
文章目录
Sentence-BERT论文解析
论文地址:https://arxiv.org/abs/1908.10084
代码地址:https://github.com/UKPLab/sentence-transformers
一、摘要
标准的三段式:目前的方法弊端——这篇文章的提出——这篇文章方法的效果
目前的方法弊端
目前的方法:BERT(Devlin等人,2018)和RoBERTA(Liu et al,2019)在语义文本相似性(STS)等双对回归任务上设置了最先进的性能。
弊端:然而,它需要将两个句子都输入到网络中,这导致了巨大的计算开销:在10000个句子的集合中找到最相似的一对需要大约5000万次推理计算(约65小时)BERT的构造使其不适合语义相似性搜索以及聚类等无监督任务。
- 句子的输入导致巨大的计算开销。
- 计算时间太长让BERT不适用语义相似度搜索或者无监督任务。
实际上,语义相似度搜索关系比较大,因为BERT系列就是在语义相似度任务上性能取得了突破。
这篇文章的提出
Sentence-BERT(SBERT):对预训练的BERT网络的修改,使用连体和三联体网络结构(siamese and triplet network structures)来获得语义上有意义的句子嵌入,可以使用余弦相似度进行比较。这将BERT或RoBERTa寻找最相似对的时间从65小时减少到SBERT的约5秒,同时保持BERT的准确性。
这篇文章方法的效果
我们在常见的STS任务和迁移学习任务中评估了SBERT和SRoBERTA,它优于其他最先进的句子嵌入方法。
二、介绍
模型来源
提出的Sentence-BERT(SBERT),是BERT网络的一种修改,使用siamese和triplet网络,能够导出语义上有意义的句子嵌入(语义上有意义的意思是语义相似的句子在向量空间中是接近的)。
这些任务BERT还不适用:大规模语义相似性比较、聚类和通过语义搜索进行信息检索。
BERT的优势与劣势
BERT在各种句子分类和配对回归任务上设置了新的最先进的性能。BERT使用交叉编码器:将两个句子传递给Transformer网络并预测目标值。 然而,由于可能的组合太多,此设置不适合各种配对回归任务。在n = 10 000个句子的集合中找到具有最高相似度的对需要BERT进行 n·(n−1)=2 = 49 995 000次推理计算。在现代的V100 GPU上,这需要大约65个小时。类似地,在Quora的4000多万个现有问题中找出哪一个与新问题最相似,可以建模为与BERT进行成对比较,但是,回答单个查询需要超过50个小时。
语义嵌入模型
聚类和语义搜索的一种常用方法是将每个句子映射到一个向量空间,使得语义相似的句子接近。 研究人员已经开始将单个句子输入BERT并导出固定大小的句子嵌入。最常用的方法是:
- 平均BERT输出层。(称为BERT嵌入);
- 使用第一个标记([CLS]标记)的输出;
正如我们将展示的那样,这种常见的做法产生了相当糟糕的句子嵌入,通常比平均GloVe嵌入更糟糕(彭宁顿et al,2014)。
提出SBERT
为了缓解这一问题,我们开发了SBERT。siamese网络架构使得可以导出输入句子的固定大小的向量。 使用相似性度量,如余弦相似性或哈曼顿/欧式距离,可以找到语义相似的句子。这些相似性度量可以在现代硬件上非常有效地执行,允许SBERT用于语义相似性搜索以及聚类。在10000个句子的集合中找到最相似的句子对的复杂性从BERT的65小时减少到10000个句子嵌入的计算(使用SBERT约5秒)和计算余弦相似性(~0.01秒)。通过使用优化的索引结构,找到最相似的Quora问题可以从50小时减少到几毫秒(约翰逊等人,2017)。
SBERT的实验效果
我们在NLI数据上微调SBERT,这个方法创建的句子嵌入明显优于其他最先进的句子嵌入方法,如InferSent(Conneau等人,2017)和通用句子编码器(Cer等人,2018)。在七个语义文本相似性(STS)任务中,SBERT与InferSent相比提高了11.7分,与Universal Sentence Encoder相比提高了5.5分。(Conneau和Kiela,2018),句子嵌入的评估工具包,我们分别实现了2.1和2.6分的改进。
SBERT可以适应特定的任务。它在具有挑战性的论点相似性数据集(Misra et al,2016)和三元组数据集上设置了新的最先进的性能,以区分来自维基百科文章不同部分的句子(Dor et al,2018)。
三、相关工作
介绍BERT
BERT(Devlin等人,2018)是一个预先训练的Transformer网络(Vaswani et al,2017),为各种NLP任务设置了新的最先进的结果,包括问题回答,句子分类和配对回归。BERT的配对回归输入由两个句子组成,由一个特殊的[SEP]标记分隔。应用12层(基本模型)或24层(大模型)的多头注意力,并将输出传递给一个简单的回归函数以获得最终标签。使用这种设置,BERT设置一个在语义文本半度(STS)基准测试中,我们获得了最新的性能(Cer et al,2017)。RoBERTa(Liu et al,2019)表明,BERT的性能可以通过对预训练过程进行小的调整来进一步提高。我们还测试了XLNet(Yang et al,2019),但它通常导致比BERT更差的结果。
BERT不会计算独立的句子嵌入
BERT网络结构的一个很大的缺点是没有计算独立的句子嵌入,这使得很难从BERT中获得句子嵌入。为了绕过这个限制,研究人员通过BERT传递单个句子,然后通过平均输出(类似于平均单词嵌入)或使用特殊CLS令牌的输出(例如:May et al(2019); Zhang等人(2019); Qiao等人(2019))。这两个选项也提供了流行的BERT作为一个服务库。据我们所知,到目前为止,还没有评估,如果这些方法导致有用的句子嵌入。
句子嵌入的进展
句子嵌入是一个很好的研究领域,有几十种方法被提出。Skip-Thought(Kiros et al,2015)训练编码器-解码器架构来预测周围的句子。InferSent(Conneau等人,2017)使用斯坦福大学自然语言推理数据集的标记数据(Bowman等人,2015)和MultiGenre NLI数据集(威廉姆斯等人,2018)训练一个在输出上使用最大池化的连体BiLSTM网络。Conneau等人表明,InferSent始终优于SkipThought等无监督方法。通用句子编码器(Cer et al,2018)训练了一个Transformer网络,并通过对SNLI的训练来增强无监督学习。Hill et al(2016)表明,训练句子嵌入的任务会显著影响其质量。(Conneau等人,2017年; Cer等人,Yang et al(2018)发现SNLI数据集适用于训练句子嵌入。提出了一种使用siamese DAN和siamese Transformer网络对Reddit会话进行训练的方法,在STS基准数据集上取得了良好的效果。
Humeau et al(2019)解决了BERT的交叉编码器的运行时开销,并提出了一种方法(poly-encoders)来计算m个上下文向量和使用注意力预先计算的候选嵌入之间的得分。这个想法适用于在更大的集合中找到得分最高的句子。然而,polyencoders有一个缺点,即得分函数不是对称的,并且对于聚类这样的用例来说计算开销太大,这需要 O ( n 2 ) O(n^2) O(n2)得分计算。
以前的神经句子嵌入方法从随机初始化开始训练。在本文中,我们使用预先训练好的BERT和RoBERTa网络,只对其进行微调以产生有用的句子嵌入。这大大减少了所需的训练时间:SBERT可以在不到20分钟的时间内进行调整,同时产生比同类句子嵌入方法更好的结果。
四、模型
SBERT将池化操作添加到BERT / RoBERTa的输出中,以获得固定大小的句子嵌入。我们实验了三种池化策略:使用CLS令牌的输出,计算所有输出向量的平均值(MEAN策略),以及计算输出向量的最大值(MAX策略)。默认配置为MEAN。
为了微调BERT / RoBERTa,我们创建了连体和三元组网络(Schroff et al,2015)来更新权重,使得生成的句子嵌入在语义上有意义,并且可以与余弦相似度进行比较。
网络结构取决于可用的训练数据。我们使用以下结构和目标函数进行实验。
分类目标函数。我们将句子嵌入u和v与元素差异|u−v|连接起来,并将其与可训练权重 W t ∈ R 3 n × k W_t \in \mathbb{R}^{3 n \times k} Wt∈R3n×k相乘:
o = softmax ( W t ( u , v , ∣ u − v ∣ ) ) o=\operatorname{softmax}\left(W_t(u, v,|u-v|)\right) o=softmax(Wt(u,v,∣u−v∣))
其中n是句子嵌入的维度,k是标签的数量。我们优化了交叉熵损失。这个结构如图1所示。
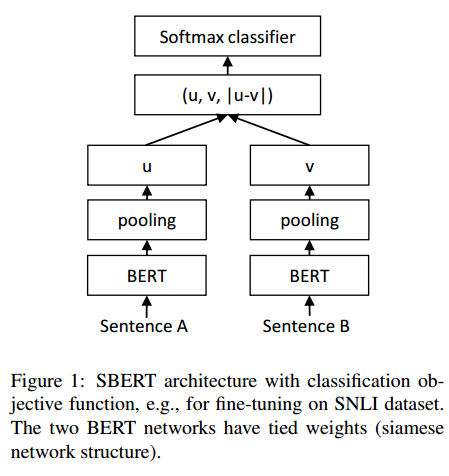
具有分类目标函数的SBERT架构,例如,用于对SNLI数据集进行微调。两个BERT网络具有绑定的权重(连体网络结构)
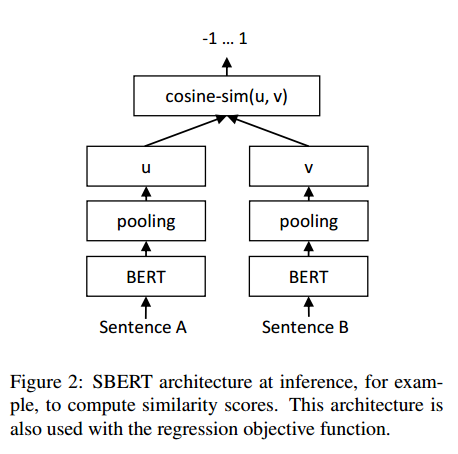
回归目标函数。计算两个句子嵌入u和v之间的余弦相似度(图2)。我们使用均方误差损失作为目标函数。
三元组目标函数。给定一个锚点句a,一个肯定句p和一个否定句n,三元组损失调整网络,使得a和p之间的距离小于a和n之间的距离。数学上,我们最小化以下损失函数:
max ( ∥ s a − s p ∥ − ∥ s a − s n ∥ + ϵ , 0 ) \max \left(\left\|s_a-s_p\right\|-\left\|s_a-s_n\right\|+\epsilon, 0\right) max(∥sa−sp∥−∥sa−sn∥+ϵ,0)
其中 s x s_x sx是a/n/p的句子嵌入,|| · ||是距离度量和边界值 ϵ \epsilon ϵ。边界值 ϵ \epsilon ϵ确保 s p s_p sp至少比 s n s_n sn更接近 s a s_a sa。作为度量,我们使用欧几里德距离,并在实验中设置 ϵ = 1 \epsilon= 1 ϵ=1。
4.1 对于三元组目标函数的理解
在对比损失(Contrastive Loss)或三元组损失(Triplet Loss)中,表达式
max ( ∥ s a − s p ∥ − ∥ s a − s n ∥ + ϵ , 0 ) \max \left(\left\|s_a - s_p\right\| - \left\|s_a - s_n\right\| + \epsilon, 0\right) max(∥sa−sp∥−∥sa−sn∥+ϵ,0)
的 ϵ \epsilon ϵ(margin,边界值) 是一个超参数,其作用如下:
1. 控制相似性判别的严格程度
- ϵ \epsilon ϵ 定义了正样本对( s a s_a sa 和 s p s_p sp)与负样本对( s a s_a sa 和 s n s_n sn)之间距离的最小允许差距。
- 只有当 ∥ s a − s p ∥ − ∥ s a − s n ∥ + ϵ > 0 \left\|s_a - s_p\right\| - \left\|s_a - s_n\right\| + \epsilon > 0 ∥sa−sp∥−∥sa−sn∥+ϵ>0 时,损失才不为零,此时模型需要优化以减少这种差异。
- 较大的 ϵ \epsilon ϵ:要求正样本对和负样本对的距离差距更大,模型学习更严格的相似性判别(更难满足条件,损失更易被激活)。
- 较小的 ϵ \epsilon ϵ:允许更宽松的判别(损失仅在正、负样本对非常接近时激活)。
2. 防止模型坍塌(Collapse)
- 如果没有 ϵ \epsilon ϵ(或 ϵ = 0 \epsilon=0 ϵ=0),模型可能将所有样本映射到同一特征点(即 ∥ s a − s p ∥ = ∥ s a − s n ∥ = 0 \left\|s_a - s_p\right\| = \left\|s_a - s_n\right\| = 0 ∥sa−sp∥=∥sa−sn∥=0),此时损失为零,但失去了判别能力。
- ϵ \epsilon ϵ 强制模型学习有意义的特征,确保正样本对的距离比负样本对的距离至少小 ϵ \epsilon ϵ。
3. 平衡优化难度
- ϵ \epsilon ϵ 决定了模型需要“努力”的程度。例如:
- 若 ϵ = 1.0 \epsilon=1.0 ϵ=1.0,则要求 ∥ s a − s p ∥ \left\|s_a - s_p\right\| ∥sa−sp∥ 至少比 ∥ s a − s n ∥ \left\|s_a - s_n\right\| ∥sa−sn∥ 小 1.0 1.0 1.0 才算合格。
- 若 ϵ = 0.2 \epsilon=0.2 ϵ=0.2,则只需差距超过 0.2 0.2 0.2 即可。
4. 实际应用中的选择
- ϵ \epsilon ϵ 通常需要根据任务和数据调整,常见值在 0.1 0.1 0.1 到 1.0 1.0 1.0 之间(如人脸识别中常用 0.2 0.2 0.2)。
- 过大的 ϵ \epsilon ϵ 可能导致训练困难(难以收敛),过小则可能导致判别力不足。
5. 公式的直观解释
- 损失函数希望:
∥ s a − s p ∥ + ϵ < ∥ s a − s n ∥ \left\|s_a - s_p\right\| + \epsilon < \left\|s_a - s_n\right\| ∥sa−sp∥+ϵ<∥sa−sn∥
即正样本对的距离 + ϵ \epsilon ϵ 仍小于负样本对的距离。如果不满足,则产生损失,推动模型优化。
4.2 训练详细信息
我们训练SBERT是基于SNLI(Bowman等人,2015)和多类型NLI(威廉姆斯等人,2018)数据集的组合。SNLI是570000个句子对的集合,这些句子对用标签contradiction,eintailment和neutral进行注释。MultiNLI包含430000个句子对,涵盖了一系列口语和书面文本的类型。我们用3种softmax-classifier目标函数对SBERT进行了微调。我们使用了batchsize为16,Adam优化器,学习率为2e-5,线性学习率预热超过10%的训练数据。我们默认的池化策略是MEAN。