背景:
最近做实验的过程中发现,随着训练集的平均交叉熵损失(Average Cross Entropy,ACE)降低,验证集ACE升高时,分类模型的准确率(Accuracy,ACC)也会出现升高的情况。起初认为这是反直觉的,还以为是自己程序里有bug。经查阅发现也有人遇到相同的问题,并且对这个现象给出了解释(详情见参考链接1)。
通过一下午的认真思考,尝试将ACC与ACE之间的关系进行整理。我理解不对的地方,或者有更加规范的证明方法,劳烦指教~
正文:
一、交叉熵损失
如下为对应于Softmax回归的交叉熵损失函数(来自于UFLDL教程):
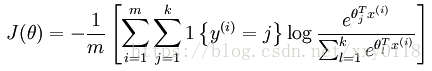
二、单个样本的ACC与ACE关系分析
想分析一批训练数据会使ACC与ACE产生什么样的关系,需要首先了解单个样本时ACC与ACE可以有什么样的关系。
如下为交叉熵损失函数退化为单样本时的公式:
J(θ)=-1 *1{y=label} * logP(y=label)
单个样本时,ACC和CE(Cross E )会出现以下9种情况:
| CE\ACC | 上升 | 不变 | 下降 |
| 上升 | ①:二分类时不存在,多分类时存在 | ②:存在 | ③:正常 |
| 不变 | ④:二分类时不存在,多分类时存在 | ⑤:正常 | ⑥:二分类时不存在,多分类时存在 |
| 下降 | ⑦:正常 | ⑧:存在 | ⑨:二分类时不存在,多分类时存在 |
以上9种情况中,③、⑤、⑦被标记为“正常”情况,比较容易理解且符合直觉,因此不再解释。如下解释其他6种情况:
1. 情况① & 情况⑨
这两种情况是相对的,以情况①为例进行分析(情况⑨将前后两次迭代结果调换即可):
情况①为CE上升,同时ACC也上升。“ACC上升”代表“该样本第一次迭代时被分错,第二次迭代时分类正确”。
A. 二分类
假设样本label=1,两次迭代的得到的分类概率情况如下:
| 迭代次数 | Iter 1 | Iter 2 |
| P | P(y=1)=0.49 P(y=0)=0.51 |
P(y=1)=0.51 P(y=0)=0.49 |
| ACC | 0/1 | 1/1 |
| ACE | -log0.49(大) | -log0.51(小) |
由上表可以清晰看出,二分类时,该样本ACC上升,P(y=label)一定是从一个小于0.5的值,变为大于0.5的值。-log(x)在(0,1]区间内单调递减,因此这种情况下,CE一定变小,与情况①所述现象矛盾,因此该情况对于单样本、二分类来说,不存在。
B. 多分类
假设样本label=2,两次迭代的得到的分类概率情况如下:
| 迭代次数 | Iter 1 | Iter 2 |
| P | P(y=2)=0.49 P(y=1)=0.5 P(y=0)=0.01 |
P(y=2)=0.4 P(y=1)=0.3 P(y=0l)=0.3 |
| ACC | 0/1 | 1/1 |
| ACE | -log0.49(小) | -log0.4(大) |
多分类时,样本ACC上升,P(y=label)是从一个小值变大值,大值变为小值或者不变,都有可能的。由上表可以清晰看出,ACC上升,CE也上升了。因此该情况对于单样本,多分类来说,是存在的。
2. 情况② & 情况⑧
这两种情况是相对的,以情况②为例进行分析(情况⑧将前后两次迭代结果调换即可)。
二分类时(多分类时也容易举例),假设样本label=1,两次迭代的得到的分类概率情况如下:
| 迭代次数 | Iter 1 | Iter 2 |
| P | P(y=1)=0.49 P(y=0)=0.51 |
P(y=1)=0.01 P(y=0)=0.99 |
| ACC | 0/1 | 0/1 |
| ACE | -log0.49(小) | -log0.01(大) |
3. 情况④ & 情况⑥
这两种情况是相对的,以情况④为例进行分析(情况⑥将前后两次迭代结果调换即可):
A. 二分类
同情况①,二分类时,该样本ACC上升,P(y=label)一定是从一个小于0.5的值,变为大于0.5的值。-log(x)在(0,1]区间内单调递减,因此这种情况下,CE一定变小,与情况④所述现象矛盾,因此该情况对于单样本、二分类来说,不存在。
B. 多分类
假设样本label=2,两次迭代的得到的分类概率情况如下:
| 迭代次数 | Iter 1 | Iter 2 |
| P | P(y=2)=0.4 P(y=1)=0.5 P(y=0)=0.1 |
P(y=2)=0.4 P(y=1)=0.3 P(y=0l)=0.3 |
| ACC | 0/1 | 1/1 |
| ACE | -log0.4 | -log0.4 |
由上表可以清晰看出,ACC上升,CE可以保持不变。因此该情况对于单样本,多分类来说,是存在的。
三、多个样本的ACC与ACE关系分析
平均交叉熵损失考虑了多个样本的情况,因此可能性非常多。无论是二分类还是多分类,上述9种情况都有可能出现。
四、总结
我的工作为二分类问题,在此对我这两天的思考进行如下总结:
1. 对于单个样本CE升高,这意味着:A. 如果ACC下降,模型过拟合;B. 如果ACC不变,原本分错的数据(p(y=1)=0.49)可能会错的更离谱(p(y=1)=0.01);原本分对的数据(p(y=1)=0.99)可能会变得没有那么"确定"(p(y=1)=0.51)。不论是A还是B,CE升高都不是一个好的现象。
2. 对于包含多个样本的训练集(验证集或测试集)来说,无论是什么现象,都可以用单样本的9种情况排列组合进行N种可能的解释。但是由1.知,无论怎么组合,ACE升高终归都不是一个好的现象,只是在多样本的情况下,这个结论变得没有那么绝对而已。
参考链接1:https://www.zhihu.com/question/65439175/answer/231303779