Spark-TTS 是由出门问问(Mobvoi)联合多所顶尖学术机构(如香港科技大学、上海交通大学)最新推出的新一代语音合成模型,其核心创新在于BiCodec编码技术和与文本大模型的结构统一性,利用大型语言模型 (LLM) 的强大功能实现高度准确且自然的语音合成。

主要特点:
简洁高效:Spark-TTS 完全基于 Qwen2.5 构建,无需使用流匹配等额外生成模型。它无需依赖单独的模型来生成声学特征,而是直接从 LLM 预测的代码中重建音频。这种方法简化了流程,提高了效率并降低了复杂性。
零样本语音克隆:支持零样本语音克隆,这意味着即使没有针对该语音的特定训练数据,它也可以复制说话者的声音。这非常适合跨语言和代码切换场景,允许在语言和语音之间无缝转换,而无需对每种语言和语音进行单独训练。
双语支持:支持中英文,并具备跨语言、代码切换场景的零样本语音克隆能力,使模型能够高自然度、高准确度地合成多种语言的语音。
可控语音生成:支持通过调整性别、音调、语速等参数创建虚拟说话人。
接下来就为大家奉上详细的 Spark-TTS本地部署教程,手把手教你如何将模型部署到你的项目中,轻松享受高性能AI带来的便利。
部署过程
基础环境最低要求说明:
| 环境名称 | 版本信息 |
|---|---|
| Ubuntu | 22.04.4 LTS |
| Cuda | V12.1.105 |
| Python | 3.12 |
| NVIDIA Corporation | RTX 4090 |
1. 更新基础软件包
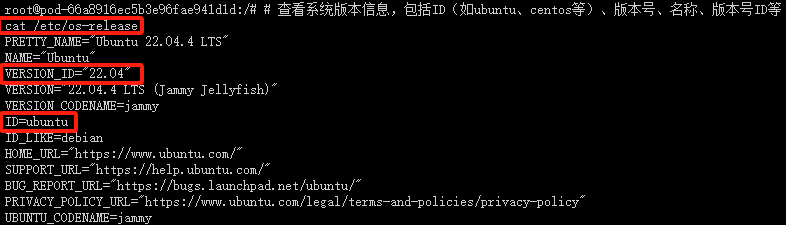
查看系统版本信息
# 查看系统版本信息,包括ID(如ubuntu、centos等)、版本号、名称、版本号ID等
cat /etc/os-release
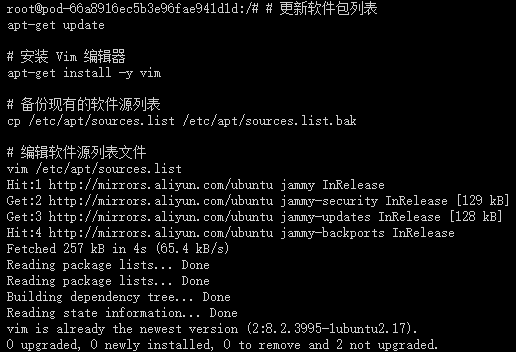
配置 apt 国内源
# 更新软件包列表
apt-get update
这个命令用于更新本地软件包索引。它会从所有配置的源中检索最新的软件包列表信息,但不会安装或升级任何软件包。这是安装新软件包或进行软件包升级之前的推荐步骤,因为它确保了您获取的是最新版本的软件包。
# 安装 Vim 编辑器
apt-get install -y vim
这个命令用于安装 Vim 文本编辑器。-y 选项表示自动回答所有的提示为“是”,这样在安装过程中就不需要手动确认。Vim 是一个非常强大的文本编辑器,广泛用于编程和配置文件的编辑。
为了安全起见,先备份当前的 sources.list 文件之后,再进行修改:
# 备份现有的软件源列表
cp /etc/apt/sources.list /etc/apt/sources.list.bak
这个命令将当前的 sources.list 文件复制为一个名为 sources.list.bak 的备份文件。这是一个好习惯,因为编辑 sources.list 文件时可能会出错,导致无法安装或更新软件包。有了备份,如果出现问题,您可以轻松地恢复原始的文件。
# 编辑软件源列表文件
vim /etc/apt/sources.list
这个命令使用 Vim 编辑器打开 sources.list 文件,以便您可以编辑它。这个文件包含了 APT(Advanced Package Tool)用于安装和更新软件包的软件源列表。通过编辑这个文件,您可以添加新的软件源、更改现有软件源的优先级或禁用某些软件源。
在 Vim 中,您可以使用方向键来移动光标,i 键进入插入模式(可以开始编辑文本),Esc 键退出插入模式,:wq 命令保存更改并退出 Vim,或 :q! 命令不保存更改并退出 Vim。
编辑 sources.list 文件时,请确保您了解自己在做什么,特别是如果您正在添加新的软件源。错误的源可能会导致软件包安装失败或系统安全问题。如果您不确定,最好先搜索并找到可靠的源信息,或者咨询有经验的 Linux 用户。
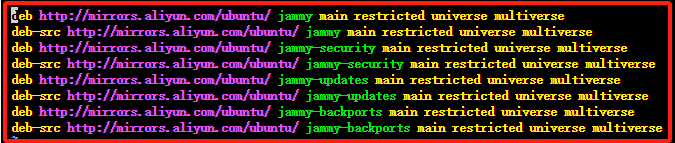
使用 Vim 编辑器打开 sources.list 文件,复制以下代码替换 sources.list里面的全部代码,配置 apt 国内阿里源。
deb http://mirrors.aliyun.com/ubuntu/ jammy main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ jammy main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ jammy-security main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ jammy-security main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ jammy-updates main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ jammy-updates main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ jammy-backports main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ jammy-backports main restricted universe multiverse
安装常用软件和工具
# 更新源列表,输入以下命令:
apt-get update
# 更新系统软件包,输入以下命令:
apt-get upgrade
# 安装常用软件和工具,输入以下命令:
apt-get -y install vim wget git git-lfs unzip lsof net-tools gcc cmake build-essential
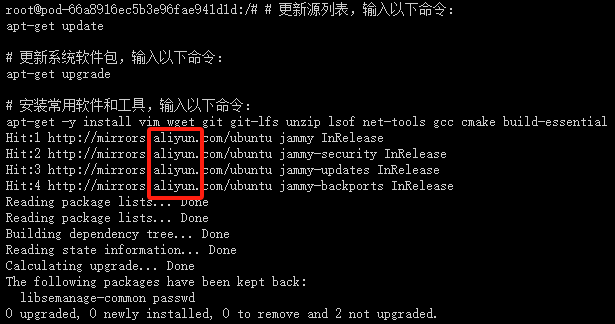
出现以下页面,说明国内apt源已替换成功,且能正常安装apt软件和工具
2. 安装 NVIDIA CUDA Toolkit 12.1
- 下载 CUDA Keyring :
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-keyring_1.0-1_all.deb
这个命令用于下载 CUDA 的 GPG 密钥环,它用于验证 CUDA 软件包的签名。这是确保软件包安全性的一个重要步骤。
- 安装 CUDA Keyring :
dpkg -i cuda-keyring_1.0-1_all.deb
使用 dpkg 安装下载的密钥环。这是必要的,以便 apt 能够验证从 NVIDIA 仓库下载的软件包的签名。
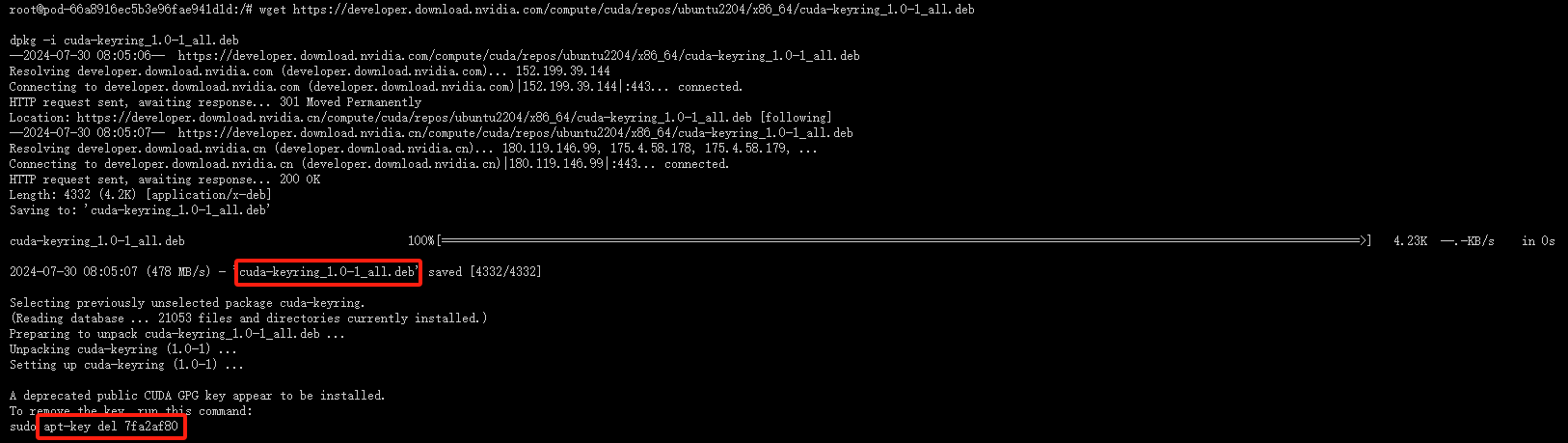
- 删除旧的 apt 密钥(如果必要) :
apt-key del 7fa2af80
这一步可能不是必需的,除非您知道 7fa2af80 是与 CUDA 相关的旧密钥,并且您想从系统中删除它以避免混淆。通常情况下,如果您只是安装 CUDA 并使用 NVIDIA 提供的最新密钥环,这一步可以跳过。
- 更新 apt 包列表 :
apt-get update
更新 apt 的软件包列表,以便包括刚刚通过 cuda-keyring 添加的 NVIDIA 仓库中的软件包。
- 安装 CUDA Toolkit :
apt-get -y install cuda-toolkit-12-1
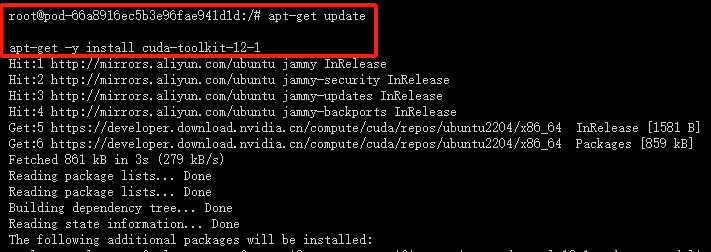
出现以下页面,说明 NVIDIA CUDA Toolkit 12.1 安装成功
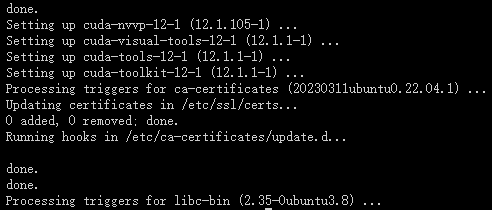
注意:这里可能有一个问题。NVIDIA 官方 Ubuntu 仓库中可能不包含直接名为 cuda-toolkit-12-1 的包。通常,您会安装一个名为 cuda 或 cuda-12-1 的元包,它会作为依赖项拉入 CUDA Toolkit 的所有组件。请检查 NVIDIA 的官方文档或仓库,以确认正确的包名。
如果您正在寻找安装特定版本的 CUDA Toolkit,您可能需要安装类似 cuda-12-1 的包(如果可用),或者从 NVIDIA 的官方网站下载 CUDA Toolkit 的 .run 安装程序进行手动安装。
请确保您查看 NVIDIA 的官方文档或 Ubuntu 的 NVIDIA CUDA 仓库以获取最准确的包名和安装指令。

- 出现以上情况,需要配置 NVIDIA CUDA Toolkit 12.1 系统环境变量
编辑 ~/.bashrc 文件
# 编辑 ~/.bashrc 文件
vim ~/.bashrc
插入以下环境变量
# 插入以下环境变量
export PATH=/usr/local/cuda/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda/lib64:$LD_LIBRARY_PATH

激活 ~/.bashrc 文件
# 激活 ~/.bashrc 文件
source ~/.bashrc
查看cuda系统环境变量
which nvcc
nvcc -V
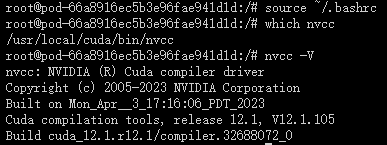
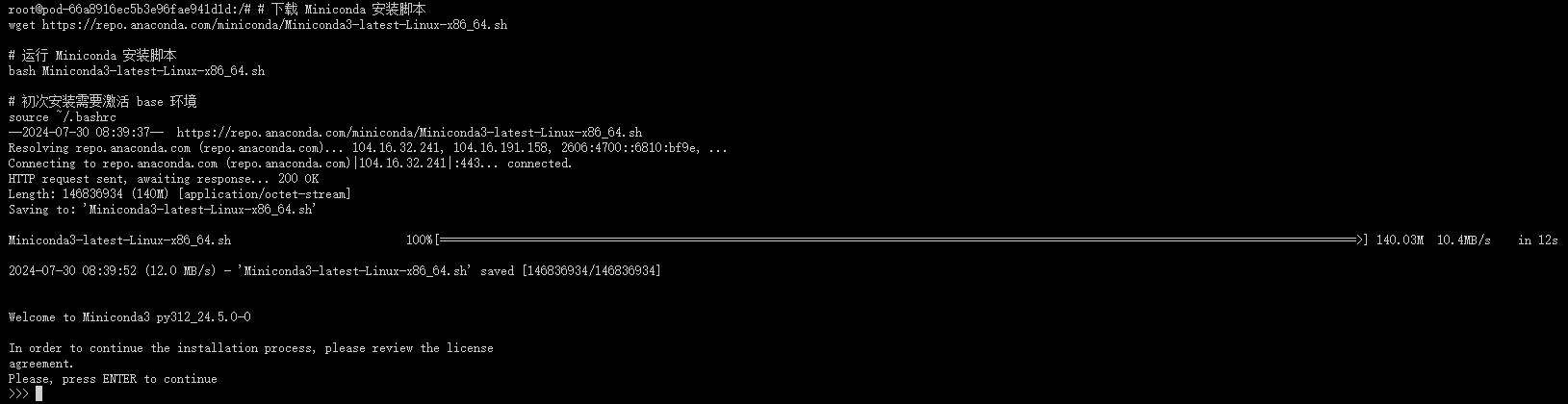
3. 安装 Miniconda
- 下载 Miniconda 安装脚本 :
- 使用
wget命令从 Anaconda 的官方仓库下载 Miniconda 的安装脚本。Miniconda 是一个更小的 Anaconda 发行版,包含了 Anaconda 的核心组件,用于安装和管理 Python 包。
- 使用
- 运行 Miniconda 安装脚本 :
- 使用
bash命令运行下载的 Miniconda 安装脚本。这将启动 Miniconda 的安装过程。
- 使用
# 下载 Miniconda 安装脚本
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
# 运行 Miniconda 安装脚本
bash Miniconda3-latest-Linux-x86_64.sh
# 初次安装需要激活 base 环境
source ~/.bashrc
按下回车键(enter)
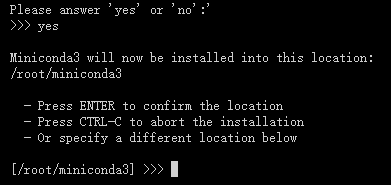
输入yes
输入yes
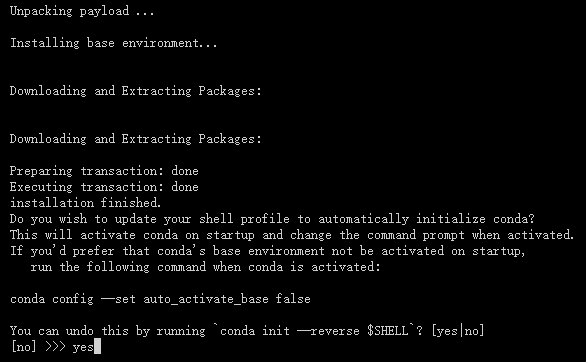
安装成功如下图所示
pip配置清华源加速
# 编辑 /etc/pip.conf 文件
vim /etc/pip.conf
加入以下代码
[global]
index-url = https://pypi.tuna.tsinghua.edu.cn/simple
注意事项:
- 请确保您的系统是 Linux x86_64 架构,因为下载的 Miniconda 版本是为该架构设计的。
- 在运行安装脚本之前,您可能需要使用
chmod +x Miniconda3-latest-Linux-x86_64.sh命令给予脚本执行权限。 - 安装过程中,您将被提示是否同意许可协议,以及是否将 Miniconda 初始化。通常选择 "yes" 以完成安装和初始化。
- 安装完成后,您可以使用
conda命令来管理 Python 环境和包。 - 如果链接无法访问或解析失败,可能是因为网络问题或链接本身的问题。请检查网络连接,并确保链接是最新的和有效的。如果问题依旧,请访问 Anaconda 的官方网站获取最新的下载链接。
4. 从 github 仓库克隆项目
git clone https://github.com/SparkAudio/Spark-TTS.git
cd Spark-TTS
5. 创建虚拟环境
conda create -n sparktts -y python=3.12
conda activate sparktts
6. 安装模型依赖库
cd Spark-TTS
conda activate sparktts
pip install -r requirements.txt
7. 下载预训练模型
mkdir -p pretrained_models
git lfs install
git clone https://huggingface.co/SparkAudio/Spark-TTS-0.5B pretrained_models/Spark-TTS-0.5B
8. 运行 webui.py 文件
cd Spark-TTS
conda activate sparktts
python webui.py --device 0
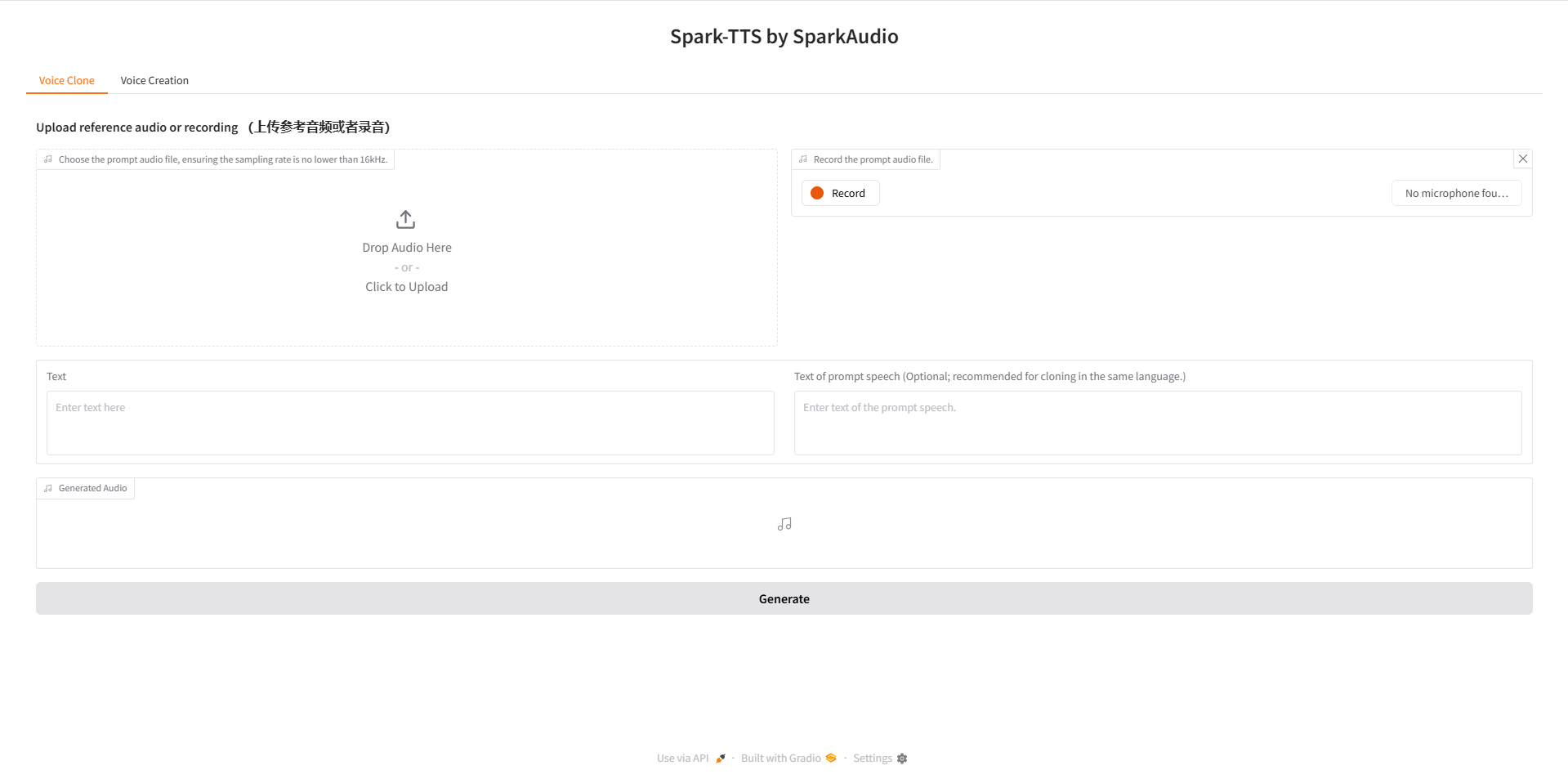
网页演示
出现以下 Gradio 页面,即是模型已搭建完成。