1.前言
在进行目标检测任务时,数据集的质量和多样性直接影响到模型的表现。Roboflow 是一个广泛使用的在线平台,它提供了丰富的标注工具和数据集管理功能,帮助用户快速构建和处理目标检测数据集。通过 Roboflow,用户可以轻松获取并处理适用于各种计算机视觉任务的数据集,特别是目标检测任务中的图像和标签。
本文将详细介绍如何从 Roboflow 平台下载目标检测数据集以及对于下载的数据集进行一些处理方便自己使用。本文不废话,全是代码全是干货。
2.Roboflow介绍
Roboflow 是一个在线平台,专为计算机视觉任务设计,帮助用户轻松创建、标注、增强和管理图像数据集。它主要应用于目标检测、图像分类、分割等任务。通过 Roboflow,用户可以快速上传图像、标注目标、进行数据增强,并将数据集转换为多种格式,如 YOLO、Pascal VOC 和 COCO 格式,方便与深度学习框架兼容。
Roboflow的核心功能包括:
- 图像标注工具:支持边界框、分割和关键点标注。
- 数据增强:提供旋转、翻转、裁剪等多种增强方式。
- 格式转换:自动将数据集转换为不同的标注格式。
- 数据集共享与协作:支持团队合作,方便多人共同处理数据集。
总的来说,Roboflow 是一个强大的平台,帮助用户简化数据集处理过程,提高目标检测等计算机视觉任务的效率。
3.下载数据集
本文将通过Roboflow获取 火焰及烟雾数据集 做示例,及提供一些拿到并使用自己课题的一些思路。
访问如下网站
Roboflow Universe: Computer Vision Datasets
先注册一个账号,点击右上角Sign In /Create an Account ,可以登录或者创建账号,我这里使用谷歌邮箱直接登录了,也可以使用其它邮箱。
搜索fire and smoke ,搜索词根据自己要做的主题更换。
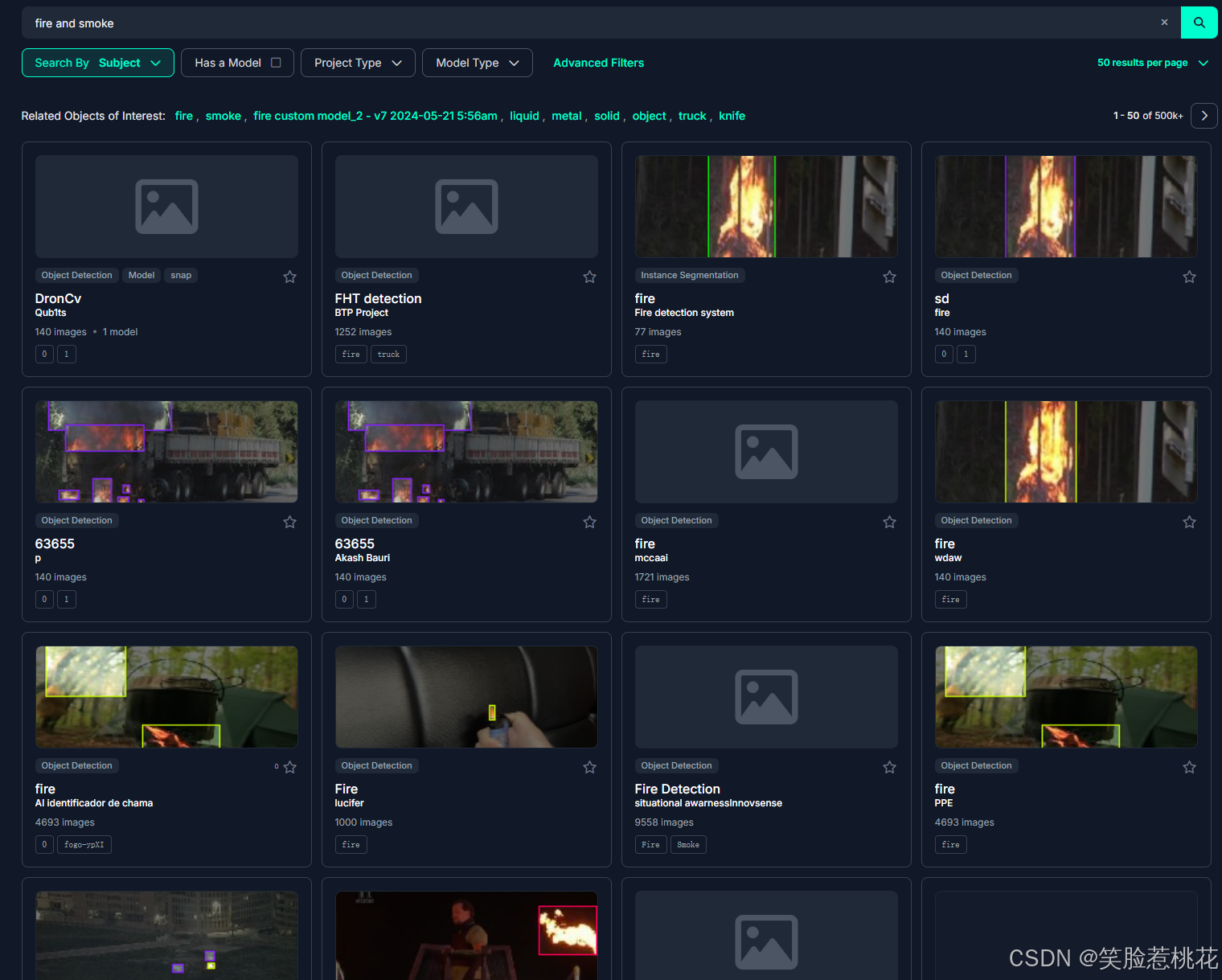
找一个点进去,然后点击左侧Dataset ,
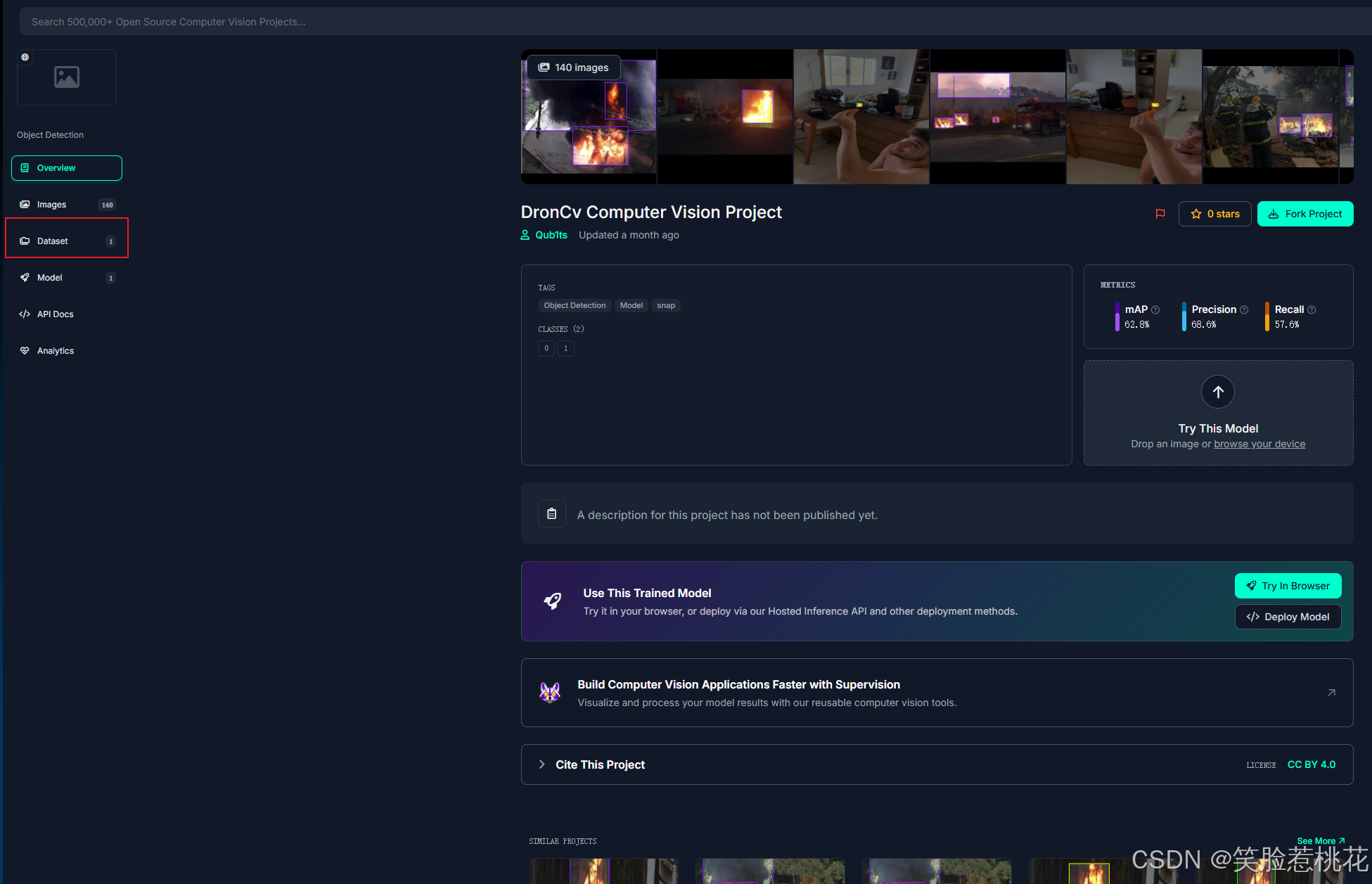
点击右侧 Download Dataset 弹出的窗口再点击 Download on my own ,然后按照如下窗口选择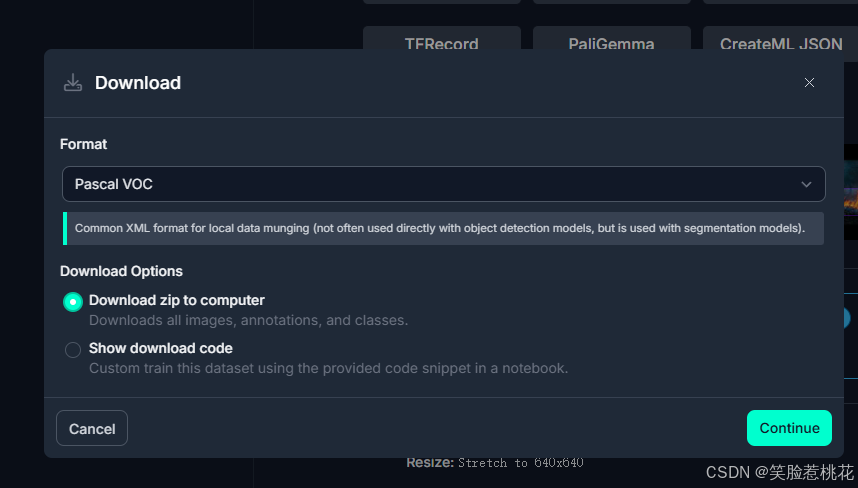
点击continue即下载。
4.一系列处理
下载完成后为压缩包,有多个文件,先全部解压缩到一个文件夹中,我这里命名为smoke,因为我只需要smoke的数据,不需要fire的,因此需要对数据进行删除。先运行代码将各个文件夹内的文件移动到jpg和xml的大文件夹中。
import os
import shutil
def organize_files(folder_path):
if not os.path.isdir(folder_path):
print(f"错误: 文件夹 {folder_path} 不存在!")
return
xml_folder = os.path.join(folder_path, 'xml')
jpg_folder = os.path.join(folder_path, 'jpg')
os.makedirs(xml_folder, exist_ok=True)
os.makedirs(jpg_folder, exist_ok=True)
for dirpath, dirnames, filenames in os.walk(folder_path):
for filename in filenames:
file_path = os.path.join(dirpath, filename)
if os.path.isfile(file_path):
if filename.endswith('.xml'): #文件后缀为txt则修改为txt
try:
shutil.move(file_path, os.path.join(xml_folder, filename))
print(f"已将 {filename} 移动到 xml 文件夹")
except Exception as e:
print(f"无法移动文件 {filename}: {e}")
elif filename.endswith(('.jpg', 'png')):
try:
shutil.move(file_path, os.path.join(jpg_folder, filename))
print(f"已将 {filename} 移动到 jpg 文件夹")
except Exception as e:
print(f"无法移动文件 {filename}: {e}")
if __name__ == '__main__':
folder = r'F:\smoke' #修改为解压缩后的文件目录
organize_files(folder)
运行完毕后,会出现smoke文件夹下有xml和jpg两个文件,这时候对xml文件夹下所有的xml进行统计类别。运行下面的代码,查看所有类别。
import os
import xml.etree.ElementTree as ET
class_count = {}
folder_path = r'F:\smoke\xml' # 此处修改为自己的xml文件夹路径
for filename in os.listdir(folder_path):
if filename.endswith('.xml'):
tree = ET.parse(os.path.join(folder_path, filename))
root = tree.getroot()
for obj in root.findall('object'):
name = obj.find('name').text
if name in class_count:
class_count[name] += 1
else:
class_count[name] = 1
sorted_class_count = sorted(class_count.items(), key=lambda x: x[1], reverse=True)
print(sorted_class_count)
print("各类别数量(从大到小):")
for name, count in sorted_class_count:
print(f"{name}: {count}")
运行完毕后,可以看到有多个类别,这时候我们只需要自己需要的类别,比如smoke,而舍弃fire类别,需要在格式转换时只转换smoke类别,运行如下代码。
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
def convert(size, box):
x_center = (box[0] + box[1]) / 2.0
y_center = (box[2] + box[3]) / 2.0
x = x_center / size[0]
y = y_center / size[1]
w = (box[1] - box[0]) / size[0]
h = (box[3] - box[2]) / size[1]
return (x, y, w, h)
def remove_extension(file_name):
dot_position = file_name.rfind('.')
if dot_position != -1 and dot_position != len(file_name) - 1:
return file_name[:dot_position]
else:
return file_name
def convert_annotation(xml_files_path, save_txt_files_path, classes):
xml_files = os.listdir(xml_files_path)
#print(xml_files)
os.makedirs(save_txt_files_path, exist_ok=True)
for xml_name in xml_files:
print(xml_name)
xml_file = os.path.join(xml_files_path, xml_name)
xml_name1 = remove_extension(xml_name)
out_txt_path = os.path.join(save_txt_files_path, xml_name1 + '.txt')
out_txt_f = open(out_txt_path, 'w')
tree = ET.parse(xml_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
# b=(xmin, xmax, ymin, ymax)
print(w, h, b)
bb = convert((w, h), b)
out_txt_f.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
if __name__ == "__main__":
classes1 = ['smoke'] # 需要转换的类别,需要一一对应
xml_files1 = r'F:\smoke\xml' # voc格式的xml标签文件路径
save_txt_files1 = r'F:\smoke\labels' # 转化为yolo格式的txt标签文件存储路径
convert_annotation(xml_files1, save_txt_files1, classes1)运行完后则生成一个labels文件夹,里面含有txt文件,有的为空,有的含有转换后的标注信息。将空白文件全部删除,运行下面的代码。
import os
def delete_empty_files(folder_path):
if not os.path.isdir(folder_path):
print(f"错误: 文件夹 {folder_path} 不存在!")
return
for dirpath, dirnames, filenames in os.walk(folder_path):
for filename in filenames:
file_path = os.path.join(dirpath, filename)
if os.path.getsize(file_path) == 0:
try:
os.remove(file_path)
print(f"已删除空文件: {file_path}")
except Exception as e:
print(f"无法删除文件 {file_path}: {e}")
if __name__ == '__main__':
folder = r'F:\smoke\labels'
delete_empty_files(folder)
空白文件全部删除后,则需要对应将jpg文件中多余的图像删除,运行下面的代码。
import os
def find_and_delete_files(folder_path_1, folder_path_2):
files_1 = os.listdir(folder_path_1)
files_2 = os.listdir(folder_path_2)
for file_1 in files_1:
if os.path.isfile(os.path.join(folder_path_1, file_1)):
file_name_1 = os.path.splitext(file_1)[0]
found_match = False
for file_2 in files_2:
# 获取第二个文件夹中每个文件的文件名(不含扩展名)
file_name_2 = os.path.splitext(file_2)[0]
if file_name_1 == file_name_2:
found_match = True
break
if not found_match:
file_to_delete = os.path.join(folder_path_1, file_1)
os.remove(file_to_delete)
print(f"Deleted: {file_1} from {folder_path_1}")
else:
print(f"Found: {file_1} in both folders")
else:
print(f"Skipping non-file: {file_1}")
folder_path_1 = r"F:\smoke\jpg" # 第1个文件夹路径
folder_path_2 = r"F:\smoke\labels" # 第2个文件夹路径
#根据2删除1, 1文件夹被删除
find_and_delete_files(folder_path_1, folder_path_2)
将第一个文件夹内多余的图像文件删除,删除完成后,数据集即处理完毕,这时如果需要后续再对图像进行数据增强,可以把txt转为xml,运行下面的代码。
# 作者:CSDN-笑脸惹桃花 https://blog.csdn.net/qq_67105081?type=blog
# github:peng-xiaobai https://github.com/peng-xiaobai/Dataset-Conversion
import os
import cv2
import numpy as np
# xml文件格式
out0 = '''<annotation>
<folder>%(folder)s</folder>
<filename>%(name)s</filename>
<path>%(path)s</path>
<source>
<database>None</database>
</source>
<size>
<width>%(width)d</width>
<height>%(height)d</height>
<depth>3</depth>
</size>
<segmented>0</segmented>
'''
out1 = ''' <object>
<name>%(class)s</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>%(xmin)d</xmin>
<ymin>%(ymin)d</ymin>
<xmax>%(xmax)d</xmax>
<ymax>%(ymax)d</ymax>
</bndbox>
</object>
'''
out2 = '''</annotation>
'''
def upp2low(directory):
converted_count = 0
if not os.path.exists(directory):
raise FileNotFoundError(f"Directory {directory} does not exist.")
for filename in os.listdir(directory):
file_path = os.path.join(directory, filename)
if os.path.isfile(file_path):
name, extension = os.path.splitext(filename)
if extension.isupper():
new_filename = name + extension.lower()
new_file_path = os.path.join(directory, new_filename)
os.rename(file_path, new_file_path)
converted_count += 1
print(f"Renamed: {filename} -> {new_filename}")
print(f"All file suffixes in the folder are lowercase, and a total of {converted_count} files have been processed")
return converted_count
def yolo2voc(dir1, dir2, dir3, Class):
file = os.listdir(dir1)
source = {}
label = {}
for img in file:
print(img)
if img.endswith(('.png', '.jpg', '.jpeg', '.bmp', '.tif')):
img1 = os.path.join(dir1, img)
image = cv2.imread(img1) # 路径不能有中文
h, w, _ = image.shape
name, extension = os.path.splitext(img)
name1 = name + '.xml'
name2 = name + '.txt'
fxml = os.path.join(dir2, name1)
txt = os.path.join(dir3, name2)
if not os.path.exists(txt):
print(f"{name2}未找到,已跳过")
continue
fxml = open(fxml, 'w')
source['name'] = img
source['path'] = img1
source['folder'] = os.path.basename(dir1)
source['width'] = w
source['height'] = h
fxml.write(out0 % source)
lines = np.loadtxt(txt)
flag = 0
for box in lines:
if box.shape != (5,):
box = lines
flag = 1
box_index = int(box[0])
label['class'] = Class[box_index]
xmin = float(box[1] - 0.5 * box[3]) * w
ymin = float(box[2] - 0.5 * box[4]) * h
xmax = float(xmin + box[3] * w)
ymax = float(ymin + box[4] * h)
label['xmin'] = xmin
label['ymin'] = ymin
label['xmax'] = xmax
label['ymax'] = ymax
keys = ['xmin', 'ymin', 'xmax', 'ymax']
limits = [w, h, w, h]
for i, key in enumerate(keys):
if label[key] >= limits[i]:
label[key] = limits[i]
elif label[key] < 0:
label[key] = 0
fxml.write(out1 % label)
if flag == 1:
break
fxml.write(out2)
if __name__ == '__main__':
l = ['smoke'] # 所有类别
file_dir1 = r'F:\smoke\jpg' # 图像文件夹
file_dir2 = r'F:\smoke\xml' # xml存放文件夹
file_dir3 = r'F:\smoke\labels' # txt存放文件夹
if not os.path.exists(file_dir2):
os.makedirs(file_dir2)
upp2low(file_dir1)
yolo2voc(file_dir1, file_dir2, file_dir3, l)
print('转换已结束')5.训练参考文章
数据处理完毕后可以划分再训练数据集,可以查看下面的文章。
超详细目标检测:YOLOv11(ultralytics)训练自己的数据集,新手小白也能学会训练模型,手把手教学一看就会_yolov11训练-CSDN博客文章浏览阅读9.8k次,点赞60次,收藏241次。对电脑小白也很简单的yolov11教程!训练自己的数据集分为4部分,先配置环境,再获取制作自己的数据集,然后修改配置训练,最后验证训练结果,附带可视化界面。YOLOv11为Ultralytics公司YOLO系列实时目标检测器的最新迭代版本,训练流程与YOLOv8基本一致,仅替换了新的网络结构与预训练权重,如果有其他目标检测的数据集可以直接拿来用,从第3训练模型开始看,新手小白0基础建议一步一步跟着来,哪里看不懂的或者遇到哪有问题可以发到评论区交流~_yolov11训练https://blog.csdn.net/qq_67105081/article/details/143402823?spm=1001.2014.3001.5502目标检测:yolov8(ultralytics)训练自己的数据集,新手小白也能学会训练模型,一看就会_yolov8s-CSDN博客文章浏览阅读1.7w次,点赞105次,收藏370次。很简单小白也可以轻松看懂并实现的yolov8教程!先配置环境,再获取制作自己的数据集,然后修改配置训练,最后验证训练结果,附带可视化界面。yolov8训练起来较为简单,如果有其他目标检测的数据集理论上可以直接拿来用,从第3训练模型开始看,新手小白0基础建议一步一步跟着来,哪里看不懂的或者遇到哪有问题可以评论区交流或者私信问~_yolov8s
https://blog.csdn.net/qq_67105081/article/details/137545156?spm=1001.2014.3001.5502目标检测:yolov5训练自己的数据集,新手小白也能学会训练模型,一看就会-CSDN博客文章浏览阅读6.7k次,点赞70次,收藏163次。训练自己的数据集分为4部分,先配置环境,再获取制作自己的数据集,然后修改配置训练,最后验证训练结果,可选择将结果进行可视化界面展示。yolov5训练起来较为简单,跟yolov8相差不多,如果有其他目标检测的数据集理论上可以直接拿来用,从第3训练模型开始看,新手小白0基础建议一步一步跟着来,哪里看不懂的或者遇到哪有问题可以评论区交流或者私信问~_yolov5训练自己的数据集
https://blog.csdn.net/qq_67105081/article/details/138233660?spm=1001.2014.3001.5502目标检测:yolov7训练自己的数据集,新手小白也能学会训练模型,一看就会-CSDN博客文章浏览阅读4.3k次,点赞36次,收藏64次。训练自己的数据集分为4部分,先配置环境,再获取制作自己的数据集,然后修改配置训练,最后验证训练结果,可选择将结果进行可视化界面展示。yolov7训练起来较为简单,跟yolov5相差不多,只需要多加一步将数据集所有的图片导入文本之中。如果有其他目标检测的数据集理论上可以直接拿来用,从第3训练模型开始看,新手小白0基础建议一步一步跟着来,哪里看不懂的或者遇到哪有问题可以评论区交流或者私信问~_yolov7训练
https://blog.csdn.net/qq_67105081/article/details/139300515?spm=1001.2014.3001.5502目标检测:yolov9训练自己的数据集,新手小白也能学会训练模型,一看就会-CSDN博客文章浏览阅读2.6k次,点赞32次,收藏31次。训练自己的数据集分为4部分,先配置环境,再获取制作自己的数据集,然后修改配置训练,最后验证训练结果。新手小白0基础建议一步一步跟着来,哪里看不懂的或者遇到哪有问题可以评论区交流~_yolov9训练自己的数据集
https://blog.csdn.net/qq_67105081/article/details/142822519?spm=1001.2014.3001.5502遇到报错可以打开评论区交流。 关注微信公众号 快速联系我~