为什么需要P2P
在人工智能计算、科学模拟和高性能计算领域,多GPU协同工作已成为突破算力瓶颈的必然选择。以NVIDIA RTX 4090为例,这款基于Ada Lovelace架构的旗舰GPU拥有24GB GDDR6X显存和高达1TB/s的显存带宽,但当面对需要多卡协同的大型深度学习模型训练(如LLM大语言模型)或超大规模流体力学仿真时,传统的多GPU通信架构会暴露显著性能瓶颈。这就是我们需要引入P2P(Peer-to-Peer)直连访问的核心动因。
传统多GPU系统通过PCIe总线经CPU中转进行数据传输,这种设计存在双重限制:首先,PCIe 4.0 x16的理论带宽仅31.5GB/s,仅相当于RTX 4090显存带宽的3%;其次,CPU介入带来的额外延迟会显著增加通信开销。在ResNet-152等典型模型中,参数同步时间可能占据总训练时间的40%以上。这种架构缺陷在需要频繁交换数据的场景(如GNN图神经网络的多节点特征传递)中尤为致命。
P2P技术的革命性在于突破传统内存层级限制,允许GPU通过NVLink或PCIe Switch直接访问对等显存。这种点对点通信模式带来三重优势:第一,消除CPU中介环节,将端到端延迟降低至微秒级,这对实时推理场景至关重要;第二,借助RTX 4090支持的第三代NVLink(双向带宽达600GB/s),可建立比PCIe快20倍的直连通道;第三,支持非对称访问拓扑,使4卡系统中的每个GPU都能建立直接通信路径。
在具体应用层面,P2P的价值体现在多个维度。对于CUDA开发者,通过cudaDeviceEnablePeerAccess API开启直连后,多卡间的张量搬运可直接映射为设备内存拷贝,无需通过Host Memory中转。这在多模态AI训练中意味着Embedding层的跨卡拼接耗时可从毫秒级降至纳秒级。对于HPC集群,结合GPUDirect RDMA技术,可实现跨节点的显存直接访问,这对分布式量子化学计算等需要TB级数据交换的领域具有战略意义。
从硬件演进角度看,RTX 4090的P2P能力得益于其创新的Ada架构设计:18个第三代RT Core和72个第四代Tensor Core构成的计算阵列,配合1,310亿晶体管实现的并行处理能力,使得显存带宽资源的高效利用变得尤为关键。当多个这样的计算单元通过P2P形成统一内存空间时,系统可自动实现计算任务的动态负载均衡,这对需要处理不规则数据结构的应用(如元宇宙场景的实时光线追踪)具有颠覆性优化效果。
值得注意的是,P2P的价值不仅体现在性能提升层面。在能效比日益重要的今天,直连架构可减少约35%的冗余数据搬运功耗。根据NVIDIA官方测试数据,8卡RTX 4090集群在使用P2P后,在BERT-Large训练任务中每瓦特性能提升达22%。这种能效优化对构建绿色数据中心和满足欧盟最新能效法规具有现实意义。
因此,理解并正确配置P2P直连访问,已成为释放多GPU系统潜力的关键。特别是在Ubuntu这类高性能计算首选操作系统中,通过合理设置GPU拓扑、NVLink桥接和CUDA环境,开发者可以最大限度发挥RTX 4090的硬件优势,为下一代计算密集型应用构建坚实的加速基础。
前期准备
删除系统中的所有与NVIDIA有关的驱动与内核文件(或者重装系统)
以删除驱动程序为例
sudo apt-get --purge remove "*nvidia*"sudo apt-get --purge remove "*cuda*" "*cudnn*" "*cublas*" "*cufft*" "*cufile*" "*curand*" "*cusolver*" "*cusparse*" "*gds-tools*" "*npp*" "*nvjpeg*" "nsight*" "*nvvm*" "*libnccl*"Bios设置
需要开启Resize BAR(具体位置或者开启方式需要咨询厂家),关闭Intel Vd-T 和 AMD iommu 功能
Troubleshooting — NCCL 2.25.1 documentation

IO virtualization (also known as VT-d or IOMMU) can interfere with GPU Direct by redirecting all PCI point-to-point traffic to the CPU root complex, causing a significant performance reduction or even a hang. You can check whether ACS is enabled on PCI bridges by running:
sudo lspci -vvv | grep ACSCtl
重启,进入BIOS,关闭IOMMU 和PCI ACS。再次启动,就恢复正常了。
NVIDIA显卡的P2P通信通常依赖MAILBOXP2P硬件接口,但在RTX 4090上该接口被禁用或不存在,导致早期驱动错误报告P2P可用性,实际通过PCIe总线传输数据时引发系统崩溃(如触发显存越界操作)。随着RTX 3090/4090引入大BAR支持(如4090的BAR1显存扩展至32GB),NVIDIA在H100中新增BAR1P2P模式,直接通过PCIe BAR实现点对点传输。技术团队尝试在4090上绕过硬件抽象层,调用GH100方法强制启用BAR1P2P:通过kbusEnableStaticBar1Mapping_GH100映射显存至BAR1后,发现运行P2P测试程序时触发MMU错误。分析发现4090不支持GMMU_APERTURE_PEER映射类型,需改用GMMU_APERTURE_SYS_NONCOH类型并修正物理地址处理逻辑。调整后实测传输带宽达24.21GB/s,但数据验证失败。进一步排查发现需将peer地址字段fldAddrPeer替换为系统内存地址字段fldAddrSysmem,并正确配置BAR1基地址。最终成功实现跨GPU数据传输,验证了通过BAR1P2P在消费级显卡绕开硬件限制的可行性,展现了NVIDIA驱动层设计的扩展潜力。
安装其余软件环境
sudo apt install git cmake gcc g++做完上述步骤后,重启
关闭 Nouveau driver
udo bash -c "echo blacklist nouveau > /etc/modprobe.d/blacklist-nouveau.conf"
sudo bash -c "echo options nouveau modeset=0 >> /etc/modprobe.d/blacklist-nouveau.conf"
sudo update-initramfs -u
sudo reboot驱动安装
wget -c https://us.download.nvidia.com/XFree86/Linux-x86_64/565.57.01/NVIDIA-Linux-x86_64-565.57.01.run在安装时,选择无kernel 模组安装(因为后续P2P内核需要重新编译)
sudo sh ./NVIDIA-Linux-x86_64-565.57.01.run --no-kernel-modules选择MIT/GPL






这里选NO

现在驱动就安装好了
安装内核
从github链接中下载驱动对应的open内核版本(如果为其他版本可以下载后切换或者直接下ZIP)
仓库为:GitHub - tinygrad/open-gpu-kernel-modules: NVIDIA Linux open GPU with P2P support
git clone [email protected]:tinygrad/open-gpu-kernel-modules.gitcd open-gpu-kernel-modulessudo ./install.sh出现这个界面后即为安装成功
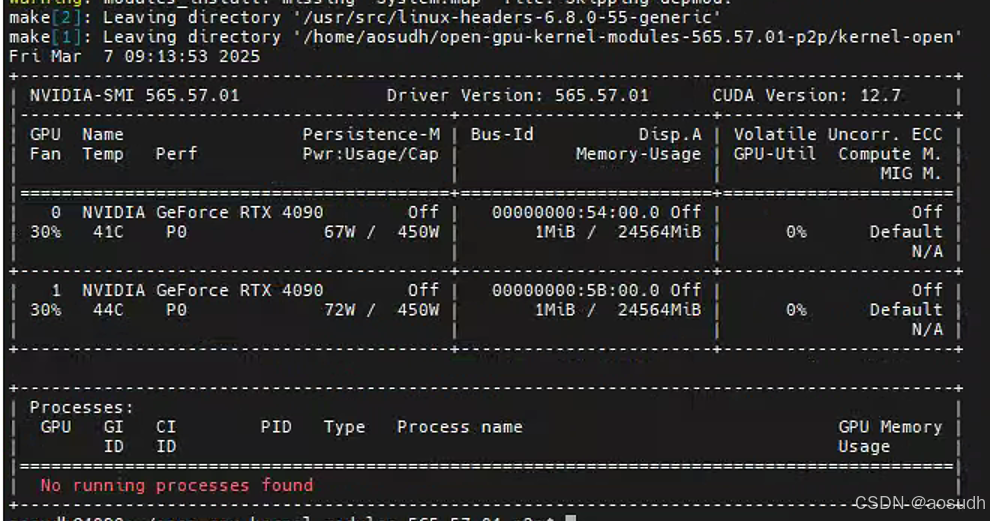
驱动测试
可以看到P2P功能正常开启
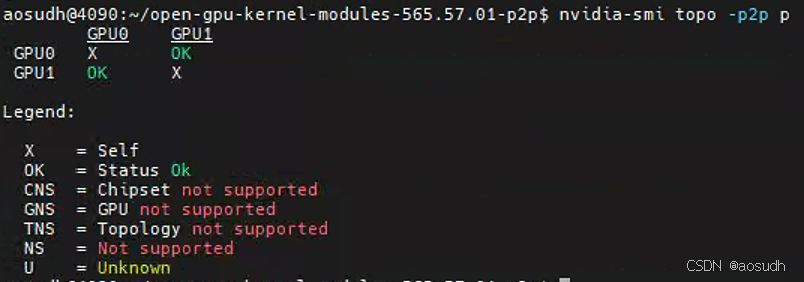
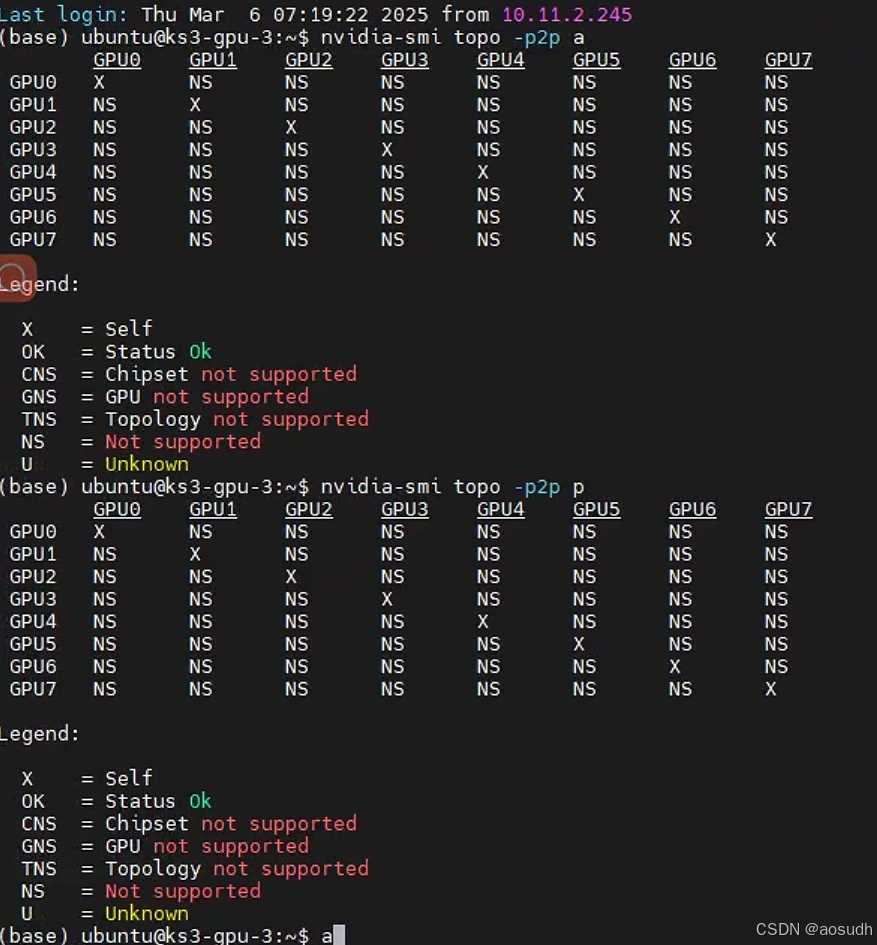
未开启P2P时结果如下
CUDA安装与CUDA SAMPLES 下载
该驱动版本最高支持到CUDA 12.7,因此可以选择CUDA 12.6或12.4 安装
CUDA Toolkit 12.6 Update 3 Downloads | NVIDIA Developer
CUDA Toolkit 12.4 Downloads | NVIDIA Developer
安装后从Releases · NVIDIA/cuda-samples · GitHub中下载CUDA 对应版本的CUDA SAMPES,
下载后编译安装即可
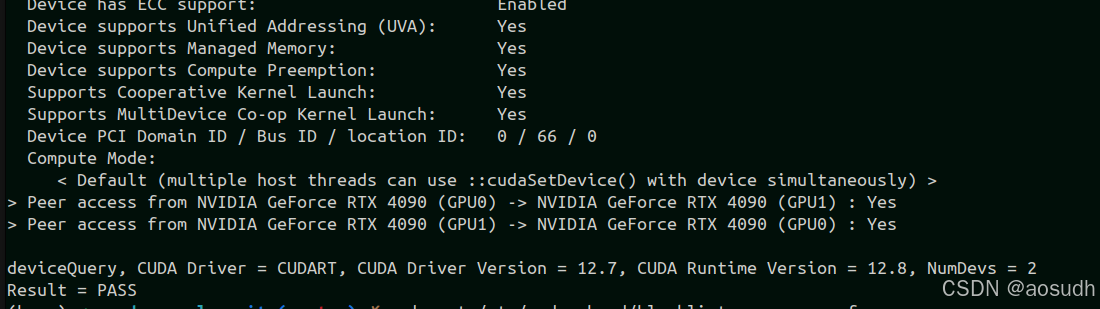
简单测试结果
deviceQuery
P2Pbandwidthtest

simpleP2P

其他文章