目录
- Abstract
- 1. Introduction
- 2. Related works
- 3. Quality fluctuation of compressed video
- 4. The proposed MF-CNN approach
- 5. Experiments
论文链接:arXiv
Beihang Multimedia Computing Towards Communications (MC2) Lab
作者:杨韧大师兄和徐迈恩师
这篇文章首次提出:在视频解码后利用多帧图像进行质量增强。
该工作在ECCV及其后得到了华为、谷歌等的关注和合作意向。
Abstract
The past few years have witnessed great success in applying deep learning to enhance the quality of compressed image/video. The existing approaches mainly focus on enhancing the quality of a single frame, ignoring the similarity between consecutive frames.
近年来有许多工作,都用深度学习的方法增强压缩视频或图像的质量。
但是,这些工作都关注单帧图像的增强,而忽略了连续帧的相关性。
In this paper, we investigate that heavy quality fluctuation exists across compressed video frames, and thus low quality frames can be enhanced using the neighboring high quality frames, seen as Multi-Frame Quality Enhancement (MFQE). Accordingly, this paper proposes an MFQE approach for compressed video, as a first attempt in this direction.
在这篇文章中,我们调查了压缩视频帧中存在的严重的质量波动现象,由此认为:低质量帧可以被邻近的高质量帧增强。
这种方法被称为Multi-Frame Quality Enhancement (MFQE)。
在这个方向(视频质量增强)上,我们是第一个提出该方法的。
In our approach, we firstly develop a Support Vector Machine (SVM) based detector to locate Peak Quality Frames (PQFs) in compressed video. Then, a novel Multi-Frame Convolutional Neural Network (MF-CNN) is designed to enhance the quality of compressed video, in which the non-PQF and its nearest two PQFs are as the input.
在我们的方法中:
- 用一个SVM,找出多帧中的Peak Quality Frames (PQFs);
- 再用一个Multi-Frame Convolutional Neural Network (MF-CNN),输入一个non-PQF及其相邻两个PQF帧,增强该帧的质量。
The MF-CNN compensates motion between the non-PQF and PQFs through the Motion Compensation subnet (MC-subnet). Subsequently, the Quality Enhancement subnet (QE-subnet) reduces compression artifacts of the non-PQF with the help of its nearest PQFs.
该MF-CNN网络中有两个子网络:
- Motion Compensation subnet (MC-subnet):运动补偿non-PQF;
- Quality Enhancement subnet (QE-subnet):减少non-PQF的compression artifacts。
The code of our MFQE approach is available at https://github.com/ryangBUAA/MFQE.git.
1. Introduction
网络带宽是受限的,数据量是爆炸性增长的,因此视频压缩是必要的。
然而,压缩视频不可避免地会引入compression artifacts,用户体验降低。
因此,压缩视频增强是有必要的。
其他人是如何解决这一问题的呢?
For example, Dong designed a four-layer Convolutional Neural Network (CNN), named AR-CNN, which considerably improves the quality of JPEG images. Later, Yang designed a Decoder-side Scalable CNN (DS-CNN) for video quality enhancement.
However, when processing a single frame, all existing quality enhancement approaches do not take any advantage of information in the neighbouring frames, and thus their performance is largely limited.
As Figure 1 shows, the quality of compressed video dramatically fluctuates across frames. Therefore, it is possible to use the high quality frames (i.e., Peak Quality Frames, called PQFs) to enhance the quality of their neighboring low quality frames (non-PQFs). This can be seen as Multi-Frame Quality Enhancement (MFQE), similar to multi-frame super-resolution.

这个特性太重要了,说明了为什么我们可以这么做。
之后的方法介绍与Abstract大致相同,更详细的是:
The QE-subnet, with a spatio-temporal architecture, is designed to extract and merge the features of the current non-PQF and the compensated PQFs.
Finally, the quality of the current non-PQF can be enhanced by QE-subnet that takes advantage of the high quality content in the adjacent PQFs. For example, as shown in Figure 1, the current non-PQF (frame 96) and the nearest PQFs (frames 93 and 97) are fed in to the MF-CNN of our MFQE approach. As a result, the low quality content (basketball) of the non-PQF (frame 96) can be enhanced upon the same content but with high quality in the neighboring PQFs (frames 93 and 97).
如图1所示,96帧被其最邻近的PQF:93和97帧增强。
Moreover, Figure 1 shows that our MFQE approach also mitigates the quality fluctuation, because of the considerable quality improvement of non-PQFs.
图1还说明,MFQE还能减少质量波动。
2. Related works
Quality enhancement
相关工作非常多。略。
All above approaches can be seen as single-frame quality enhancement approaches, as they do not use any advantageous information available in the neighboring frames. Consequently, the video quality enhancement performance is severely limited.
共同问题是:没有利用帧间相关性。
Multi-frame super-resolution
To our best knowledge, there exists no MFQE work for compressed video.
The closest area is multi-frame video super-resolution.
据我们所知,压缩视频领域的MFQE是我们的首创。
除此之外,MFQE在超分辨领域所有应用,非常相似。
批:所以,讲好故事很重要啊!!换一个场景就是一篇CVPR!
Brandi and Song proposed to enlarge video resolution by taking advantage of high resolution key-frames.
深度学习也逐渐应用起来:
For example, Huang developed a Bidirectional Recurrent Convolutional Network (BRCN), which improves the super-resolution performance over traditional single-frame approaches.
In 2016, Kappeler proposed a Video Super-Resolution network (VSRnet), in which the neighboring frames are warped according to the estimated motion, and both the current and warped neighboring frames are fed into a super-resolution CNN to enlarge the resolution of the current frame.
这一点很关键:先根据estimated motion,把相邻帧warp,再和当前帧一起训练CNN。
Later, Li proposed replacing VSRnet by a deeper network with residual learning strategy.
关于深度残差网络,参见:CSDN博客
The aforementioned multi-frame super-resolution approaches are motivated by the fact that different observations of the same objects or scenes are probably available across frames of a video. As a result, the neighboring frames may contain the content missed when down-sampling the current frame.
这些多帧超分辨方法,都是受同一事实的启发:同一个物体或场景,在一个视频的多帧中有多种表现形式。
因此,相邻帧可以提供当前帧由于降采样丢失掉的信息。
Similarly, for compressed video, the low quality frames can be enhanced by taking advantage of their adjacent higher quality frames, because heavy quality fluctuation exists across compressed frames. Consequently, the quality of compressed video may be effectively improved by leveraging the multi-frame information.
3. Quality fluctuation of compressed video
First, we establish a database including 70 uncompressed video sequences, selected from the datasets of Xiph.org and JCT-VC.
选出视频,构建数据库。
We compress these sequences using various video coding standards, including MPEG-1, MPEG-2, MPEG-4, H.264/AVC and HEVC.
用多种标准压缩,包括MPEG-1,MPEG-2,MPEG-4,AVC和HEVC等。
The quality of each compressed frame is evaluated in terms of Peak Signal-to-Noise Ratio (PSNR).
质量指标采用PSNR。
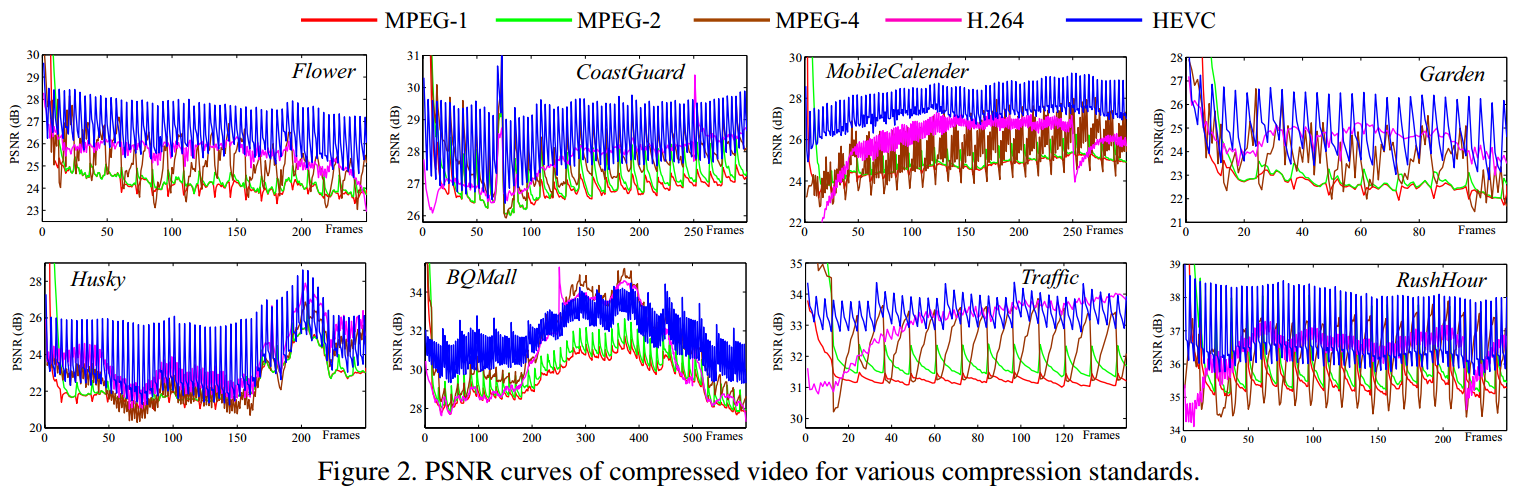
图2展示的是8个由不同标准压缩的视频序列,可以看出:8个视频的质量都随帧波动。
We further measure the STandard Deviation (STD) of frame-level quality for each compressed video.
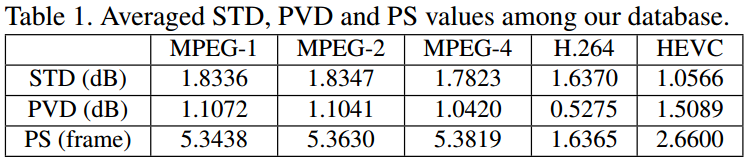
As shown in Table 1, the STD values of all five standards are above 1.00 dB, which are averaged over the 70 compressed sequences.
The maximal STD among the 70 sequences reaches 3.97 dB, 4.00 dB, 3.84 dB, 5.67 dB and 3.34 dB for MPEG-1, MPEG-2, MPEG-4, H.264 and HEVC, respectively.
This reflects the remarkable fluctuation of frame-level quality after video compression.
我们举一个HEVC压缩的例子:
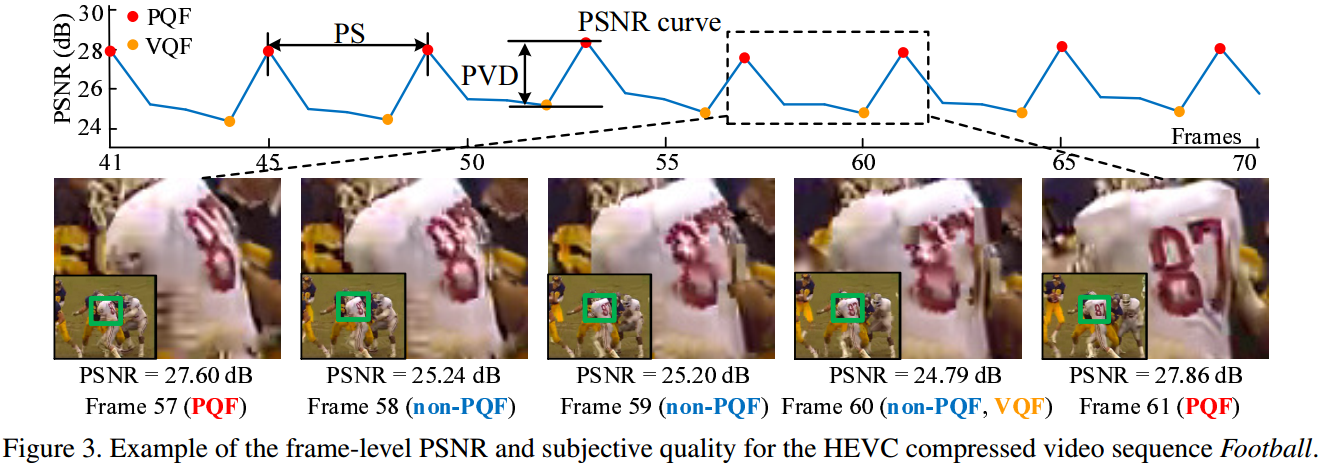
It can be observed from Figure 3 that there exists frequently alternate PQFs and Valley Quality Frames (VQFs).
Here, PQF is defined as the frame whose quality is higher than its previous and subsequent frames.
In contrast, VQF indicates the frame with lower quality than its previous and subsequent frames.
给出了PQF和VQF的定义。
As shown in this figure, the PSNR of non-PQFs (frames 58-60), especially the VQF (frame 60), is obviously lower than that of the nearest PQFs (frames 57 and 61). Moreover, non-PQFs (frames 58-60) also have much lower subjective quality than the nearest PQFs (frames 57 and 61), e.g., in the region of number "87". Additionally, the content of frames 57-61 is very similar.
该图非常明显。
To further analyze the peaks and valleys of frame-level quality, we measure the Peak-Valley Difference (PVD) and Peak Separation (PS) for the PSNR curves of each compressed video sequence.
As seen in Figure 3-(a), PVD is denoted as the PSNR difference between the PQF and its nearest VQF, and PS indicates the number of frames between two PQFs.
定义比较简单,PVD是峰谷差,PS是峰峰距。但这两个指标的贡献非常大,见下。
The averaged PVD and PS values of the 70 compressed video sequences are shown in Table 1 for each video coding standard.
It can be seen that the averaged PVD values are higher than 1.00 dB in most cases, and the latest HEVC standard has the highest value of 1.50 dB. This verifies the large quality difference between PQFs and VQFs.
PVD值几乎都大于1dB,在HEVC中达到了1.5dB。补偿的空间很大。
Additionally, the PS values are approximately or less than 5 frames for each coding standard. In particular, the PS values are less than 3 frames for the H.264 and HEVC standards. Such a short distance between two PQFs indicates that the content of frames between the adjacent PQFs may be highly similar.
Therefore, the PQFs probably contain some useful content which is distorted in their neighboring non-PQFs.
PS值几乎都小于5,在HEVC和H.264中都小于3。相邻帧相关性确实很强。
Motivated by this, our MFQE approach is proposed to enhance the quality of non-PQFs through the advantageous information of the nearest PQFs.
这进一步预示了我们方法的可行性。
4. The proposed MF-CNN approach
Framework
Figure 4 shows the framework of our MFQE approach.
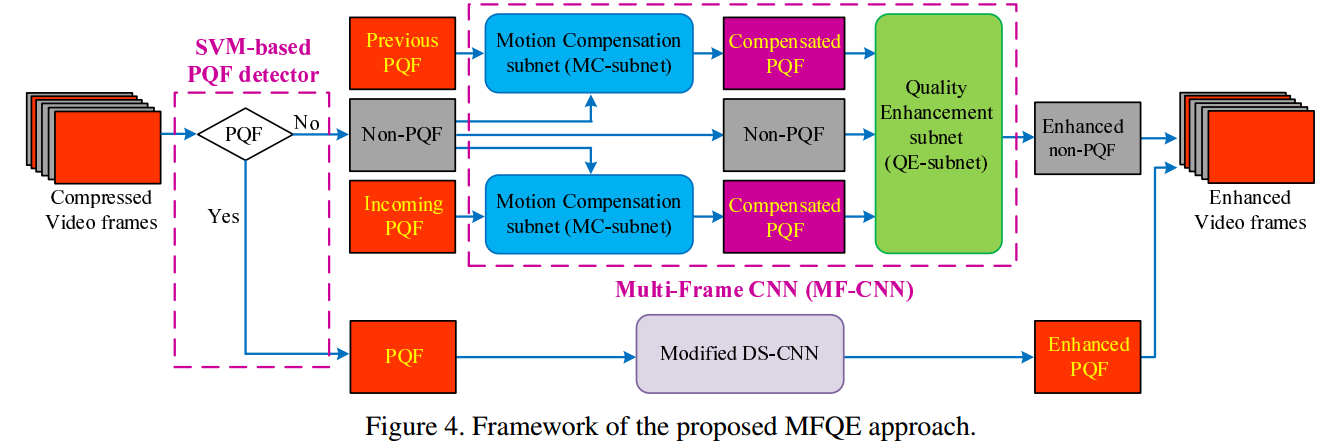
In the MFQE approach, we first detect the PQFs that are used for quality enhancement of other non-PQFs.
In practical application, the raw sequences are not available in video quality enhancement, and thus the PQFs and non-PQFs cannot be distinguished through comparison with the raw sequences.
Therefore, we develop a no-reference PQF detector in our MFQE approach, which is detailed in Section: peakdetec.
我们首先检测PQF。在实际应用中,我们无法得到raw sequences,也就不能通过比较raw sequences和已有sequences,(计算PSNR损失)来找出PQF(批:本文对PQF定义也不是这样的)。
因此,我们的PQF检测器是no-reference的,具体在peakdetec一节中介绍。
The quality of detected PQFs can be enhanced by DS-CNN, which is a single-frame approach for video quality enhancement.
It is because the adjacent frames of a PQF are with lower quality and cannot benefit the quality enhancement of this PQF.
Here, we modify the DS-CNN via replacing the Rectified Linear Units (ReLU) by Parametric ReLU (PReLU) to avoid zero gradients, and we also apply residual learning to improve the quality enhancement performance.
对于PQF,我们用DS-CNN进行单帧质量增强。我们显然不能用多帧质量增强,因为别的帧更差。
不同于DS-CNN的地方是,我们采用PReLU而不是ReLU来避免0梯度,同时采用残差学习的方法提高性能。
For non-PQFs, the MF-CNN is proposed to enhance the quality that takes advantage of the nearest PQFs (i.e., both previous and subsequent PQFs).
The MF-CNN architecture is composed of the MC-subnet and the QE-subnet.
The MC-subnet is developed to compensate the temporal motion across the neighboring frames.
To be specific, the MC-subnet firstly predicts the temporal motion between the current non-PQF and its nearest PQFs. Then, the two nearest PQFs are warped with the spatial transformer according to the estimated motion. As such, the temporal motion between the non-PQF and PQFs can be compensated. The MC-subnet is to be introduced in Section: mc.
Finally, the QE-subnet, which has a spatio-temporal architecture, is proposed for quality enhancement, as introduced in Section: cnn.
In the QE-subnet, both the current non-PQF and the compensated PQFs are as the inputs, and then the quality of the current non-PQF can be enhanced under the help of the adjacent compensated PQFs.
Note that, in the proposed MF-CNN, the MC-subnet and QE-subnet are trained jointly in an end-to-end manner.
对于non-PQF,我们用MF-CNN予以增强。MF-CNN由MC-subnet和QE-subnet组成,前者用于补偿短暂的时移(尽量抵消),后者用于提高non-PQF的质量。
注意,两个网络是同时训练的端到端网络。
SVM-based PQF detector
In our approach, the PQF detector follows the no-reference quality assessment method to extract 36 spatial features from the current frame, each of which is one-dimensional.
Beyond, such kinds of spatial features are also extracted from two previous frames and two incoming frames. Consequently, 180 one-dimensional features are obtained to predict whether a frame is a PQF or non-PQF, based on the SVM classifier.
PQF检测器采用no-reference quality assessment method,在当前帧内提取36个一维的空间特征。
前2帧、后2帧同理,一共由\(5*36=180\)个特征。
再利用SVM分类器,即可判决PQF。
In our SVM classifier, \(l_n \in \{0, 1\}\) denotes the output class label indicating whether the \(n\)-th frame is a PQF (positive sample with \(l_n=1\)) or non-PQF (negative sample with \(l_n=0\)).
We use the LIBSVM library to train the SVM classifier, in which the probability of \(l_n=1\) can be obtained for each frame and denoted as \(p_n\).
In our SVM classifier, the Radial Basis Function (RBF) is used as the kernel.
Finally, \(\{l_n,p_n\}_{n=1}^N\) can be obtained from the SVM classifier, in which \(N\) is the total number of frames in the video sequence.
SVM处理二分类问题:正类为PQF,负类为non-PQF。
我们使用LIBSVM library来训练SVM。kernel是RBF。
其输出\(p_n\)代表:当前帧是正类的概率。
In our PQF detector, we further refine the results of the SVM classifier according to the prior knowledge of PQF.
Specifically, the following two strategies are developed to refine the labels \(\{l_n\}_{n=1}^N\) of the PQF detector.
我们采用下面2个策略(先验知识),来进一步改进我们的判决:
(1) According to the definition of PQF, it is impossible that the PQFs consecutively appear.
Hence, if the following case exists
\[ \{l_{n+i}\}_{i=0}^j = 1\ \ \ \text{and}\ \ \ l_{n-1}=l_{n+j+1}=0,\ j\geq1, \]
we set
\[ l_{n+i} = 0, \text{where}\ \ i \not= \mathop{\arg \max}_{0\leq k\leq j}(p_{n+k}) \]
in our PQF detector.
考虑到PQF不能连续出现,如果\(l_n\)到\(l_{n+j}\)都是1,边上是0,那么选出其中概率最大的为1,其余都设为0。
(2) According to the analysis of Section 3, PQFs frequently appear within a limited separation.
For example, the average value of PS is 2.66 frames for HEVC compressed sequences.
Here, we assume that \(D\) is the maximal separation between two PQFs.
Given this assumption, if the results of \(\{l_n\}_{n=1}^N\) yields more than \(D\) consecutive zeros (non-PQFs):
\[ \{l_{n+i}\}_{i=0}^d = 0\ \ \ \text{and}\ \ \ l_{n-1}=l_{n+d+1}=1,\ d > D, \]
one of frames need to be selected as PQF, and thus we set
\[ l_{n+i} = 1, \text{where}\ \ i = \mathop{\arg\max}_{0 < k < d}(p_{n+k}). \]
After refining \(\{l_n\}_{n=1}^N\) as discussed above, our PQF detector can locate PQFs and non-PQFs in the compressed video.
如果non-PQF连续出现次数大于D,那么我们也选出最大值设为1,其余仍为0,打破non-PQF的连续性。
批:由于是一个二分类问题,因此采用SVM是一个合理的做法。
MC-subnet
Architecture
Caballero proposed the Spatial Transformer Motion Compensation (STMC) method for multi-frame super-resolution.
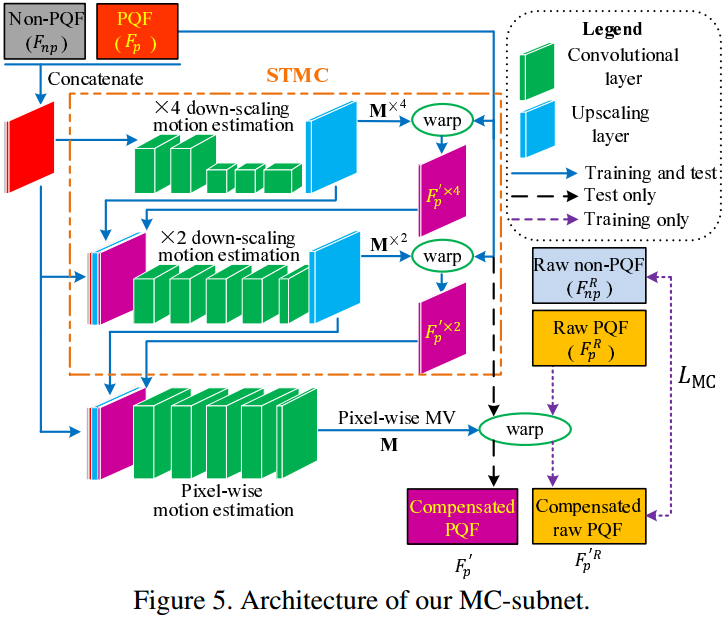
As shown in Figure 5, the STMC method adopts the convolutional layers to estimate the \(\times4\) and \(\times2\) down-scaling Motion Vector (MV) maps, denoted as \(\mathbf{M}^{\times4}\) and \(\mathbf{M}^{\times2}\).
In \(\mathbf{M}^{\times4}\) and \(\mathbf{M}^{\times2}\), the down-scaling is achieved by adopting some convolutional layers with the stride of 2.
该运动补偿网络采用的是Caballero等的工作:Spatial Transformer Motion Compensation (STMC),最初用于多帧超分辨。
The down-scaling motion estimation is effective to handle large scale motion.
However, because of down-scaling, the accuracy of MV estimation is reduced.
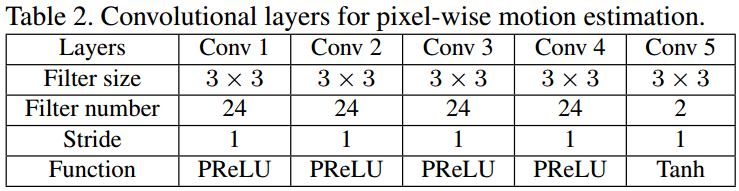
Therefore, in addition to STMC, we further develop some additional convolutional layers for pixel-wise motion estimation in our MC-subnet, which does not contain any down-scaling process.
The convolutional layers of pixel-wise motion estimation are described in Table 2.
在该网络的基础上,我们做了一些改进。
原网络采用了降采样,尽管对large scale motion非常有利,但牺牲了预测精度。
为此,我们的MC-subnet增加了图5中最下面的那个5层卷积网络,无降采样过程。
5层卷积网络参数见表格5。
As Figure 5 shows, the output of STMC includes the \(\times2\) down-scaling MV map \(\mathbf{M}^{\times2}\) and the corresponding compensated PQF \(F'^{\times2}_{p}\).
如图,STMC的最终输出,是2倍降采样的MV:\(\mathbf{M}^{\times2}\),和其补偿后的PQF:\(F'^{\times2}_{p}\)。
They are concatenated with the original PQF and non-PQF, as the input to the convolutional layers of the pixel-wise motion estimation.
Then, the pixel-wise MV map can be generated, which is denoted as \(\mathbf{M}\).
该MV和补偿后的PQF,与原PQF和non-PQF一起,输入运动补偿网络。
最终输出的就是最终版MV:\(\mathbf{M}\)。
Note that the MV map \(\mathbf{M}\) contains two channels, i.e., horizonal MV map \(\mathbf{M}_x\) and vertical MV map \(\mathbf{M}_y\). Here, \(x\) and \(y\) are the horizonal and vertical index of each pixel. Given \(\mathbf{M}_x\) and \(\mathbf{M}_y\), the PQF is warped to compensate the temporal motion. Let the compressed PQF and non-PQF be \(F_p\) and \(F_{np}\), respectively. The compensated PQF \(F'_p\) can be expressed as
\[ F'_p(x,y) = \mathcal{I}\{F_{p}(x+\mathbf{M}_x(x,y),y+\mathbf{M}_y(x,y))\}, \]
where \(\mathcal{I}\{\cdot\}\) means the bilinear interpolation. The reason for the interpolation is that \(\mathbf{M}_x(x,y)\) and \(\mathbf{M}_y(x,y)\) may be non-integer values.
具体补偿方式是,\(\mathbf{M}\)中的两个分量:\(\mathbf{M}_x\)和\(\mathbf{M}_y\)分别补偿两个方向的运动。看公式。
Training strategy
批:上面是MC-subnet及其补偿原理,那么该网络又如何训练呢?
Since it is hard to obtain the ground truth of MV, the parameters of the convolutional layers for motion estimation cannot be trained directly.
首先,我们不能用真实的MV来训练网络,因为真实的MV很难获取。MV获取本身就是一个研究课题。
批:那么Caballero等人又是如何训练的呢?
The super-resolution work trains the parameters by minimizing the MSE between the compensated adjacent frame and the current frame.
在他们的工作中,loss是当前帧与补偿帧之间的MSE。因为:
\[ 邻近帧 + 真实MV(不可知) = 当前帧;\\ 邻近帧 + subnet输出MV = 预测帧;\\ MSE(当前帧,预测帧)=MSE(真实MV, subnet输出MV) \]
However, in our MC-subnet, both the input \(F_p\) and \(F_{np}\) are compressed frames with quality distortion.
Hence, when minimizing the MSE between \(F'_p\) and the \(F_{np}\), the MC-subnet learns to estimate the distorted MV, resulting in inaccurate motion estimation.
然而,我们处理的是压缩帧,质量都是受损的(哪怕是PQF)。
如果直接拿当前帧\(F_{np}\)和补偿帧\(F'_p\)进行训练,习得MV也将是变形的。
Therefore, the MC-subnet is trained under the supervision of the raw frames.
That is, we warp the raw frame of the PQF (denoted as \(F^R_p\)) using the MV map output from the convolutional layers of motion estimation, and minimize the MSE between the compensated raw PQF (denoted as \(F'^{R}_{p}\)) and the raw non-PQF (denoted as \(F^R_{np}\)).
The loss function of the MC-subnet can be written by
\[ L_{\text{MC}}(\theta_{mc})=||F'^{R}_p(\theta_{mc}) - F^R_{np}||_2^2, \]
where \(\theta_{mc}\) represents the trainable parameters of our MC-subnet.
为此,我们把MV用于补偿raw PQF而不是原PQF,得到\(F'^{R}_{p}\);和raw non-PQF:\(F^R_{np}\)一起训练。
Note that the raw frames \(F^R_p\) and \(F^{R}_{np}\) are not required when compensating motion in the test.
显然,raw数据只能用于训练,测试时不可以使用,因为实际应用时也没有raw数据,只有降质的数据。
QE-subnet
Given the compensated PQFs, the quality of non-PQFs can be enhanced through the QE-subnet, which is designed with spatio-temporal architecture.
现在,我们有了被补偿的PQF,可以用来增强non-PQF,借助spatio-temporal结构网络:QE-subnet。
Specifically, together with the current processed non-PQF \(F_{np}\), the compensated previous and subsequent PQFs (denoted by \(F'_{p1}\) and \(F'_{p2}\)) are input to the QE-subnet. This way, both the spatial and temporal features of these three frames are explored and merged.
具体怎么时空结合呢?我们对网络输入:
- 当前non-PQF帧:\(F_{np}\)
- 前一个PQF向后的补偿帧:\(F'_{p1}\)
- 后一个PQF向前的补偿帧:\(F'_{p2}\)
Consequently, the advantageous information in the adjacent PQFs can be used to enhance the quality of the non-PQF. It differs from the CNN-based image/single-frame quality enhancement approaches, which only handle the spatial information within one frame.
Architecture
The architecture of the QE-subnet is shown in Figure 6, and the details of the convolutional layers are presented in Table 3.
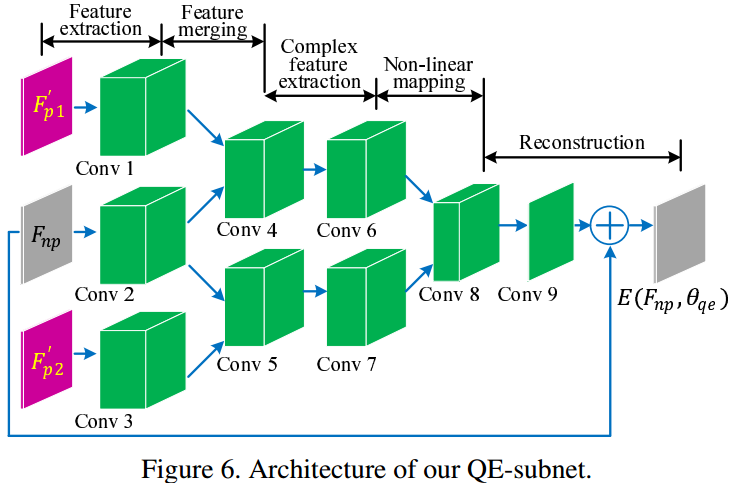
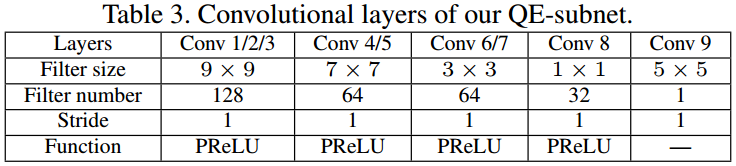
In the QE-subnet, the convolutional layers Conv 1, 2 and 3 are applied to extract the spatial features of input frames \(F'_{p1}\), \(F_{np}\) and \(F'_{p2}\), respectively.
Then, in order to use the high quality information of \(F'_{p1}\), Conv 4 is adopted to merge the features of \(F_{np}\) and \(F'_{p1}\).
That is, the outputs of Conv 1 and 2 are concatenated and then convolved by Conv 4.
Similarly, Conv 5 is used to merge the features of \(F_{np}\) and \(F'_{p2}\).
Conv 6/7 is designed to extract more complex features from Conv 4/5.
Consequently, the extracted features of Conv 6 and Conv 7 are non-linearly mapped to another space through Conv 8.
Finally, the reconstructed residual, denoted as \(R_{np}(\theta_{qe})\), is achieved in Conv 9, and the non-PQF is enhanced by adding \(R_{np}(\theta_{qe})\) to the input non-PQF \(F_{np}\). Here, \(\theta_{qe}\) is defined as the trainable parameters of QE-subnet.
Training strategy
The MC-subnet and QE-subnet of our MF-CNN are trained jointly in an end-to-end manner.
Assume that \(F'^R_{p1}\) and \(F'^R_{p2}\) are defined as the raw frames of the previous and incoming PQFs, respectively.
The loss function of our MF-CNN can be formulated as
\[ L_{\text{MF}}(\theta_{mc},\theta_{qe}) = a\cdot\underbrace{\sum_{i=1}^2||F'^R_{pi}(\theta_{mc})-F^R_{np}||_2^2}_{L_{\text{MC}}:\ \text{loss of MC-subnet}} \nonumber \\ + b\cdot\underbrace{\big|\big|\big(F_{np}+R_{np}(\theta_{qe})\big)-F^{R}_{np}\big|\big|_2^2}_{L_{\text{QE}}:\ \text{loss of QE-subnet}}. \]
The loss function of the MF-CNN is the weighted sum of \(L_{\text{MC}}\) and \(L_{\text{QE}}\), which are the loss functions of MC-subnet and QE-subnet, respectively.
注意,两个网络是同时训练的,loss也是二者loss的加权组合。
QE-subnet的loss不难理解:当前帧(有损)加上训练输出的residual,与raw non-PQF的误差。
Because \(F'_{p1}\) and \(F'_{p2}\) generated by the MC-subnet are the basis of the following QE-subnet, we set \(a \gg b\) at the beginning of training.
技术细节:由于MC-subnet需要输出\(F'_{p1}\)和\(F'_{p2}\)作为QE-subnet的输入,因此前一个网络的误差会很大程度上影响后一个网络。
因此在训练初始,前者loss的惩罚要远大于后者loss。
After the convergence of \(L_{\text{MC}}\) is observed, we set \(a\ll b\) to minimize the MSE between \(F_{np}+R_{np}\) and \(F^R_{np}\).
在前者loss基本收敛后,我们再让后者权重远大于前者。
5. Experiments
Settings
70个视频被随机分为60个和10个,前者用于训练,后者用于测试。
视频压缩遵循最新的HEVC标准,Quantization Parameter (QP)设为37和42。
D设为6。(这是实验的最大值)
其他参数:
When training the MF-CNN, the raw and compressed sequences are segmented into \(64\times64\) patches as the training samples.
The batch size is set to 64. We adopt the Adam algorithm with initial learning rate as \(10^{-4}\) to minimize the loss function of lossmf.
In the training stage, we initially set \(a = 1\) and \(b = 0.01\) of lossmf to train the MC-subnet.
After the MC-subnet converges, these hyperparameters are set as \(a = 0.01\) and \(b = 1\) to train the QE-subnet.
Performance of the PQF detector

结果较理想,PQF检测器有效。
Performance of our MFQE approach
Our performance is compared with AR-CNN, DnCNN, Li, DCAD and DS-CNN.
Note that AR-CNN, DnCNN and Li are re-trained on HEVC compressed samples for fair comparison.
Among them, AR-CNN, DnCNN and Li are the latest quality enhancement approaches for compressed image.
DCAD and DS-CNN are the state-of-the-art video quality enhancement approaches.
批:说清楚为什么选择它们。
Quality enhancement on non-PQFs
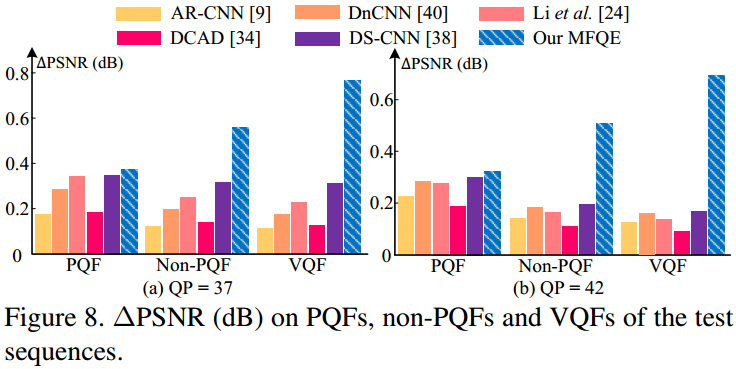
Overall quality enhancement
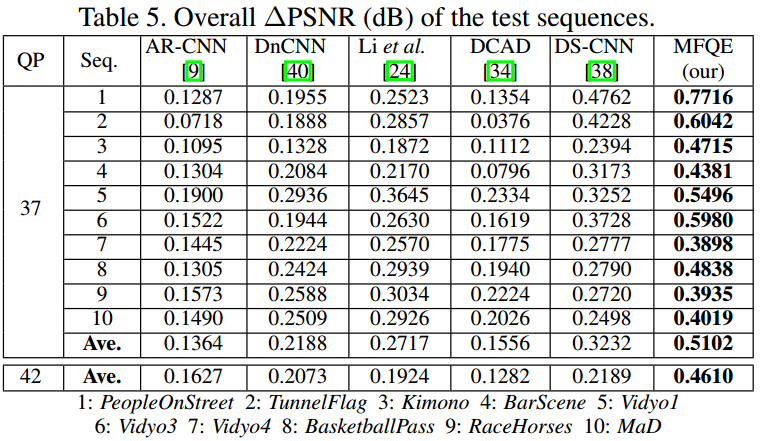
Quality fluctuation
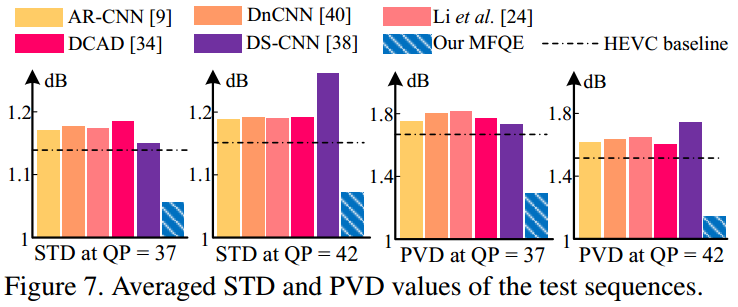
使STD和PVD有所下降。
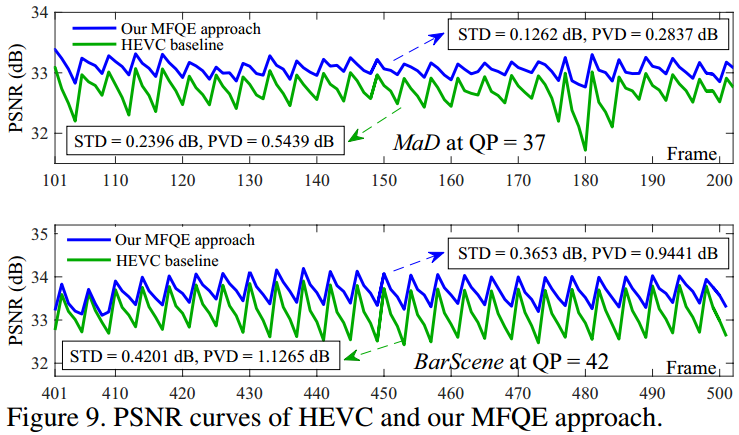
波动减小。
Subjective quality performance

Effectiveness of utilizing PQFs
如果不考虑PQF,只用相邻帧,那么增益只有0.3+dB。
如果考虑PQF,那么增益达到0.4+~0.5+dB。
Transfer to H.264 standard
刚刚只测了HEVC,现在迁移过来测试,设QP=37,增益可达0.4540dB。