今天呢,小编决定带着6个方面一路探究Web编码。
1、问:为啥要编码?
答:计算机存储信息的最小单位是1字节(bit),然而一个字节最多能表示0-255个符号,但是人类自然语言中的符号又那么多,像汉语、韩语、日语等一个字节怎么能表示的过来,所以必须要有一个新的结构字符来编码。
2、常见的编码格式有哪些?
A、ASCII码
总共128个,使用一个字节的低7位表示,0-31是控制字符如:换行、回车、删除等;32-126是打印字符,可以通过键盘的输入打印出来。
如:
System.err.println('A'+32);
char abcd = 'A' +32;
System.err.println(abcd);得到:

B、ISO-8859-1
ISO提到这个名字我就想到了,食品安全上的那个。ISO组织在ASCII码的基础上利用单个字节的所有位定制了一系列标准扩展ASCII编码,ISO-8859-1仍然是单字节编码,总共256个字符。我们下面提到的浏览器编码规则就是依据于此。
C、GB2312
全称《信息技术中文编码字符串》,它采用双字节编码,范围是A1-F7,其中A1-A9是符号区有682个符号;B0-F7是汉字区包含6763个汉字。
D、GBK
全称《汉字内码扩展规范》是国家技术监督局为windows95定制的新的内码规范,是扩展GB2312用的,因为汉字不止6763个,你懂的。加入了更多的汉字,编码范围是8140-FEFE,总共23940个这下够用了。
E、UTF-16
UTF-16定义了Unicode字符在计算机中的存取方法,UTF-16使用两个字节表示Unicode的转化格式,是固定长度的表示方式,无论什么字符UTF-16都用两个字节表示,两个字节是16位,所以叫UTF-16你又懂得。
F、UTF-8
互联网的普及,市面上所见之处都是UTF-8,是互联网上使用最广泛的Unicode实现方式(下面降Unicode)。上面所讲UTF-16表示起来很方便了,但是存储上是不是多占用了空间,因为无论你用不用都给你2个字节。而UTF-8编码规则如下:
①对于单字节符号,字节的第一位设为0,后7位是这个符号的Unicode码。因此UTF-8包含ASCII码。
②对于n位字节的符号(n>1),第一个字节都设为1,第n+1位设为0,后面字节的前两位一律设为10。其余的都为这个符号的Unicode码。
G、Unicode
就小编知道的编码格式大概有30种左右吧,像阿拉伯文(ASMO 708)、俄语 - 西里尔文(DOS)、日文(Shift-JIS)、中国 - 简体中文(GB2312)、繁体中文(Big5)、Unicode、Unicode (Big-Endian)、中欧(Windows)、西里尔文(KOI8-R)、 西里尔文(KOI8-U)、 阿拉伯文(ISO)、希伯来文(ISO-Visual)、希伯来文(ISO-Logical)、日文(JIS)、韩文(ISO)、日文(EUC)、韩文(EUC)、简体中文(HZ)、Unicode (UTF-7)、Unicode (UTF-8)等。
如果有一种编码将世界上所有符号都纳入其中,每一个符号都给予一个独一无二的编码,那么乱码问题就不会有了对吧,这就是Unicode。Unicode是一个庞大的集合,可以容纳百万计符号。
3、浏览器界面编码格式
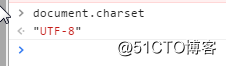
在浏览器调试界面,我们选择控制台,然后输入document.charset即可获取当前界面的编码规则。我们可以看到三种浏览器:谷歌、火狐、IE的编码均为utf-8,因为是互联网上使用最广泛的Unicode实现方式:
4、浏览器URL编码方式
客户端想服务器发送请求四种情况:
1、表单post提交;
2、表单get提交;
3、页面链接;
4、URL方式直接访问
而URL包含中文无非有两种情况:
1、url路径包含中文即
https://abcd/测试/publish
这种类型的,从这么多年的上网经验来讲,我没见过这种路径。
2、url参数包含中文,这问题比较常见。
我们看到当URl包含中文参数时,浏览器做了转码。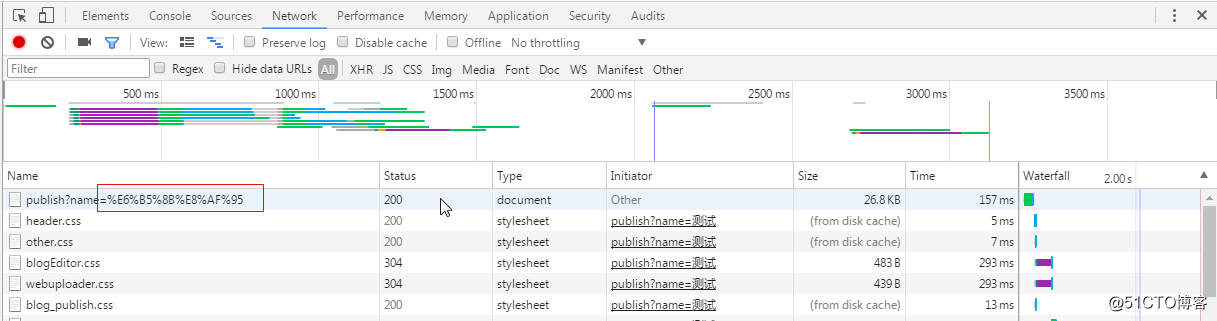
这一点上,分两种情况IE和非IE,因为IE用的是GBK转码,非IE用的是Utf-8转码,而我们在windows系统上查询默认的编码就是GBK。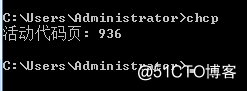
因此,你会发现IE浏览器好像对中文没有做处理一般
在URL进行参数传递的时候,要处理处理中文参数那么这里就要注意了,我们有三种解决方案(javascript转码、配置filter过滤器、修改中间件server.xml),这里我们考虑最简单的js转码方案。用户从浏览器发起一个Http请求,存在编码的地方是URL、Cookie、Parameter。服务器端接受到Http请求后要解析Http,其中URL、Cookie和Post表单参数需要解码、服务器端还可能读取数据库数据或者文本文件,都可能存在编码问题。当servlet处理完所有请求数据后,再将这些数据编码通过socket发送到用户请求的浏览器里,经浏览器解析成文本。
浏览器编码URL是将非ASCII字符按照某种编码格式,编码成16进制的数字后将16进制数字表示的字节前加上%。这个过程就不太美了,因为不同浏览器编码方式可能还不一样,那服务端怎么解,所以我们在应用中尽量避免URl使用非ASCII字符。
问:要是避免不了怎么办呢?
答:我们通过下面的例子一起探究
假如我们在地址栏中有这样的参数地址
http://localhost:2345/redant/test.action?name=测试
我们写一个测试的小demo
<a onclick="test_decode(1)">测试转码问题1</a><br/>
<a onclick="test_decode(2)">测试转码问题2</a><br/>
<a onclick="test_decode(3)">测试转码问题3</a><br/>
<a onclick="test_decode(4)">测试转码问题4</a>
<script>
function test_decode(num){
var url = "";
switch (num) {
case 1:
url = "localhost:2345/redant/test.action?name=测试";
break;
case 2:
url = "localhost:2345/redant/test.action?name=测试";
url = encodeURI(url);
break;
case 3:
url = "localhost:2345/redant/test.action?name=测试";
url = encodeURI(encodeURI(url));
break;
default:
var name = “测试”;
name = encodeURIComponent(encodeURIComponent(name));
url = "localhost:2345/redant/test.action?name="+name;
break;
}
alert(url);
$.post(url);
}
</script>A、在URL中直接传递汉字参数,IE浏览器在java后台得到的关于“测试”的编码是:
但请求的URL并未将测试进行转码。
火狐浏览器在java后台得到的关于“测试”的编码是:
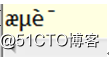
谷歌浏览器在URL请求时,已经转码:%E6%B5%8B%E8%AF%95,
但在java后台得到关于“测试”的编码和火狐一样:

也就是说火狐与谷歌在URL传输中文字符时会进行了转码,但是转码后又被浏览器再次处理了。IE浏览器处理中文字符,不会自动转码,但任然会被浏览器处理,也就是说那么我们拿url = "localhost:2345/redant/test.action?name=%E6%B5%8B%E8%AF%95";之后,三种浏览器的编码解码规则就一致了。
问:那么怎么实现,三种浏览器编码规则一致呢?
答:使用【encodeURI】进行转码,利用encodeURI对中文URL参数进行编码时,“测试”会转为“%E6%B5%8B%E8%AF%95”,但浏览器机制会认为”%”是一个转义字符,浏览器会把地址URL中的传递的已转换的参数”%”与”%”之间的转义字符利用本身机制处理一遍后再传递给后台所以我们使用encodeURI二次转码。
问:那么我们用encodeURI把中文字符二次转码保护起来,是不是就可以了呢?
答:经过encodeURI转码之后,我们可以看到,在IE、谷歌、火狐“测试”的中文转码竟然一致了:
在 java后台得到的关于“测试”的编码,三种浏览器竟然也一致了:

小编看到网络上有好多例子说:在java后台通过
java.net.URLDecoder.decode(name, "Utf-8");
就可以解析“测试”了。
然而小编得到的却是: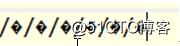
小编懵逼的再问:这到底是什么编码?
java.net.URLDecoder.decode(name, "Utf-8");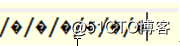
java.net.URLDecoder.decode(name, "GBK");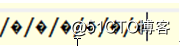
java.net.URLDecoder.decode(name, "ISO-8859-1");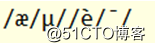
java.net.URLDecoder.decode(name, "GB2312");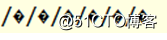
java.net.URLDecoder.decode(name, "UTF-16");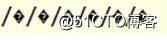
java到底该怎么解析这个编码,等等为啥会带有”/”,那去掉之后呢?
String[] str = name.split("/");
StringBuffer sb = new StringBuffer();
for (int i = 0; i < str.length; i++) {
sb.append(str[i]);
}
System.err.println(sb);
System.err.println(java.net.URLDecoder.decode(sb.toString(), "utf-8"));
终于如愿以偿了
【encodeURI()与encodeURIComponent()】效果一样。也是不得已而为之的一种方法。
【TODO】
果然如此,小编留下一个待测试的地方:就是不同的浏览器,不同的系统,是否都可以使用这个方法。
问:那么为什么会出现”/”呢?小编不得而知。
5、常见编码问题?
上面我们看到,编码如果解析失败,会出现
①一个汉字变成两个乱码字符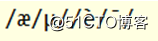
这种情况是因为,字符串在解码时,所使用的字符集与编码的字符集不一致导致的,例如用GBK编码用ISO-8859-1解码,一个汉字变成了两个乱码字符。
②一个汉字变成两个问号
这情况就复杂了,可能是中文经过多次编码造成的,出现这情况你就要仔细看中间编码环节,然后找出编码错误的地方。例如:一个汉字拿GBK编码,然后用ISO-8859-1解码,发现不对,然后再拿GBK编码,最后再拿GBK解码的过程。
③一个汉字变成一个问号
将中文和中文符号经过不支持中文的ISO-8859-1编码后,所有字符变成”?”,这是因为ISO-8859-1进行编码是遇到不在码值范围内的字符统一用3f表示,因此都变成了”?”。例如:一个汉字拿ISO-8859-1编码,再拿ISO-8859-1解码的过程。
④我们跨网站推送数据的时候,有时候用
String name = request.getParameter(“name”);
然后
Name = new String(name.getBytes(“ISO-8859-1”, “GBK”));
竟然得到了正确的中文字符,这是怎么回事?
其实通常是这样的,我们将汉字用GBK编码之后,然后用ISO-8859-1解码得到的当然是我们第一种所提到的那样,然后既然不行那我再拿ISO-8859-1编码回去,用GBK解码。这就是那个过程。
有人会问了,为啥不直接用GBK解码,而是中间走一下ISO-8859-1呢?
答:因为ISO-8859-1是大多数浏览器的默认字符集,还有一些中间件的默认编码也是。小编联想到,encodeURI()它采用的是UTF-8格式输出编码后的字符串。也就是说,我们可以在浏览器中只进行一次转码就好。
url = "localhost:2345/redant/test.action?name=测试";
url =encodeURI(url);
我们在后台按照utf-8来转就好了,即
name = new String(name.getBytes("ISO-8859-1"),"UTF-8");
当然如果编码中有多余的“/”,要处理掉。6、问:Java中那些场景需要编码?
答:两种
①I/O流中,需要指定charset。
②内存操作,也就是项目运行的过程中。