原文标题:SiamCAR: Siamese Fully Convolutional Classification and Regression for Visual Tracking
中文标题:SiamCAR:用于视觉跟踪的Siamese全卷积分类和回归
代码地址: https://github.com/ohhhyeahhh/SiamCAR
本篇分享旨在帮助大家对该网络有一个快速大致的了解,具体详解可以参考这篇:
SiamCAR(2019CVPR):用于视觉跟踪的Siamese全卷积分类和回归网络-CSDN博客

Abstract
通过将视觉跟踪任务分解为两个子问题,即像素类别的分类和该像素处的目标边界框的回归,我们提出了一种新颖的全卷积Siamese网络,以逐像素的方式解决端到端的视觉跟踪。所提出的框架 SiamCAR 由两个简单的子网络组成:一个用于特征提取的 Siamese 子网络和一个用于边界框预测的分类回归子网络。我们的框架以 ResNet-50 作为骨干。与 Siamese-RPN、SiamRPN++ 和 SPM 等基于区域提议的最先进的跟踪器不同,我们所提出的框架既是无提议的,也是无锚的。因此,我们能够避免棘手的锚点超参数调整并减少人为干预。我们所提出的框架简单、整洁且有效。在 GOT10K、LaSOT、UAV123 和 OTB-50 等许多具有挑战性的基准上进行了广泛的实验并与最先进的跟踪器进行了比较。没有花里胡哨的东西,我们的SiamCAR以相当大的实时速度实现了领先的性能。
1. Introduction
视觉目标跟踪因其在智能监控、人机交互、无人驾驶车辆等领域的广泛应用而受到广泛关注。视觉跟踪方面取得了快速进展。然而,这仍然是一项具有挑战性的任务,特别是对于现实世界的应用来说,因为在无约束记录条件下的目标通常会遭受较大的照明变化、尺度变化、背景杂乱和严重遮挡等。此外,由于极端的姿态变化,非刚性物体的外观可能会发生显著变化。
当前流行的视觉跟踪方法围绕基于Siamese网络的架构而展开。Siamese网络将视觉跟踪任务表述为目标匹配问题,旨在学习目标模板和搜索区域之间的通用相似度图。 由于单个相似性图通常包含有限的空间信息,因此一种常见的策略是在多个尺度的搜索区域上执行匹配以确定目标尺度变化,这解释了为什么这些跟踪器既费时又费力。SiamRPN为 Siamese 网络附加了一个区域提议提取子网络(RPN)。通过联合训练用于视觉跟踪的分类分支和回归分支,SiamRPN 避免了为目标尺度不变性提取多尺度特征图的耗时步骤。它在许多基准测试中取得了最先进的结果。后来的工作如 DaSiam、CSiam 和 SiamRPN++改进了 SiamRPN。然而,由于锚点是为了区域提议而引入的,这些跟踪器对锚点框的数量、大小和长宽比很敏感,超参数调整的专业知识对于使用这些跟踪器获得成功的跟踪至关重要。
在本文中,我们证明了基于无锚点Siamese网络的跟踪器比基于RPN的跟踪器性能更好。本质上,我们将跟踪分解为两个子问题:一个分类问题和一个回归任务。分类分支的目的是预测每个空间位置的标签,而回归分支则考虑为每个空间位置回归一个相对的边界框。通过这种分解,可以以逐像素预测的方式解决跟踪任务。然后,我们制作了一个简单而有效的基于Siamese的分类和回归网络(SiamCAR),以端到端方式同时学习分类和回归模型。
之前的工作利用目标语义信息来改进边界框回归。受此启发,SiamCAR旨在提取一个包含丰富类别信息和语义信息的响应图。与RPN模型分别使用两张响应图进行区域提议检测和回归不同,SiamCAR采用一张唯一的响应图来直接预测目标位置和边界框。
SiamCAR采用在线训练、离线跟踪的策略,在训练过程中不使用任何数据增强。我们的主要贡献是:
• 我们提出了用于视觉跟踪的Siamese分类和回归框架(SiamCAR)。该框架结构非常简单但性能强大。
• 提议的跟踪器既不受锚点的限制,也不受提议的影响。超参数的数量显著减少,这使得跟踪器免于复杂的参数调整,并使跟踪器变得更加简单,尤其是在训练中。
• 没有花里胡哨的东西,所提出的跟踪器在准确性和时间成本方面实现了最先进的跟踪性能。
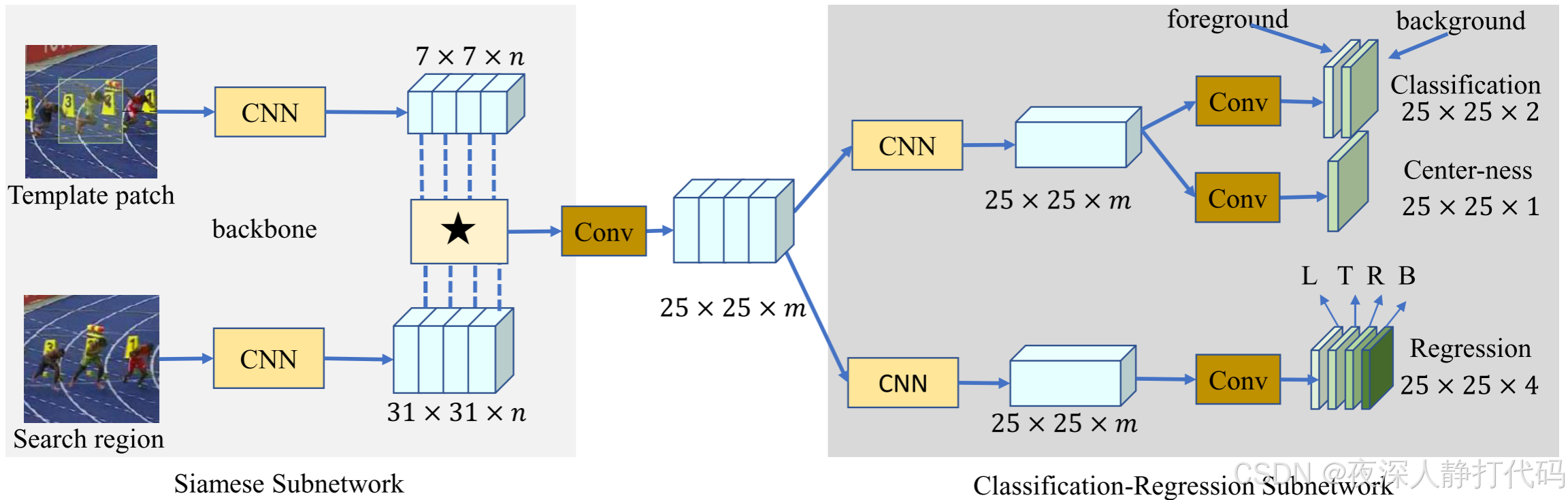
SiamCAR 图示。左侧是 Siamese 子网络,具有用于提取多通道响应图的深度可分离互相关层(depth-wise cross correlation layer,用 ⋆ 表示)。右侧显示了用于边界框预测的分类和回归子网络,用于从多通道响应图中解码目标的位置和尺度信息。请注意,SiamCAR 可以实现为全卷积网络,简单、整洁且易于解释。
2. Related Works
我们主要回顾 Siamese RPN 跟踪器家族,因为它们在近年来的跟踪性能中占据主导地位。跟踪研究人员致力于从特征提取、模板更新、分类器设计和边界框回归等不同方面设计更快、更准确的跟踪器。早期的特征提取主要使用颜色特征、纹理特征或其他手工制作的特征。得益于深度学习的发展,现在深度卷积特征CNN被广泛采用。模板更新可以提高模型的适应性,但在线跟踪的效率很低。此外,还需要解决模板更新时的跟踪漂移问题。相关性滤波方法的引入使跟踪在效率和精度上都达到了前所未有的高度。目前的研究表明,基于Siamese的在线训练和基于深度神经网络的离线跟踪方法在准确性和效率之间达到了最好的平衡。
作为开创性的工作之一,SiamFC构建了一个完全卷积的Siamese网络来训练跟踪器。 受其成功的鼓舞,许多研究者跟进了这项工作,并提出了一些更新的模型。CFNet在SiamFC框架中引入了Correlation Filter层,并进行在线跟踪以提高精度。DSiam提出了一种学习动态Siamese网络的方法,通过两次在线变换对Siamese分支进行修改,在可接受的速度损失下提高了准确率。SAsiam构建了一个具有语义分支和外观分支的双重Siamese网络,两个分支分别训练以保持特征的异质性,但在测试时结合训练以提高跟踪精度,为了解决尺度变化问题,这些Siamese网络需要处理多尺度搜索,费时费力。
受目标检测的区域建议网络的启发,SiamRPN跟踪器在Siamese网络输出后执行区域建议提取。SiamRPN通过对区域建议的分类分支和回归分支进行联合训练,避免了为目标尺度不变性而提取多尺度特征图的耗时步骤,获得了非常高效的结果。然而,它很难处理与物体外观相似的干扰物。DaSiamRPN在SiamRPN的基础上增加了训练阶段的hard negative训练数据。通过数据增强,他们提高了跟踪器的辨别力并获得了更稳健的结果。 该跟踪器进一步扩展到长期视觉跟踪。到目前为止,该框架已经在SiamFC的基础上进行了大量的修改,但使用AlexNet作为骨干网络,性能仍然无法在更深层次的网络中发展。针对这一问题,SiamRPN++采用ResNet作为骨干网,对网络架构进行了优化。同时,在模型训练过程中,随机移动训练目标在搜索区域的位置,消除中心偏差。经过这些修改后,可以在非常深的网络架构而不是浅层神经网络中实现更好的跟踪精度。
这些基于RPN的跟踪器采用锚点进行区域建议。此外,锚框可以利用深层特征图避免重复计算,可以显著加快跟踪过程。最先进的跟踪器SPM和SiamRPN都以非常高的速度工作。尽管SiamRPN++采用了非常深的神经网络,但它仍然可以以相当的实时速度工作。在 GOT-10K 等具有挑战性的基准测试中,ECO 等最先进的无锚跟踪器的准确性和速度仍然与这些基于锚的跟踪器存在差距。
然而,跟踪性能对锚点的相关超参数非常敏感,需要仔细调整并涉及经验技巧才能实现理想的性能。此外,由于锚框的大小和长宽比是固定的,即使使用启发式调整参数,这些跟踪器仍然难以处理具有较大形变和姿态变化的目标。在本文中,我们证明了我们提出的 SiamCAR 可以极大缓解这些问题。此外,我们证明了结构更简单的跟踪器可以实现比最先进的跟踪器更好的性能。

图1:提出的SiamCAR与三个最先进的跟踪器在GOT-10K的三个具有挑战性的序列上的比较。SiamCAR可以准确地预测边界框,即使受到物体相似的干扰,大尺度变化和大姿态变化,而SiamRPN++和SPM给出的结果要粗糙得多,ECO会向背景漂移。
3. Results on GOT-10K
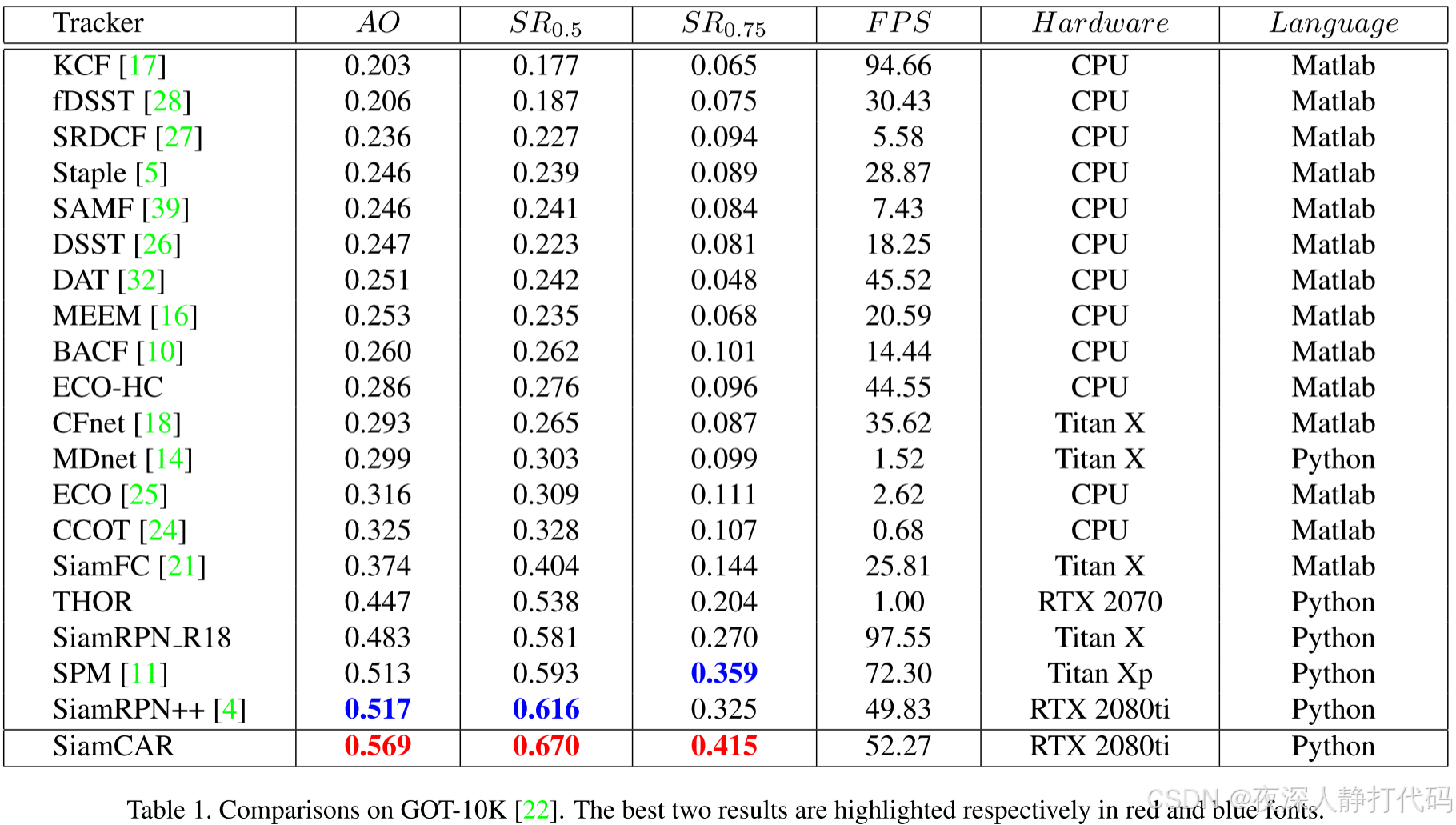
GOT-10K是一个最近发布的大型高多样性基准,用于野外通用目标跟踪。它包含了1万多个真实世界移动物体的视频片段。协议确保了深度跟踪器的公平比较,所有方法都使用数据集提供的相同训练数据。训练数据集和测试数据集中的类是零重叠的。作者需要在给定的训练数据集上训练他们的模型,并在给定的测试数据集上测试他们。跟踪结果上传后,官方网站会自动进行分析。提供的评价指标包括成功图(success plots,SP)、平均重叠(average overlap,AO)和成功率(success rate,SR)。AO表示所有估计的边界框和真实框框之间的平均重叠。SR0.5表示在所有帧中,预测框与真实框的交并比(IOU)超过0.5的帧比例,SR0.75表示IOU超过0.75的成功跟踪率。
我们在GOT-10K上评估SiamCAR,并将其与最先进的跟踪器进行比较,包括SiamRPN++、SiamRPN、SiamFC、ECO、CFNET和其他基线或最先进的方法。所有结果均由GOT-10K官网提供。图1显示,SiamCAR可以优于GOT-10K上的所有跟踪器,表1列出了不同指标的比较细节。如表1所示,我们的跟踪器在所有指标上都排名第一。 与SiamRPN++相比,我们的SiamCAR在AO、SR0.5和SR0.75下的得分分别提高了5.2%、5.4%和9.0%。由于跟踪器公平地使用相同的训练数据,并且测试数据集的真实框对于跟踪器来说是不可见的,因此GOT-10K上的跟踪结果比其他基准测试上的跟踪结果更可信和令人信服。
4. Conclusions
在本文中,我们提出了一个称为 SiamCAR 的 Siamese 分类和回归框架,用于端到端训练用于视觉跟踪的深度 Siamese 网络。我们证明跟踪任务可以以逐像素的方式解决,并采用简洁的全卷积框架。所提出的框架结构非常简单,但在 GOT-10K 和许多其他具有挑战性的基准测试上实现了最先进的结果。它还在 LaSOT 等大型数据集上取得了最先进的结果,这证明了我们的 SiamCAR 的通用性。由于本框架简单、整洁,可以很容易地用特定的模块进行修改,以便将来进一步改进。