可重复,插入删除快,查询慢;用于存放有序的数据集合
3.1 常见命令
# 从左侧推入元素
LPUSH key "value1"...
# 弹出左侧第一个元素
LPOP key
# 从右侧推入元素
RPUSH key "value2"...
# 弹出右侧第一个元素
RPOP key
# 获取列表范围内元素
LRANGE key start end
3.2 用list结构模拟栈、队列、阻塞队列
模拟栈:先进后出,入口和出口在同一边。用LPUSH存,LPOP取
模拟队列:先进先出,入口出口不在同一边。用LPUSH存,RPOP取
4、set
- 与HashSet特征类似,无序、元素不重复、查找快
# 添加元素到集合
SADD key "value1"
# 获取集合所有元素
SMEMBERS key
# 移除集合中的元素
SREM key "value1"
# 检查元素是否在集合中
SISMEMBER key "value1"
# 返回集合中的元素个数
SCARD key
5、SortedSet有序set集合
- 类似于TreeSet,可排序,不重复,查询快
- 按照评分(scope)排序,scope是数字
# 添加元素到有序集合
ZADD key scope "value1"
ZADD key scope "value2"
# 获取有序集合范围内的元素
ZRANGE key start end
# 获取元素的评分
ZSCORE key "value1"
# 移除有序集合中的元素
ZREM key "value1"
五、key的层级格式
如何区分不同的key,key是唯一的,但是redis没有table的字段概念,如何区分不同类型的key呢?
比如用户和商品的id都是1。
解决:redis的key允许多个单词拼接形成层级结构,比如user:id、product:id
如果value是一个Java对象,将其序列化为json字符串存储

六、Java操作Redis
1、操作Redis的客户端库
用于操作Redis的客户端库有两种:Jedis、lettuce(来特斯)
- Jedis以命令作为方法名称,简单实用,但是线程不安全
- lettuce实现了同步,是线程安全的
- SpringData整合了Jedis和lettuce
2、Jedis
2.1 引入依赖
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>3.7.0</version>
</dependency>
2.2 建立连接
- 获取Jedis的对象:传入ip地址和端口号。端口默认是6379
- 设置密码:如果没设置密码,就不要写这一步
- 选择库:Redis默认提供了16个库,从0-15,选择一个进行操作
2.3 使用
使用比较灵活,比如可以用来做购物车,以redis做中间件存储数据,在不同的访问请求中共享数据;比如在购物车中商品数量变化的不同控制方法中给库里增删数据。
jdeis对象调用的方法都是命令的名字
2.4 释放资源
2.5 示例
2.5.1 存入数据
public static void main(String[] args) {
/**
* 1、建立连接
*/
//获取对象
Jedis jedis = new Jedis("127.0.0.1", 6379);;
/**设置密码,没设置密码就可以不写
jedis.auth("123456");
*/
//选择库
jedis.select(0);
/**
* 2、使用
*/
//存入数据
String res = jedis.set("name", "zhangsan");//返回值是存入是否成功
System.out.println(res); //ok
/**
* 3、关流
*/
if (jedis!=null){
jedis.close();
}
}
2.5.2 取出数据
public static void main(String[] args) {
/**
* 1、建立连接
*/
//获取对象
Jedis jedis = new Jedis("127.0.0.1", 6379);;
/**设置密码,没设置密码就可以不写
jedis.auth("123456");
*/
//选择库
jedis.select(0);
/**
* 2、使用
*/
//拿出数据
String value = jedis.get("name");
System.out.println("拿出来了"+value);
/**
* 3、关流
*/
if (jedis!=null){
jedis.close();
}
}
3、Jedis连接池
Jedis本身线程不安全,频繁创建和销毁也会损耗性能,因此使用Jedis连接池代替原始使用
3.1 创建JedisPoolConfig对象
设置连接池参数,最大连接数,最大空闲数,最大等待时间等等
3.2 创建JedisPool对象
3.3 getResource()获取连接
3.4 使用示例
public static void main(String[] args) {
JedisPoolConfig config = new JedisPoolConfig();
config.setMaxTotal(8);//最大连接数
config.setMaxIdle(8);//最大空闲连接
config.setMaxWaitMillis(100);//最大等待时间
config.setMinIdle(0);//最小空闲连接。超过最大空闲时间,就关闭地剩下几个
JedisPool jedisPool = new JedisPool(config, "127.0.0.1", 6379, 1000);
Jedis jedis = jedisPool.getResource();
jedis.select(0);
jedis.set("name", "zhangsan");
if (jedis!=null){
jedis.close();//这里是将连接归还给连接池,而不是销毁
}
}
七、SpringDataRedis
1、优点
SpringData集成了Jedis和Lettuce。主要的提升有
- 提供了RedisTemplate统一的API来操作Redis,模板对象封装了这些方法获取对象:
opsForValue()、opsForHash()、opsForList()、opsForSet()、opsForZSet()
返回的对象都是ValueOperations、HashOperations…;封装了对Redis的操作 - 支持JSON、Java对象的序列化和反序列化(java对象和redis数据相互转换)
- 实现了控制反转思想,解耦。不用我们创建Jedis或者JedisPool的对象
2、使用步骤
2.1 创建项目勾选依赖
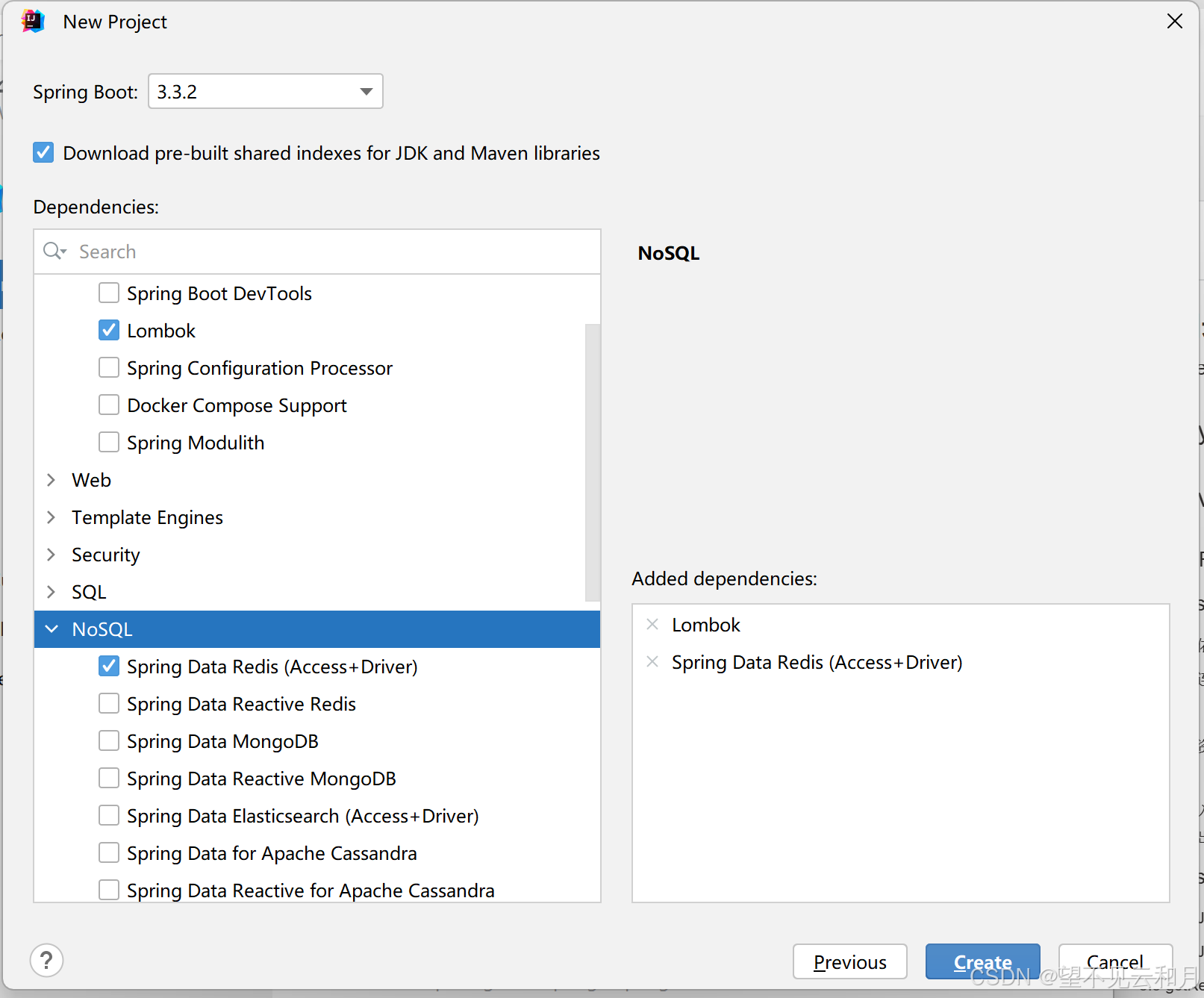
2.2 引入pool的依赖
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
</dependency>
2.3 编写配置文件
包括redis的ip和端口;使用的连接池配置
spring.redis.host=127.0.0.1
spring.redis.port=6379
spring.redis.jedis.pool.max-active=8
spring.redis.jedis.pool.max-idle=8
spring.redis.jedis.pool.min-idle=0
spring.redis.jedis.pool.max-wait=-1
# spring.redis.jedis~ 是jedis的连接池
# spring.redis.lettuce.pool~ 是lettuce的连接池
2.4 JSON序列化工具
redisTemplate默认使用jdk序列化器,以二进制存到了数据库,key与value就不好取了,乱码,可读性差
2.4.1 配置类设置
@Configuration
public class RedisConfig {
@Bean
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory connectionFactory){
//1、创建RedisTemplate对象
RedisTemplate<String, Object> template = new RedisTemplate<>();
//2、设置连接工厂
template.setConnectionFactory(connectionFactory);
//3、创建JSON的序列化工具
GenericJackson2JsonRedisSerializer jsonRedisSerializer = new GenericJackson2JsonRedisSerializer();
//4、设置Key的序列化工具
template.setKeySerializer(RedisSerializer.string());
template.setHashKeySerializer(RedisSerializer.string());
//5、设置Value的序列化工具
template.setValueSerializer(jsonRedisSerializer);
template.setHashValueSerializer(jsonRedisSerializer);
return template;
}
}
2.4.2 使用
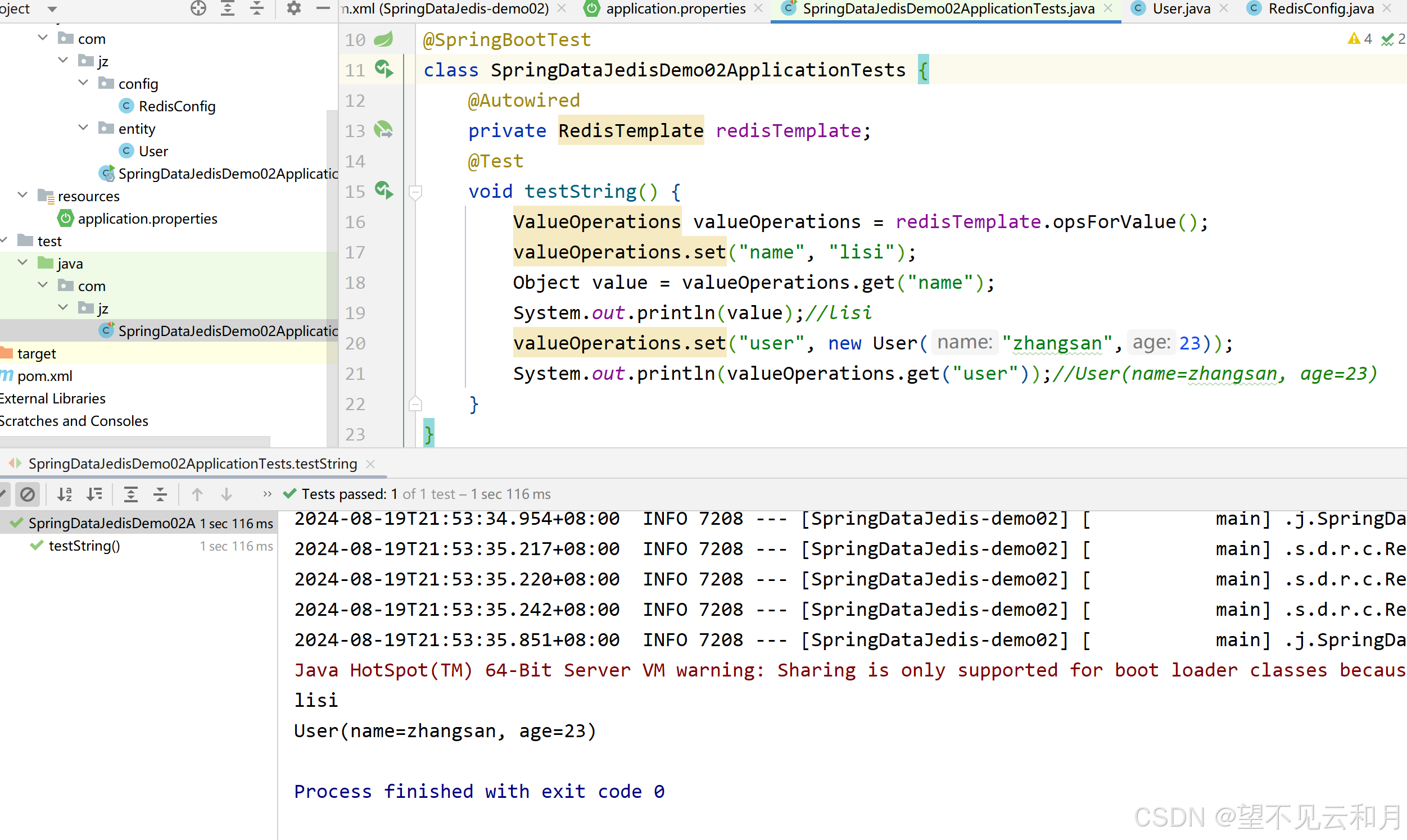
2.4.3 json序列化工具的坏处
如图直接可以为我们序列化反序列化java对象,因为json序列化工具自动为我们的redis数据库加了实体类的全类名,内存占用大
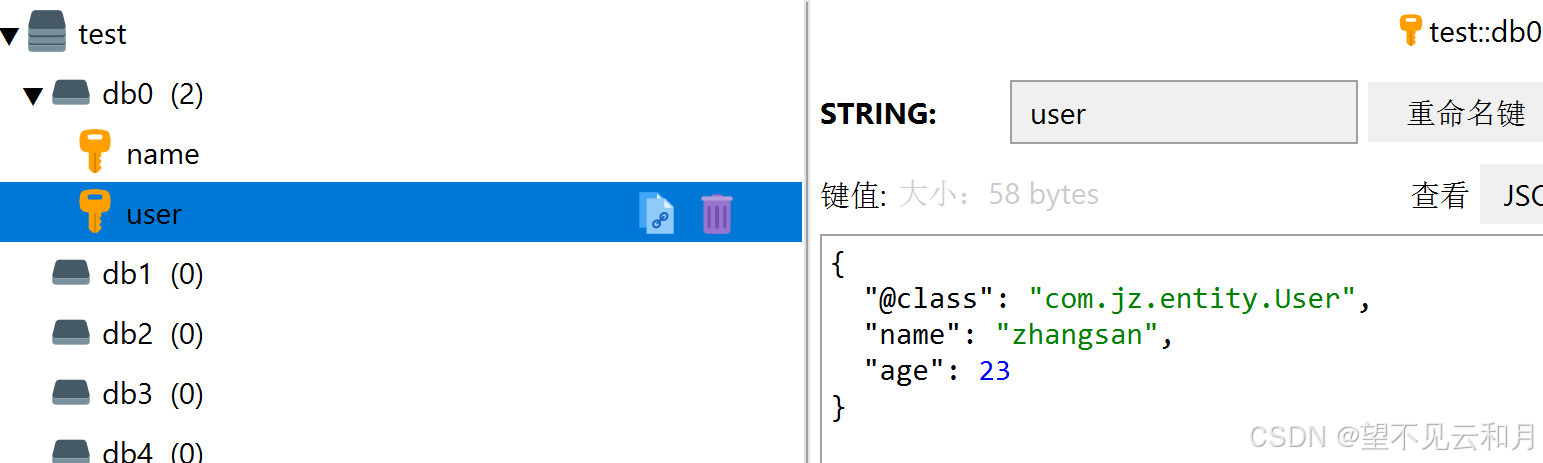
所以我们要使用String类型序列化工具
2.5 使用StringRedisTemplate模板
使用springdata提供的redis模板,实现了通过string序列化,还不需要我们写配置类,但是要我们自己将Java对象转为json字符串
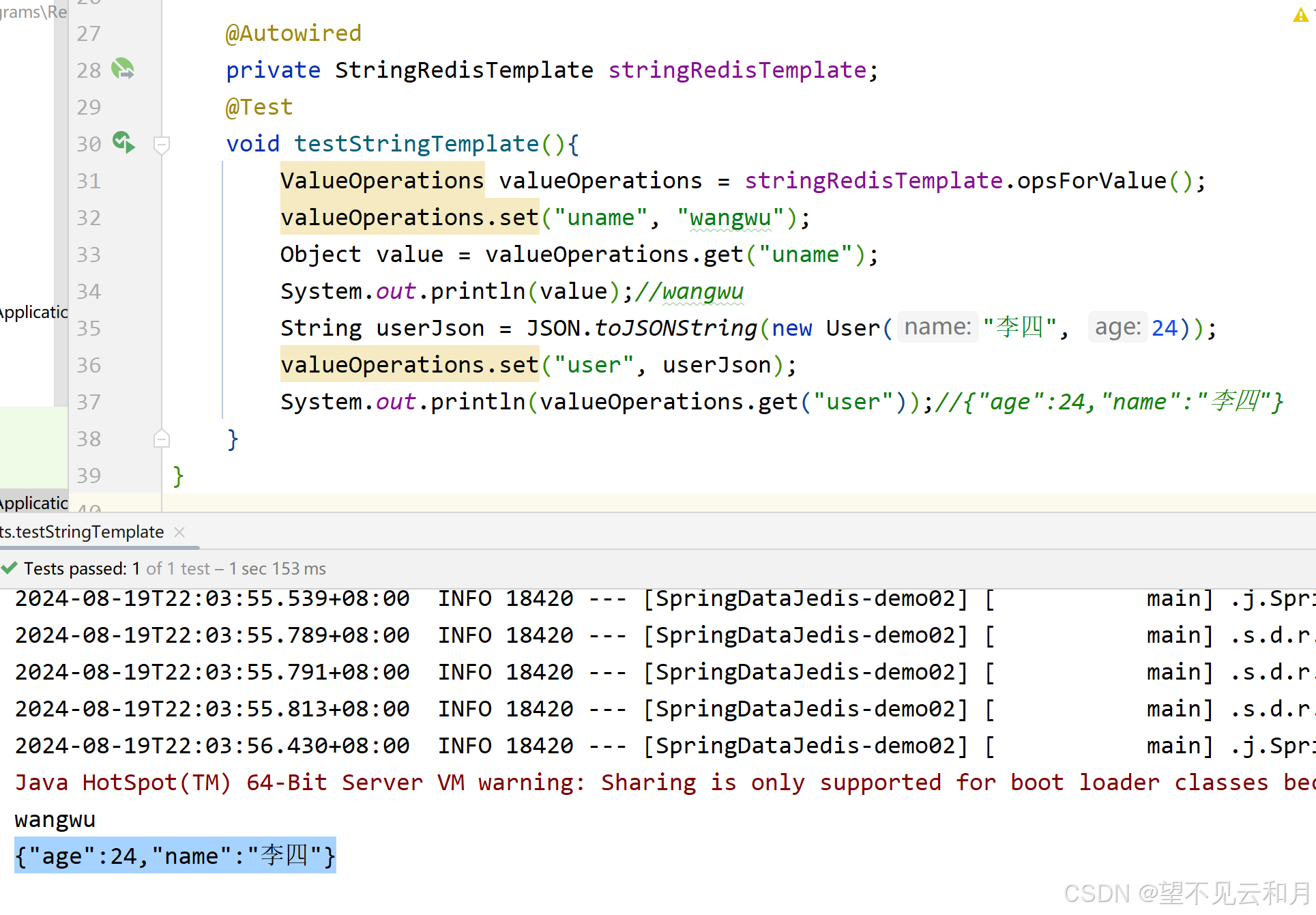
如下图,这样就没有class了