今天看到别人问这个问题,突然想到自己也对这两个经典的线性分类器没有太过区别其异同,所以特此翻阅了一下资料总结了一番。以下理论部分主要参考了LR与SVM的异同这篇文章。这篇文章之后,又写了它的姊妹篇【机器学习】Kernel Logestic Regression 和Kernel SVM
LR和Linear SVM的相同点
- 都是监督的分类算法
- 都是线性分类方法
另外这里需要说的就是LR也是可以加核函数的至于为什么不用,是原因的,后面再说。 - 都是判别模型
判别模型和生成模型是两个相对应的模型。
判别模型是直接生成一个表示P(Y|X) 或者Y=f(X) 的判别函数(或预测模型)
生成模型是先计算联合概率分布P(Y,X) 然后通过贝叶斯公式转化为条件概率。
SVM和LR,KNN,决策树都是判别模型,而朴素贝叶斯,隐马尔可夫模型是生成模型。
生成算法尝试去找到底这个数据是怎么生成的(产生的),然后再对一个信号进行分类。基于你的生成假设,那么那个类别最有可能产生这个信号,这个信号就属于那个类别。判别模型不关心数据是怎么生成的,它只关心信号之间的差别,然后用差别来简单对给定的一个信号进行分类。
对于生成模型和判别模型的更详细的差别到时候再开一个博客来讲
LR和Linear SVM的不同点
LR和Linear SVM本质不同来自于loss function不同
LR的损失函数是cross entropy
SVM的损失函数是最大化间隔距离
不同的loss function代表了不同的假设前提,也就代表了不同的分类原理
LR方法基于 概率理论,假设样本为0或者1的概率可以用sigmoid函数来表示,然后通过极大似然估计的方法估计出参数的值,或者从信息论的角度来看,其是让模型产生的分布
支持向量机基于几何间隔最大化原理,认为存在最大几何间隔的分类面为最优分类面
所以 SVM只考虑分类面上的点,而LR考虑所有点,SVM中,在支持向量之外添加减少任何点都对结果没有影响,而LR则是每一个点都会影响决策。
Linear SVM不直接依赖于数据分布,分类平面不受一类点影响
LR则是受所有数据点的影响,所以 受数据本身分布影响的,如果数据不同类别strongly unbalance,一般需要先对数据做balancing。
SVM不能产生概率,LR可以产生概率
LR本身就是基于概率的,所以它产生的结果代表了分成某一类的概率,而SVM则因为优化的目标不含有概率因素,所以其不能直接产生概率。【虽然现有的工具包,可以让SVM产生概率,但是那不是SVM原本自身产生的,而是在SVM基础上建立了一个别的模型,当其要输出概率的时候,还是转化为LR】
SVM甚至是SVR本质上都不是概率模型,因为其基于的假设就不是关于概率的
SVM依赖于数据的测度,而LR则不受影响
因为SVM是基于距离的,而LR是基于概率的,所以LR是不受数据不同维度测度不同的影响,而SVM因为要最小化
当然如果LR要加上正则化时,也是需要normalization一下的
另外【如果用梯度下降算法,则一般都需要 feature scaling】
原因如下:
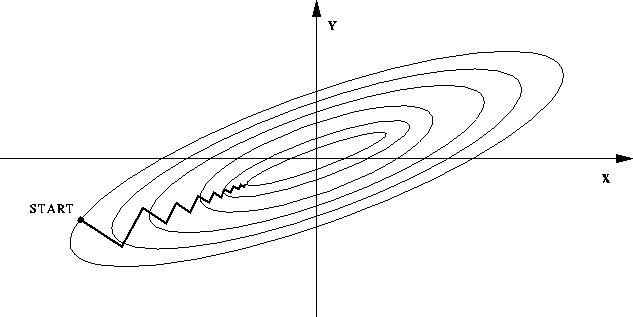
如果不归一化,各维特征的跨度差距很大,目标函数就会是“扁”的,在进行梯度下降的时候,梯度的方向就会偏离最小值的方向,走很多弯路。
SVM自带结构风险最小化,LR则是经验风险最小化
因为SVM本身就是优化
而LR不加正则化的时候,其优化的目标是经验风险最小化,所以最后需要加入正则化,增强模型的泛化能力。
SVM会用核函数而LR一般不用核函数的原因
SVM转化为对偶问题后,分类只需要计算与少数几个支持向量的距离,这个在进行复杂核函数计算时优势很明显,能够大大简化模型和计算量。
而LR则每个点都需要两两计算核函数,计算量太过庞大。
LR和SVM在实际应用的区别
根据经验来看,对于小规模数据集,SVM的效果要好于LR,但是大数据中,SVM的计算复杂度受到限制,而LR因为训练简单,可以在线训练,所以经常会被大量采用【听今日头条的同学说,他们用LR用的就非常的多】