写这篇文章的初衷,是来源于一直以来的一个疑惑:codeblock,GCC编译器下编程,偶尔会出现乱码。那么为什么会乱码呢?里面的本质原因究竟是啥呢? 这几天刚好在研究二进制读写时,又让我想起了这个疑惑,强烈的求知欲让我花了3天查阅并学习了网上的很多资料,加上自己的验证,现在惑因已经消失,为了避免遗忘,特写一篇博文,来详细记录。
首先我要向大家普及一下字符集和编码规则:
博主在查阅相关资料的时候,看到一篇百度文库上未知来源的博文,实在是太赞了,写得很详细,比很多CSDN上的博文不知道高到哪里去嘞,因此特别用超链接引用过来。(要是知道来源的读者,还请告知下。)
为了能够更好的理解,若不清楚相关编码常识的读者务必先去学习下上面所提的这篇文章,或者直接看我总结的干货,之后才接着往下看。
1.字符编码的前世今生 (超链接)
2.干货速递(Unicode 和 UTF -8的区别)
Unicode 是字符集 UTF -8是编码规则
字符集,是为每一个字符映射一个ID
编码规则, 是早期为了进行网络传输字符而规定的 Transfer Format, 顾名思义,也就是转化格式,,是依赖于字符集而制定的。
Unicode 字符集中的每一个字符都有特定的一个ID,例如 【简】的ID是31616,记作U+7B80(31616对应的十六进制为0x7B80)
接下来我将介展示Unicode和UTF-8之间是如何进行转换的:
U+ 0000 ~U+007F :0XXXXXXX
U+ 0080~U+ 07FF: 110XXXXX 10XXXXXX
U+ 0800~U+ FFFF: 1110XXXX 10XXXXXX 10XXXXXX
U+ 10000~U+1FFFF: 11110XXXX 10XXXXXX 10XXXXXX 10XXXXXX
根据上面的编码规则可知,UTF可以将Unicode中的字符对应的ID转换成1 个,,2 个,,3个,,4个字节
直接的【简】字的ID U+ 7B80属于第三行的范围:
7 B 8 0
0111 1011 1000 0000 二进制的 7B80
01111011 10000000
-----------------------------------------------
1110XXXX 10XXXXXX 10XXXXXX 第三行模板
11100111 10101110 10000000 代入模板
E7 AE 80
这就是讲U+7B80 按照UTF-8编码为字节序列 E7AEA5的过程,反之亦然。(不相信的同学可以用16进制文本验证或者转码网站查询)
-------------------- ------------------------开始进入正文-------------------------------------------------
假设读者已经看了上面的文章和干货,并理解了。
由于下面编码和解码这两个词将会被大量使用,为了避免理解混乱,先给大家区分一下
狭义的编码:把字符映射----->数字ID;
狭义的解码 把数字ID-------->字符
广义的编码:包括狭义的编码和狭义的解码,比如编码格式。
文章开头提到,为什么在codeblock编程,输出中文字符串会乱码呢?
首先要知道在codeblock下 新建cpp,,,,,,,,,,, 然后编译,,,,,,,,,再运行,,这三个步骤中发生着字符的编码和解码
(一)当你用CB建立了一个.cpp的文件,你写入了代码,例如
#include<stdio.h>
int main()
{
char s[] = "大";
printf("%s\n", s);
return 0;
}然后保存源文件,此时我设置cb是用Win936(GBK)来编码。
但是我们可以自定义更改CB的编码格式:Settings-----editor-----

那么我先查了下,【大】在GBK下对应的ID是 :B4F3,那么源文件中是否真的有B4F3,这边安利一款超好用的16进制文本编辑器,Winhex,可以查看文件的底层数字。
验证结果如下:
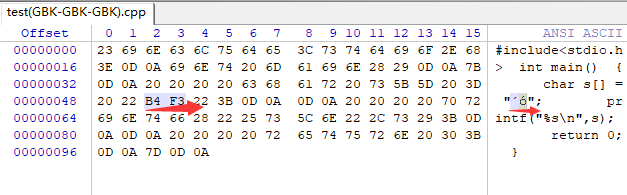
看来我们想的是对的!
用CB新建源文件或者打开一个源文件 发什么了什么,我们来总结一下:
当我们用CB(vs,DEV也是一样)新建一个源文件,会用设置好的某一种编码(上面我用的是GBK)来将我们写的代码中的每一个字符转换为对应的ID(此过程既编码) 【大】------>B4F3
当我们用CB打开一个源文件,会用我们设置好的某一种编码来将这个源文件底层的二进制数字解码成字符,然后展现出来,供人们阅读(这个过程即解码) B4F3 ---------->【大】
注:那么CB的编码和解码过程能不能用不同套的规则啊??比如我想让它编码的时候用GBK,打开源文件解码的时候用UTF-8,
但CB是不允许这样分开设置的。为什么不允许呢?其实这也很容易理解,我用GBK编码的源文件,用UTF-8来解码,这样能正常
显示,不是乱码了吗?
【 大 】 B4F3
GBK下的ID为B4F3 若用UTF-8去解析ID B4F3是代表什么字符,能查得到吗?我是没查到对应什么字符,用
winhex进行强制转化显示的是乱码。
(二)当我用GCC编译了刚刚建立的那个源文件,生成了.o的文件和.exe的执行文件
例如:

这边要先说一下,GCC是可以将编码格式和解码格式设置成不同套的编码规则。不设置都是默认为UTF-8
Settings ------Complier settings-----------other complier options
-fexec-charset=UTF-8(设置GCC的编码规则, 生成exe,,可以任意设置)
-finput-charset=GBK (设置GCC对源文件的解码规则, 对源文件进行解码,可以任意设置)
这边我本地是都设置为GBK

(介绍这些设置,是希望能最大方便读者自己动手测试,验证)
现在让我们来分析下GCC编译过程中对字符的解码和编码过程过程:
还记得上面以GBK编码的源文件吗,编译时,GCC会先对源文件的底层数字进行解码,也就是根据ID解码成字符。
然后再对解析成的字符用对应的编码格式进行编码,编码成数字,然后生成obj文件和exe文件。
按照我上图所示都是设置成GBK时,现在用Winhex进行验证,看看obj文件中【大】对应的ID是不是B4F3:
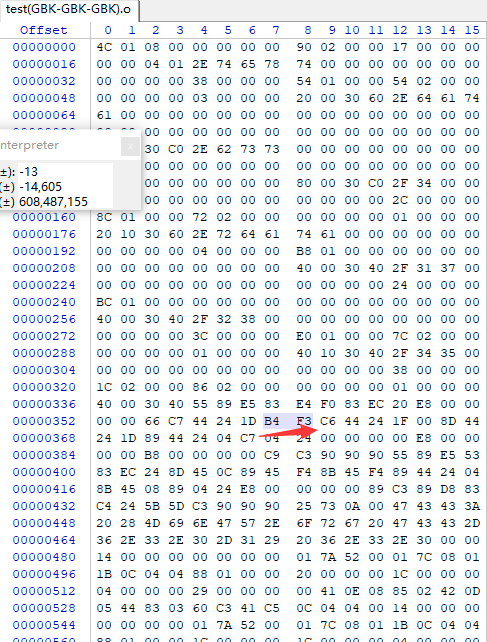
果然对了 :), exe其实就是包含obj文件链接而成的,在底层数字中,【大】也是B4F3的,读者可以自己验证。
(三)运行exe文件,看看Windows控制台输出 先提一下:windows控制台默认用的编码格式是GBK
例如:
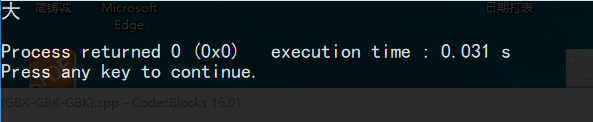
这个过程是发生了什么呢?Windows控制台会对exe中的底层数字进行解码,也就是解析成字符,然后输出。
即用GBK编码格式去把【大】的ID:B4F3解码成了"大”,然后输出。
好了,现在我把建立源文件,GCC编译,Windows控制台运行exe文件的过程中字符的编码和解码过程都给分析了 :)(:
now 消化消化一下对上面的过程的理解,我们要继续往下走了~~ ~下面的内容懂了,才是真正懂了
--------------------------------------彻底理解的最后一里路-----------------------------------------------
提问一:我要怎么分别 设置 CB__GCC_finput__GCC_fexe 这三种编码格式,才会使得Windows控制台运行exe时输出不会乱码呢?
第一个重要规则:要求读取二进制时所用的解码格式要和把字符编码成二进制的编码格式要一致,,,,是不是有点绕口呢,但是这能保证不出错。
我举个例子,假如你从GRE单词书中查询"三磷酸腺苷”这个单词是怎样拼写的,然后你居然要用初中英语词典去翻译这个单词,想想??能查到“三磷酸腺苷”这个意思吗?到头来你还得用GRE单词书去翻译这个单词才能知道它的意思 :) :) :)
第二个重要规则:obj和exe中的ID一定要是字符在GBK下的ID (这条规要是不理解可以先跳过,先看完下面,再回来看,深有体会)
不妨逆过来考虑,,Windows控制台默认的编码格式用的是GBK格式,一般我们不会去改动,那么这就意味着,
假如我要正常的输出【大】这个字,就要保证exe中【大】对应的底层数一定要是[B4F3],,不然我用GBK格式解码时就会出错。
提问二:如果 CB--GCC_finput--GCC_fexe 按照 “GBK_UTF-8_UTF-8"出装”,这样输出中文字符会不会乱码呢(英文字符都是不影响的,英文字符的编码ID在不同编码格式下都是一致的),只有会分析这个问题才能彻底弄明白呢!
为啥我要举这个例子呢,我相信很多人之前跟我一样,不知道所谓的编码格式可以设置的,都是直接用,默认的CB编码格式是GBK,GCC的finput 和 GCC的fexe采用的编码格式都是默认为UTF-8,,,,,说白了“GBK_UTF-8_UTF-8”一直是我们不知情下的默认设置,但是为什么我们输出中文只是偶尔乱码,大多数情况下还是不会乱码的呢,这是不是和提问一所提到的原则一有点矛盾啊?

 ,一定都不矛盾,这只是巧合!!!!你遇到的不会乱码都是侥幸
,一定都不矛盾,这只是巧合!!!!你遇到的不会乱码都是侥幸
为什么啊,cpp不是用GBK编码的吗,,GCC用UTF-8来解码cpp的底层数字时,cpp底层数字都是GBK中的ID,怎么能解析出正常字符呢???( 昨天晚上的疑问,差点把我困住了)
昨天晚上的疑问,差点把我困住了)
肯定解析出非正常字符 ,B4F3如果用UTF-8解析出来,肯定不可能被解析成【大】,假如被解码成"哈”这个字符(我只是假设解析成了这个不正常字符,具体是什么我没查)
为什么啊,既然GCC用UTF-8来解析GBK中的ID,会解析出不正确的字符,那么GCC用UTF-8再解码这些非正常字符时,得到数字还会跟cpp下【大】的底层ID一致吗???(昨天晚上的疑问,差点把我困住了)
哈哈,确实,GCC将GBK中的ID解码成非正确字符,再用UTF-8格式将非正确字符转换成数字。。。。
转换后的数字是有可能==转换前的数字(反而是大多数情况下是可以相等的,乱码说明不相等了)
1.cpp中的【大】对应的ID是B4F3(GBK下的ID)
2.GCC把cpp中的B4F3解码成不正确的字符【哈】(UTF-8下的字符)
3.GCC生成obj和exe时,因为也是用UTF-8编码,所以把【哈】(UTF-8下的字符),又编码成B4F3(UTF-8下的ID)
4.然后我们用Windows 控制台运行exe文件时,用GBK去解码的数字还是B4F3,因此就算2,3步骤不符合编码和解码格式要一致的原则,但是最后侥幸【大】对应的ID:B4F3还没变,所以仍然能正常输出字符【大】
这就是我们一直以来"出装"不合法,当时仍能侥幸不乱码的原因!!!!!!!!!!!!!!
乱码时,是发生了什么呢?
1.cpp中的【大】对应的ID是B4F3(GBK下的ID)
2.GCC把cpp中的B4F3解码时,发现UTF-8中根本没有B4F3这个ID呀,那么就从UTF-8里面含有的字符选一个瞎解析,例如“滫”
3.GCC生成obj和exe时,因为也是用UTF-8编码,所以把【滫】(UTF-8下的字符),编码成AAAA(假设是“滫”在UTF-8下的ID)
4.然后我们用Windows 控制台运行exe文件时,用GBK去解码的数字就不再是B4F3,而是在GBK中去寻找AAAA对应的字符,这时就是GBK中真有AAAA这个ID,那么输出的字符也是不对的,如果没有AAAA这个ID,那么也是不对的。所以这时候就乱码!!!(返回去理解理解第二原则)这时候你曾经拥有的侥幸就一去不复返
。。。。。
假如读者完全理解了我上面的文字,那么 CB__GCC_finput__GCC_fexe 的八种组合“出装”,不用一个一个测试就能知道,会不会乱码啦,,,(哎,想想我昨天还没弄懂时,可是一种一种出装设置,然后用Winhex分别看底层数字呢!!呜呜呜 )
)
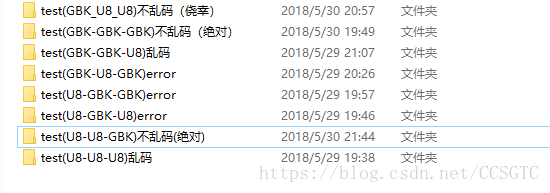
八种出装中,有3种会报错,就算不报错,分析一下也知道最后中文字符在exe中的ID也不可能是其在GBK下对应的ID,肯定会乱码,但是编译器能识别出这几种组合,也算还有点用处吧,建议读者在看懂我的文章后,自己分析每种组合会不会乱码,无需一个一个测试。(按照我上面的分析过程来分析!!!!)
若要转载请注明来处
感谢这个过程中帮助我理解的参考资料:
https://blog.csdn.net/u010234516/article/details/52853214
https://wenku.baidu.com/view/cb9fe505cc17552707220865.html
https://blog.csdn.net/softman11/article/details/6121538