ElasticSearch(上)
一,什么是ElasticSearch?
ElasticSearch是一个基于Lucene的实时分布式的全文检索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便,基于RESTful接口。

Lucene相关–>博客地址:https://blog.csdn.net/weixin_43270493/article/category/8558685
二,Lucene和ES关系
1.Lucene只是一个库。想要使用它,你必须使用Java来作为开发语言并将其直接集成到你的应用中。更麻烦的是。Lucene非常复杂,你需要深入检索的相关知识来理解它是如何运行工作的。
2.ElasticSearch也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文检索变得简单。
三,ElasticSearch和Solr
3.1 性能对比
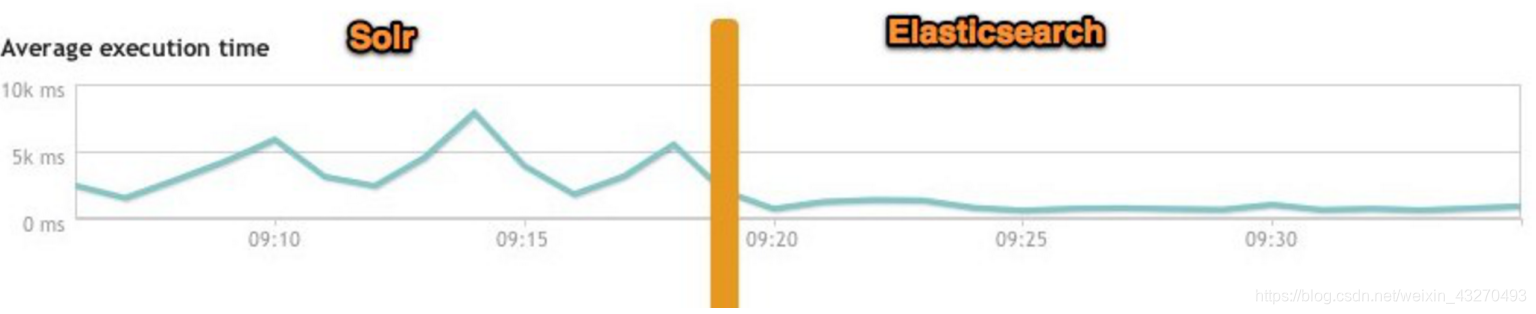
大型互联网公司,实际生产环境测试,将搜索引擎从Solr转到Elasticsearch以后的平均查询速度有了50倍的提升。

3.2 优势
1.ES是分布式的,不需要其他组件,分发是实时的,被叫做“Push replication"
2.ES完全支持 Apache Lucene的接近实时的搜索,处理多租户(Multitenancy)不需要特殊配置,而Solr则需要更多的高级设置。
3.ES采用GateWay的概念,使得备份更加简单。
4.各节点组成对等的网络结构,某些节点出现故障时会自动分配其他节点代替其进行工作。
四,ES和关系型数据库
ElasticSearch与关系型数据库的相似:


1.一个ES集群中可以有多个索引库(数据库),每个索引又包含了很多类型(表),类型中包含了很多文档(行),每个文档又包含了很多字段(列)。
2.传统数据库为特定的列增加一个索引,例如B-Tree来加快查询效率,ES和Lucene使用倒排索引(简单理解:把列当做key,行键当做内容存储)的数据结构来加快查询效率。
3.倒排索引源于实际应用中需要根据属性的值来查找记录。这种索引表中的每一项都包括一个属性值和具有该属性值的各记录的地址。由于不是由记录来确定属性值,而是由属性值来确定记录的位置,因而称为倒排索引(inverted index)。
五,ES部署
5.1 下载地址
https://www.elastic.co/downloads/
5.2 配置
我这边是三台节点node01,node02,node03三台节点,全部安装
下载解压后进入到config目录下,修改 elasticsearch.yml文件
a)Cluster.name: mycluster (同一集群要一样)
b)Node.name:node01(另外两节点分别是 node02 node03) (同一集群要不一样)
c)Network.Host: 192.168.150.101 (这里不能写127.0.0.1)
d)防止脑裂的配置
discovery.zen.ping.multicast.enabled: false //禁用广播模式
discovery.zen.ping_timeout: 120s
client.transport.ping_timeout: 60s
<!-- 配置集群播送地址 -->
discovery.zen.ping.unicast.hosts: ["192.168.150.101","192.168.150.102", "192.168.150.103"]
5.3 启动
可以直接到安装目录bin下启动,我这边配置了环境变量


启动命令:
elasticsearch(三台启动,自动选举主节点)
elasticserrch -d (后台运行)
这里如果是root用户的话,会无法启动
新建用户
useradd wcb
给用户设置密码
passwd wcb
设置elasticsearch文件的权限
chown -R wcb:wcb /home/elasticsearch-2.4.5/ ##-R表示递归设置权限(子文件也设置)
设置完切换到 wcb用户执行
su wcb
重新启动即可
5.4 访问
注意命令行显示有, cluster-service start 才证明初始化成功


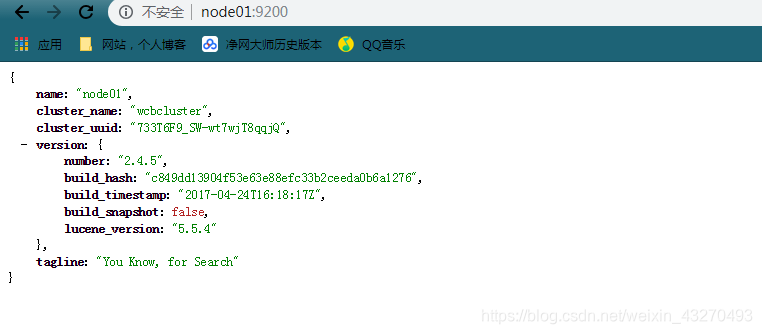
node01:9200(我在window配置了host,没配置直接用ip地址)

六,REST简介
REST(Resource Representational state Transfer),简单的说就是资源在网络中以某种形式进行状态转移。
Resource: 资源,即数据。
Representational:某种表现形式,比如用JSON,XMl,JPEG等
State Transfer : 状态变化,通过HTTP动词实现
它一种软件架构风格,而不是标准,只是提供了一组设计原则和约束条件。它主要用于客户端和服务器交互类的软件。基于这个风格设计的软件可以更简洁,更有层次,更易于实现缓存等机制。
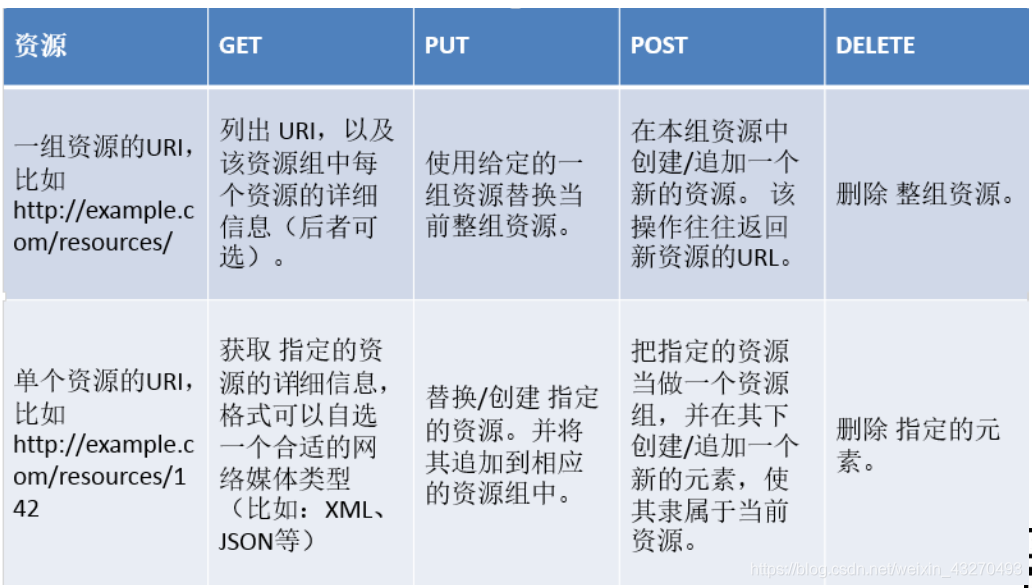
6.1 REST操作类型
---- GET 获取对象的当前状态
---- POST 创建对象
---- PUT 改变对象的状态
---- DELETE 删除对象
---- HEAD 获取头信息
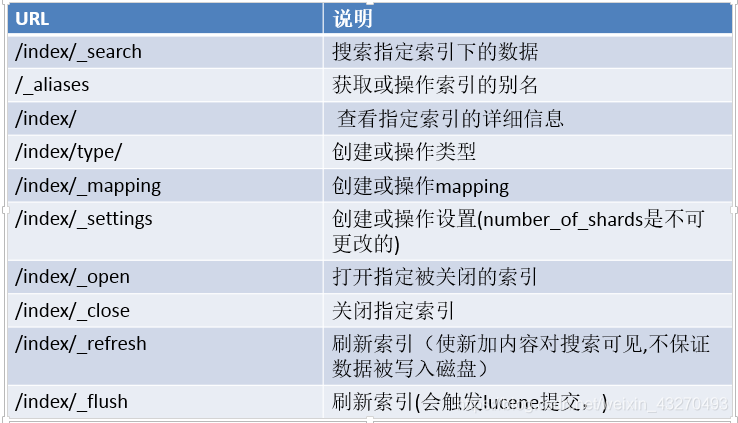
6.2 ES内置的REST接口

七,CURL命令
-X 指定HTTP请求的方法
-HEAD GET POST PUT DELETE -d 指定要传输的数据
7.1 索引库的创建和删除
创建索引库
curl -XPUT http://192.168.150.101:9200/test/ ##索引库名为test
删除索引库
curl -XDELETE http://192.168.150.101:9200/test/
7.2 创建document
创建document -- PUT方式
curl -XPUT http://192.168.150.101:9200/test/employee/1 -d '{
"first_name" : "john",
"last_name" : "smith",
"age" : 25,
"about" : "I love to go rock climbing",
"address": "shanghai"
}'
## 创建一个类型(type)为employee的document
POST方式
curl -XPOST http://192.168.150.101:9200/test/employee -d '{
"first_name" : "wcb01",
"last_name" : "heihei",
"age" : 20,
"about" : "I love qiaodaima"
}'
POST方式创建document时可以不指定id,会随机生成id(PUT方式不支持)
注意事项:
索引库的名称必须要全部小写,不能以下划线开头,也不能包括逗号
如果没有明确指定索引数据的ID,那么es会自动随机的生成一个ID,这时需要使用POST方式,PUT方式会报错。
7.3 更新document
PUT,全局更新,之前有的字段,如果更新时没有,就会删除
curl -XPUT http://192.168.150.101:9200/test/employee/1 -d '
{
"first_name" : "god bin",
"last_name" : "pang",
"age" : 38,
"about" : "I love to go rock climbing",
"address": "shanghai"
}'
POST,局部更新,没有的不删除,新增的添加
curl -XPOST http://192.168.150.101:9200/test/employee/1/_update -d '
{
"doc":{
"city":"beijing",
"sex":"male",
"age":30
}
}'
注意:PUT和POST都可以对文档进行更新,如果指定ID的文档已经存在,则对文档进行更新操作
执行更新操作的时候
— ES首先会将旧的文档标记为删除状态
— 然后添加新的文档
— 旧的文档不会即刻消息,但是你无法访问
— ES会在你继续添加更多数据的时候在后台轻量已经标记为删除的文档记录
这点和HBase中更新数据一样(Hbase中是在compaction时删除低版本数据)
7.4 普通查询索引
curl -XGET http://192.168.150.101:9200/test/employee/1?pretty ##pretty美化格式
curl加 -i 参数,这样你可以得到反馈文件
curl -i -XGET http://192.168.150.101:9200/test/employee/1?pretty
检索文档中的一部分,如果只需要显示指定字段
curl -i -XGET http://192.168.150.101:9200/test/employee/1?_source=sex,age ## 只查询 sex和age这两个字段
如果只需要source的数据
curl -XGET http://192.168.150.101:9200/test/employee/1?_source?pretty
查询所有
curl -XGET http://192.168.150.101:9200/test/employee/_search?pretty
## 查询employee类型中所有数据
根据条件进行查询
curl -XGET http://192.168.150.101:9200/test/employee/_search?q=first_name:wcb ## 查询first_name为 wcb的文档
7.5 DSL查询
curl -XGET http://localhost:9200/test/employee/_search?pretty -d '{
"query":
{"match":
{"last_name":"smith"}
}
}' ## 查询 last_name 值为 smith的文档
对多个filed进行条件查询 multi_match
curl -XGET http://192.168.150.101:9200/test/employee/_search?pretty -d '
{
"query":
{"multi_match":
{
"query":"haha",
"fields":["last_name","first_name"]
}
}
}' ## 对多个字段查询匹配,一个满足即可 last_name和first_name任意一个值为 haha即可命中
复合查询
must —> and
must_not —> not
should —> OR (对单个条件过滤时,和MUST一样)
查询first_name是 wcb 切 age是 20的文档
curl -XGET http://192.168.150.101:9200/test/employee/_search?pretty -d '
{
"query":
{"bool" :
{
"must" :
{"match":
{"first_name":"wcb"}
},
"must" :
{"match":
{"age":20}
}
}
}
}'
查询first_name为wcb01的,并且年龄不在20岁到30岁之间的
curl -XGET http://192.168.150.101:9200/test/employee/_search?pretty -d '
{
"query":
{"bool" :
{
"must" :
{"term" :
{ "first_name" : "wcb01" }
}
,
"must" :
{"range":
{"age" : { "from" : 30, "to" : 40 }
}
}
}
}
}'
7.6 删除文档
curl -XDELETE http://192.168.150.101:9200/test/employee/1?pretty
如果文档存在,es会返回200 ok的状态码,found属性值为 true,_version属性的值+1
不存在,found属性值为false,但是_version属性的值依然会+1,这个就是内部管理的一部分,它保证了我们在多个节点间的不同操作的顺序都被正确标记了
删除一个文档也不会立即生效,它只是被标记成已删除。 Elasticsearch将会在你之后添加更多索引的时候才会在后台进行删除内容的清理
八,ElasticSearch插件安装
8.1 Head
如果只是通过命令行方式去操作ES,未免太过麻烦,而且不过人性化。Head可以完美的帮我们快速的学习和使用ES。
单台安装即可
到ES安装目录bin下执命令
./plugin install mobz/elasticsearch-head


安装后启动elasticSearch,访问安装节点ip:9200/_plugin/head
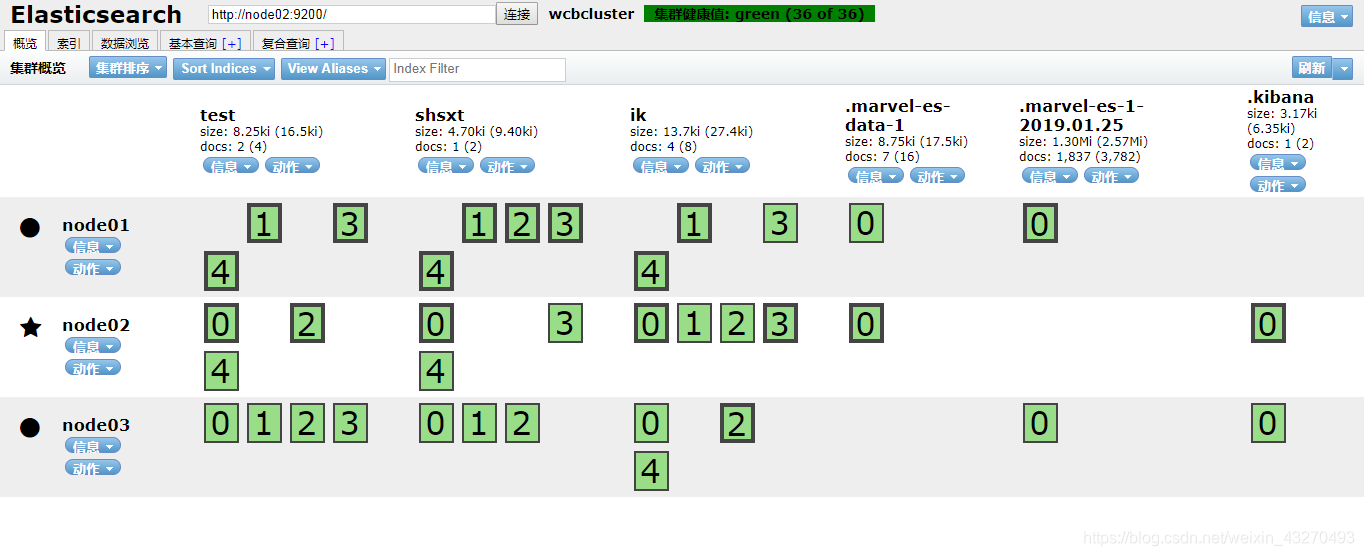

可以看到一个索引库默认分为5个切片,并且分布在不同的节点上(负载均衡,高可靠),之后详细介绍。
8.2 Kibana
它是一个基于浏览器页面的ES前端展示工具,是为ES提供日志分析的web接口,可用它对日志进行高效的搜索、可视化、分析等操作。
命令安装方式官网地址:https://www.elastic.co/guide/cn/kibana/current/installing_plugins.html
我这边是下载安装包安装,省略上传解压步骤
8.2.1 配置
到kibana安装目录config下,编辑kibana.yml文件,配置elasticsearch.url参数即可,我这里填的是3台节点中的其中一台


这里配置完之后,要想通过kibana查看elasticsearch集群的状态还需要安装一个marvel插件。
8.3 Marval
Marvel插件可以帮助使用者监控elasticsearch的运行状态,不过这个插件需要license。安装完license后可以安装marvel的 agent,agent会收集elasticsearch的运行状态。
8.3.1 license安装
三台虚拟机都要安装这个插件,且是安装在elasticsearc_home目录里。
到ES安装目录bin下,执行以下命令(三台节点)
./plugin install license
8.3.2 marval-agent安装
同样三台虚拟机都要安装,这样才能收集每个elasticsearch节点的状态信息。
到ES安装目录bin下,执行以下命令(三台节点)
./plugin install marval-agent
以上两个插件安装完,到ES安装目录下 plugins 可以看到以下两个文件夹


8.3.3 marval安装
在安装kibana插件的虚拟机上安装marvel,其中工作流程为: marvel-agent代理收集elasticsearch上的状态信息,然后发送给 kibana里的marvel,最后展示出来。执行命令:
kibana安装路径/bin/kibana plugin --install elasticsearch/marvel/latest


等待 几分钟即可… 这个比较慢
8.3.4 启动elasticsearch
三台es都启动,命令es_home/bin/elasticsearch
8.3.5 启动kibana
在安装kibana的虚拟机上启动
kibana_home/bin/kibana
8.3.6 验证kibana
访问kibana所在的的虚拟机 ip:5601/app/mavel

8.4 中文分词器集成
8.4.1 下载
从地址https://github.com/medcl/elasticsearch-analysis-ik 下载elasticsearch中文分词器
8.4.2 安装插件
在安装好的elasticsearch中在plugins目录下新建ik目录,将此zip包拷贝到ik目录下,将权限修改为elasticsearch启动用户的权限。通过unzip命令解压缩:
unzip elasticsearch-analysis-ik-1.8.0.zip
解压后查看 得到解压后的结果

8.4.3 重启elasticsearch集群
8.4.4 分词器的使用
1.创建索引库
curl -XPUT http://node02:9200/ik
2.设置mapping
curl -XPOST http://node02:9200/ik/ikType/_mapping -d'{
"properties": {
"content": {
"type": "string",
"index":"analyzed",
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word"
}
}
}'
3.插入数据
curl -XPOST http://node02:9200/ik/ikType/1 -d'
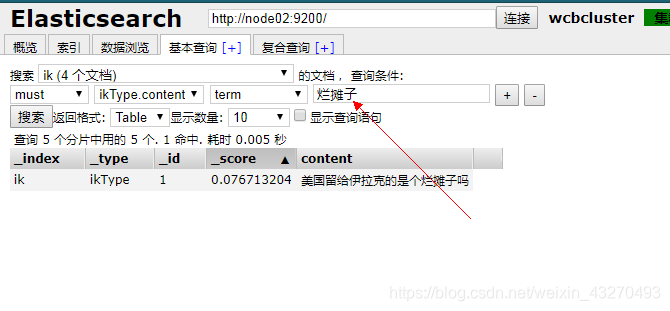
{"content":"美国留给伊拉克的是个烂摊子吗"}'
curl -XPOST http://node02:9200/ik/ikType/2 -d'
{"content":"公安部:各地校车将享最高路权"}'
curl -XPOST http://node02:9200/ik/ikType/3 -d'
{"content":"中韩渔警冲突调查:韩警平均每天扣1艘中国渔船"}'
curl -XPOST http://node02:9200/ik/ikType/4 -d'
{"content":"中国驻洛杉矶领事馆遭亚裔男子枪击 嫌犯已自首"}'
4.查询