1.选择排序
题目分析:
选择排序就是每一次从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始位置,直到全部待排序的数据元素排完。
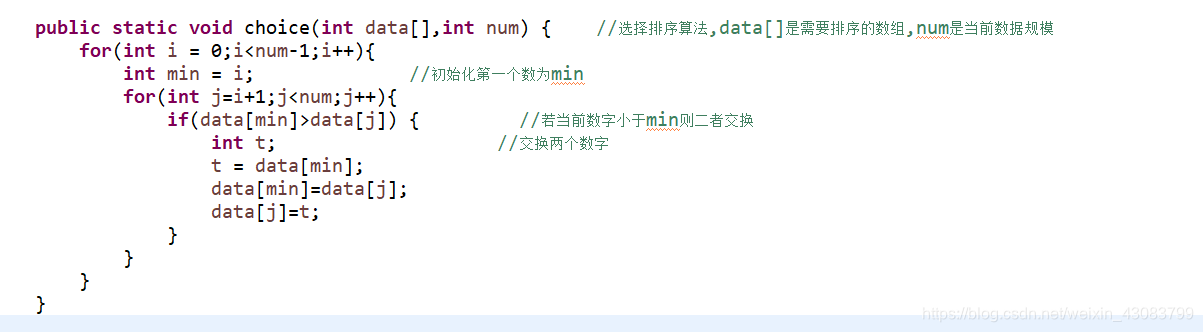
采用两重for循环依次遍历数组,每次选出数组中最小的一个。
算法实现:
运行结果:
算法复杂度分析及经验归纳:
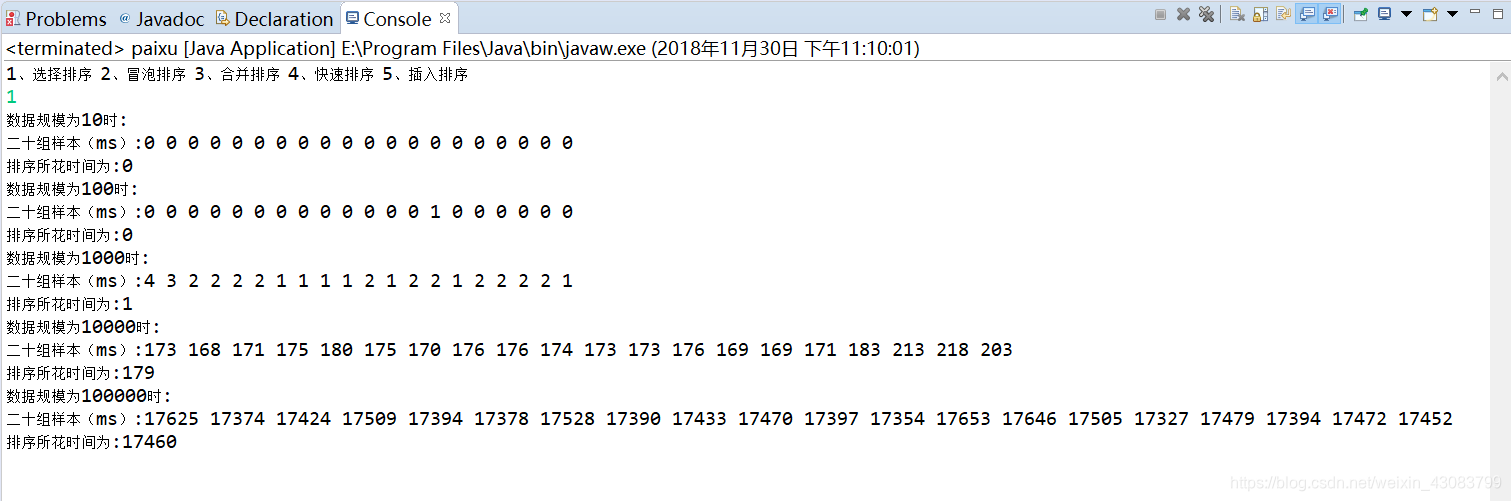
数据规模 10 100 1000 10000 100000
花费时间 0 0 1 179 17460
数据规模在10~1000之间是,数据规模过小,花费时间不好统计几乎为0,当数据规模变化到100000时,花费时间增长很快。
2.冒泡排序
题目分析:
冒泡排序就是重复地走访过要排序的元素列,依次比较两个相邻的元素,如果他们的顺序是由小到大就交换二者,直到所有数排好序。
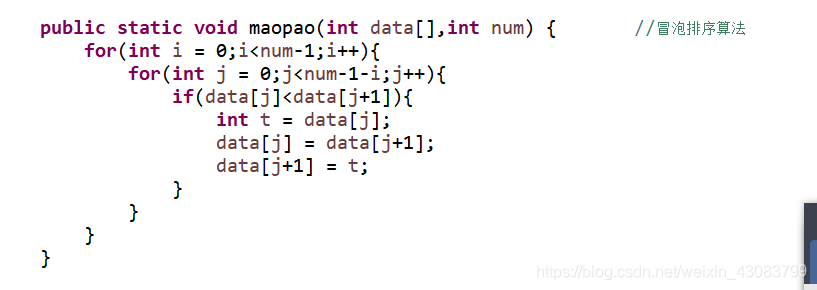
采用两重for循环依次重复遍历数组,每次对比相邻的两个数,若顺序不对则交换两个数。
算法实现:
运行结果:
算法复杂度分析及经验归纳:
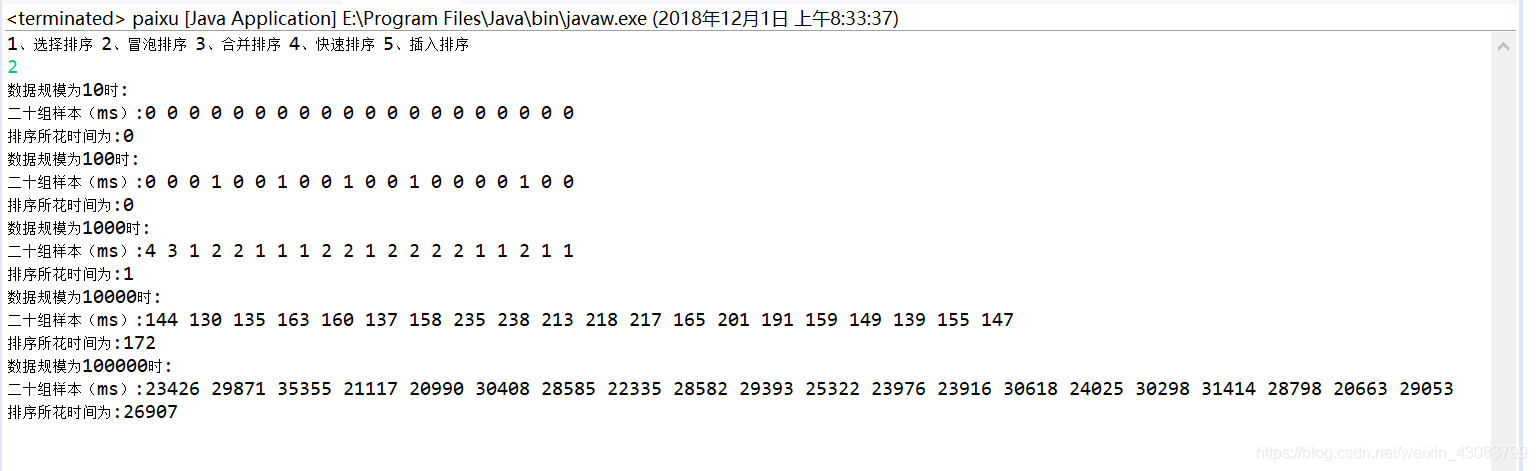
数据规模 10 100 1000 10000 100000
花费时间 0 0 1 172 26907
数据规模在10~1000之间是,数据规模过小,花费时间不好统计几乎为0,当数据规模变化到100000时,花费时间增长很快,与选择排序结果类似,但数据规模为100000时,所花时间比选择排序要高
3.合并排序
题目分析:
合并排序就是将两个(或两个以上)有序表合并成一个新的有序表,即把待排序序列分为若干个子序列,每个子序列是有序的。然后再把有序子序列合并为整体有序序列。
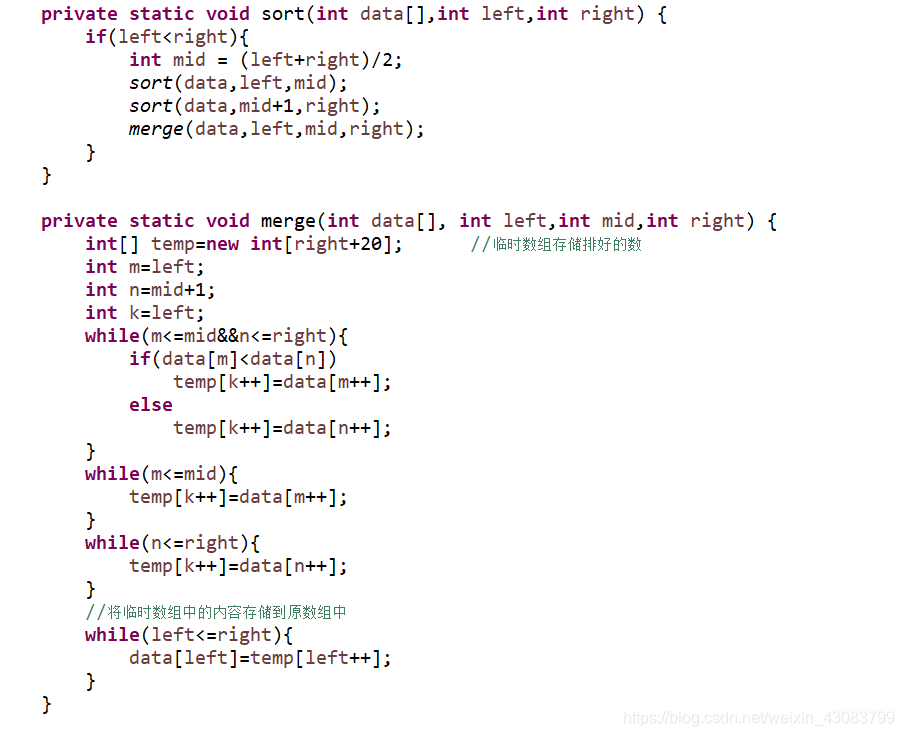
采用两个函数完成算法,第一个sort函数递归调用,第二个函数将每个子序列排好序。
算法实现:
运行结果:

算法复杂度及经验归纳:
数据规模 10 100 1000 10000 100000
花费时间 0 0 1 31 2821
数据变化情况与前两种排序算法类似,但数据规模为10000时,所花时间远小于前两种算法,数据规模为100000时,所花时间也远小于前两种算法。
4.快速排序
题目分析:
快速排序就是通过一轮的排序将序列分割成独立的两部分,其中一部分序列的关键字(这里主要用值来表示)均比另一部分关键字小。继续对长度较短的序列进行同样的分割,最后到达整体有序。
从数列中设置一个基准,之后遍历数组,将比基准小的数放到基准左边,将比基准大的数放到基准右边,之后不断调用自身,完成排序。
算法实现:

运行结果:

算法复杂度及经验归纳:
数据规模 10 100 1000 10000 100000
花费时间 0 0 0 1 13
数据变化规律与前几种算法不同,数据整体变化不像前几种算法数据规模为100000时大幅度变化。
5.插入排序
题目分析:
插入排序就是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。
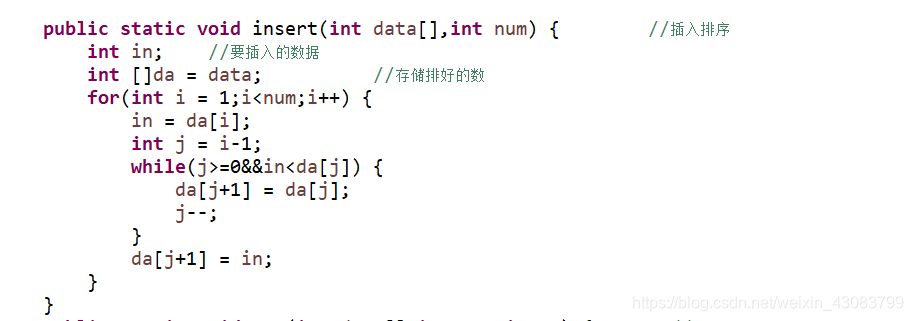
采用for和while循环,从数组中的第二个数开始找到相应的位置放入进行排序。
算法实现:
运行结果:

算法复杂度及经验归纳:
数据规模 10 100 1000 10000 100000
花费时间 0 0 0 28 1653
数据变化趋势与前三种算法类似,但当数据规模为100000时,所花时间远小于前三种算法。
6.数据规模设计:
采用不同的数组存储不同数据规模的数据:
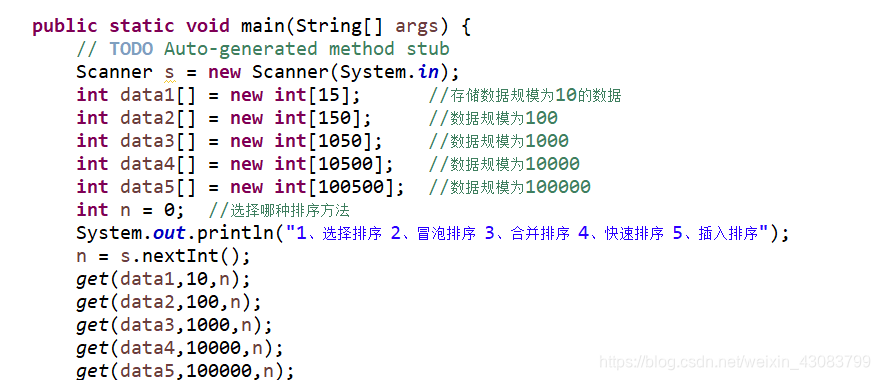
每种数据规模产生二十组随机数样本数据进行排序算法测试:

8.综合分析:

由图表可知,这五种排序算法的效率:
快速排序>插入排序>合并排序>选择排序>冒泡排序(不排除因为电脑问题出现误差)