redis集群由于各种原因,可能需要下线机器,例如某台机器经常故障,需要换掉;例如某些时间段不需要那么多机器,都可以下线机器。某些时刻又需要增加机器,例如淘宝双十一促销,京东618等。下面我来实践redis官方集群的节点伸缩。这个例子单机实现集群。
ps:建议使用redis-trib.rb,能够避免新节点已经加入过其他集群,造成故障
一、节点增加
1、前期准备
1)创建配置文件

配置的说明可以看我上一篇文章
2)复制多份文件
sed "s/7000/7007/g" redis-7000.conf >redis-7007.conf

3)启动前面6个redis,查看进程

4)将这六个redis都加入集群
redis-trib.rb create --replicas 1 127.0.0.1:7000 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003
127.0.0.1:7004 127.0.0.1:7005
回车,过一会输入yes,得到最终结果,他们都加入集群了

5)验证是否加入集群并分配槽,看到以下信息说明正确
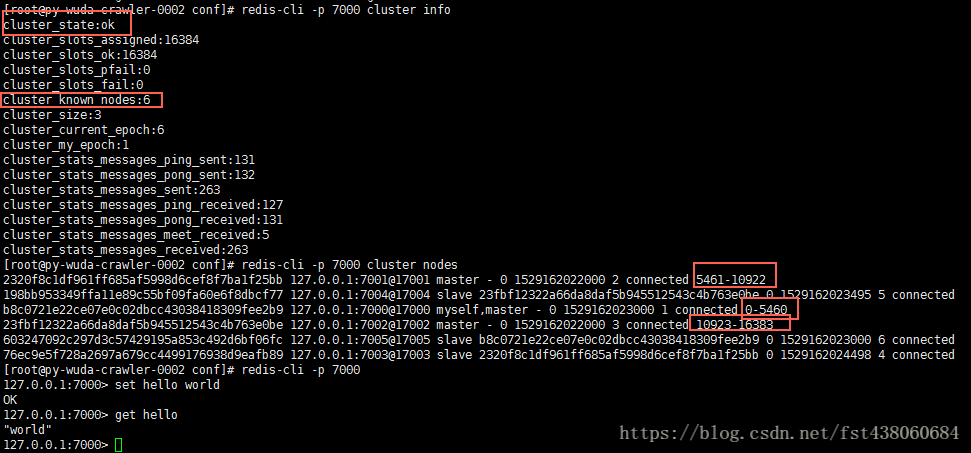
2、增加节点:
原理:其实就是meet操作
1)启动要增加的两个节点
redis-server redis-7006.conf
redis-server redis-7007.conf
7007作为从节点。
2)添加节点
查看官方的命令,redis-trib.rb如下:
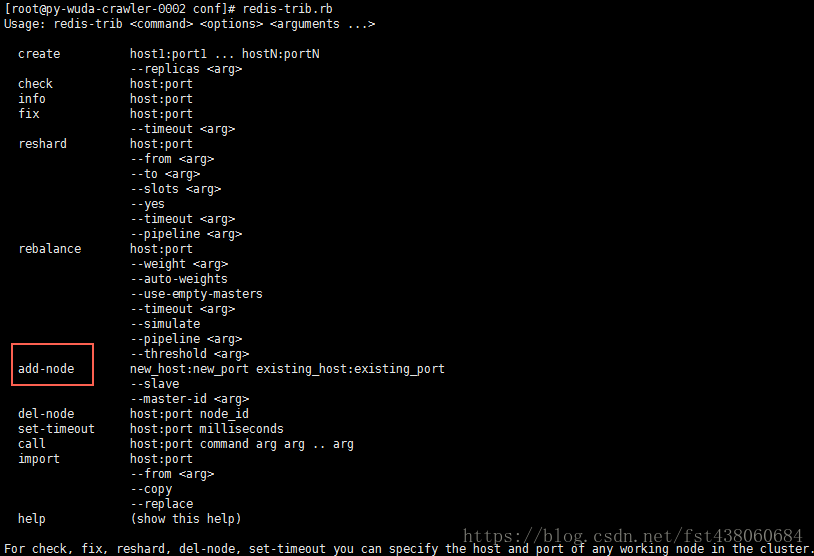
有个add-node 就是加入集群的命令
先把从节点加入7000的集群
redis-trib.rb add-node 127.0.0.1:7006 127.0.0.1:7000
找出7006的id,把7007以从节点的形式加入7000的集群
redis-trib.rb add-node --slave --master-id b818ae7a3a8e8e671d648c4d4ad38a1138ef8dd3
127.0.0.1:7007 127.0.0.1:7000
成功,查看节点信息,刚好4主4从
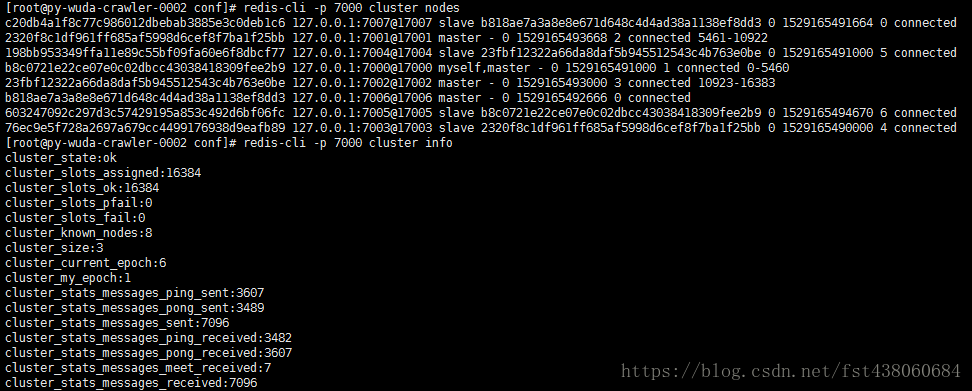
3、迁移槽和数据
加入节点之后,加入的节点是没有分配到槽和数据的,需要我们手动分配
1)迁移槽和数据的原理:
A、对目标节点发送:cluster setslot {slot} import {sourceNodeId}命令,让目标节点准备导入槽的数据。
B、对源节点发送:cluster setslot {slot} migrating {targetNodeId}命令,让源节点准备迁出槽的数据。
C、源节点循环执行cluster getkeysinslot {slot} {count} 命令,每次获取count个数据槽的键。
D、在源节点上执行migrate {targetIp} {targetPort} key 0 {timeout}命令把指定的key做迁移。
E、重复执行步骤3~4直到槽下所有的数据都迁移到目标节点
F、向集群内所有主节点发送cluster setlot {slot} node {targetNodeId}命令,通知槽分配给目标节点。
ps:在这个过程中,3.0.6版本可以使用pipeline进行批量迁移,但是
如果有过期数据和非过期数据键混合,会出bug,但是在3.2.8之后修复了。
2)执行迁移数据
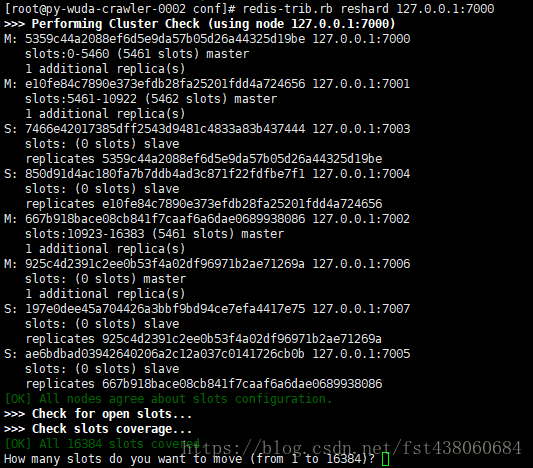
计算好要迁移的数据,4096,输入
找到要迁移的id7006的fefb18c90335bb7359a517f7c4d415e1d0cc3d81
并且所有的节点都要迁移槽,输入all

输入回车之后过一会还有一个提示,输入yes

然后查看槽的分配,成功了

二、节点收缩
添加了节点之后,下面下线7006和7007这个节点
节点下线主要分为以下几个步骤
1、下线槽
如果有槽,下线槽。
先把7006的1365个槽迁移到7000,然后迁移1366个槽到7001,然后迁移1365个槽到7002

迁移成功:

2、忘记节点
下线其实是一个forget的操作 redis-cli -p 7000 cluster forget {downNodeId}
我们这里使用redis-trib.rb 的这个工具的del-node工具,先下线7007再下线7006。(下线节点的时候,需要先下线所有从节点,因为如果先下线主节点,会触发故障自动转移。)
打开redis-trib.rb的源码,找到del-node
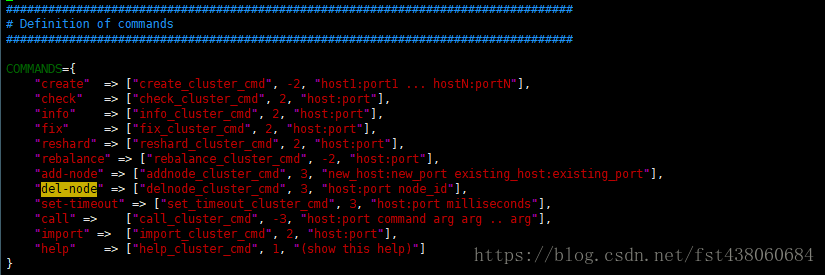
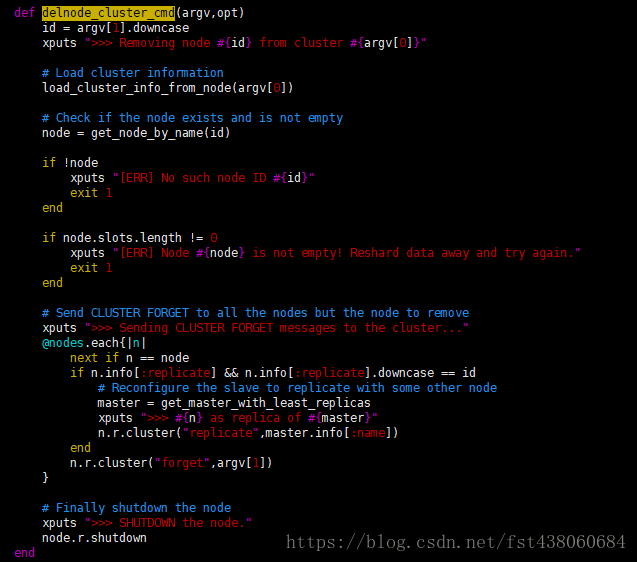
再找到delnode_cluster_cmd,可以看到里面有一个forget操作,说明是执行forget操作
那么开始,下线从节点7007,在下线7006
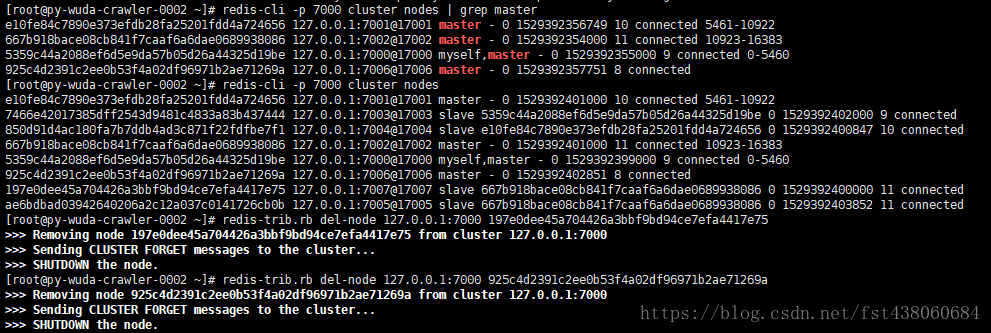
最后查看一下,已经下线成功:
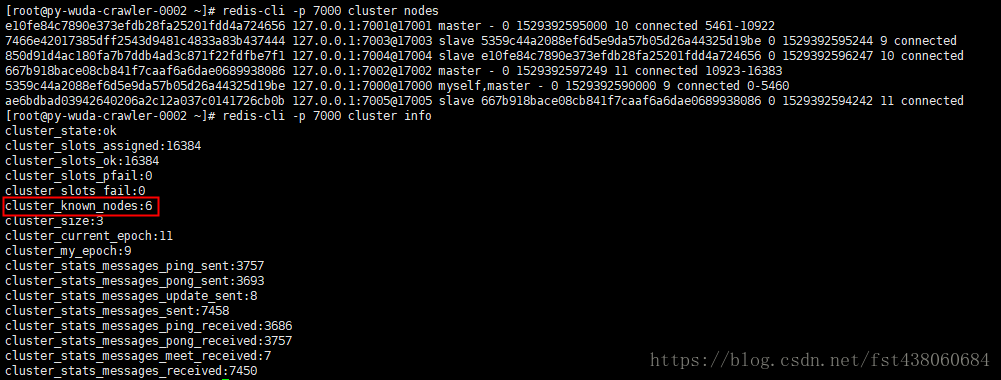
最后注意一下,因为这个例子是在同一个机器没有网络延时,数据量也很少,所以迁移很快。实际生产过程中用到集群的情况下,数据量一般会挺多,迁移需要时间,必须做好计划再迁移。另外用命令行迁移可能会不好操作,也容易出错,可以使用一些开源的可视化工具。